 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMSSinger: Realistic-Music-Score based Singing Voice Synthesis
May 18, 2023We are interested in a challenging task, Realistic-Music-Score based Singing Voice Synthesis (RMS-SVS). RMS-SVS aims to generate high-quality singing voices given realistic music scores with different note types (grace, slur, rest, etc.). Though significant progress has been achieved, recent singing voice synthesis (SVS) methods are limited to fine-grained music scores, which require a complicated data collection pipeline with time-consuming manual annotation to align music notes with phonemes. Furthermore, these manual annotation destroys the regularity of note durations in music scores, making fine-grained music scores inconvenient for composing. To tackle these challenges, we propose RMSSinger, the first RMS-SVS method, which takes realistic music scores as input, eliminating most of the tedious manual annotation and avoiding the aforementioned inconvenience. Note that music scores are based on words rather than phonemes, in RMSSinger, we introduce word-level modeling to avoid the time-consuming phoneme duration annotation and the complicated phoneme-level mel-note alignment. Furthermore, we propose the first diffusion-based pitch modeling method, which ameliorates the naturalness of existing pitch-modeling methods. To achieve these, we collect a new dataset containing realistic music scores and singing voices according to these realistic music scores from professional singers. Extensive experiments on the dataset demonstrate the effectiveness of our methods. Audio samples are available at https://rmssinger.github.io/.
VarietySound: Timbre-Controllable Video to Sound Generation via Unsupervised Information Disentanglement
Nov 19, 2022Video to sound generation aims to generate realistic and natural sound given a video input. However, previous video-to-sound generation methods can only generate a random or average timbre without any controls or specializations of the generated sound timbre, leading to the problem that people cannot obtain the desired timbre under these methods sometimes. In this paper, we pose the task of generating sound with a specific timbre given a video input and a reference audio sample. To solve this task, we disentangle each target sound audio into three components: temporal information, acoustic information, and background information. We first use three encoders to encode these components respectively: 1) a temporal encoder to encode temporal information, which is fed with video frames since the input video shares the same temporal information as the original audio; 2) an acoustic encoder to encode timbre information, which takes the original audio as input and discards its temporal information by a temporal-corrupting operation; and 3) a background encoder to encode the residual or background sound, which uses the background part of the original audio as input. To make the generated result achieve better quality and temporal alignment, we also adopt a mel discriminator and a temporal discriminator for the adversarial training. Our experimental results on the VAS dataset demonstrate that our method can generate high-quality audio samples with good synchronization with events in video and high timbre similarity with the reference audio.
ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech
Jul 13, 2022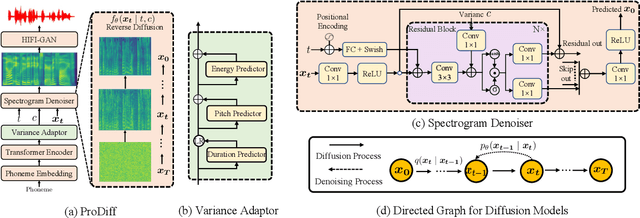

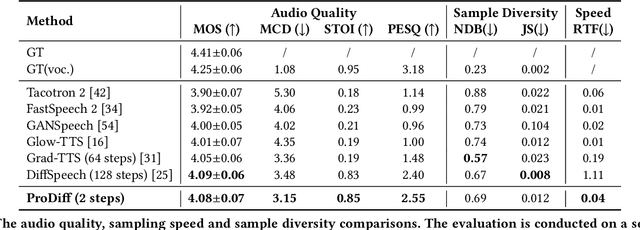
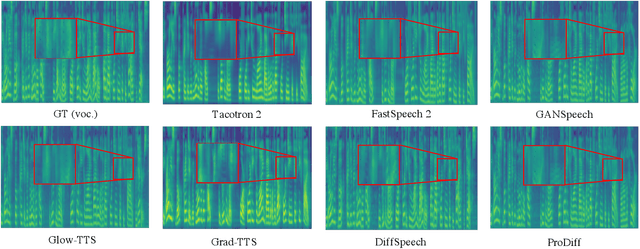
Denoising diffusion probabilistic models (DDPMs) have recently achieved leading performances in many generative tasks. However, the inherited iterative sampling process costs hinder their applications to text-to-speech deployment. Through the preliminary study on diffusion model parameterization, we find that previous gradient-based TTS models require hundreds or thousands of iterations to guarantee high sample quality, which poses a challenge for accelerating sampling. In this work, we propose ProDiff, on progressive fast diffusion model for high-quality text-to-speech. Unlike previous work estimating the gradient for data density, ProDiff parameterizes the denoising model by directly predicting clean data to avoid distinct quality degradation in accelerating sampling. To tackle the model convergence challenge with decreased diffusion iterations, ProDiff reduces the data variance in the target site via knowledge distillation. Specifically, the denoising model uses the generated mel-spectrogram from an N-step DDIM teacher as the training target and distills the behavior into a new model with N/2 steps. As such, it allows the TTS model to make sharp predictions and further reduces the sampling time by orders of magnitude. Our evaluation demonstrates that ProDiff needs only 2 iterations to synthesize high-fidelity mel-spectrograms, while it maintains sample quality and diversity competitive with state-of-the-art models using hundreds of steps. ProDiff enables a sampling speed of 24x faster than real-time on a single NVIDIA 2080Ti GPU, making diffusion models practically applicable to text-to-speech synthesis deployment for the first time. Our extensive ablation studies demonstrate that each design in ProDiff is effective, and we further show that ProDiff can be easily extended to the multi-speaker setting. Audio samples are available at \url{https://ProDiff.github.io/.}
GenerSpeech: Towards Style Transfer for Generalizable Out-Of-Domain Text-to-Speech Synthesis
May 15, 2022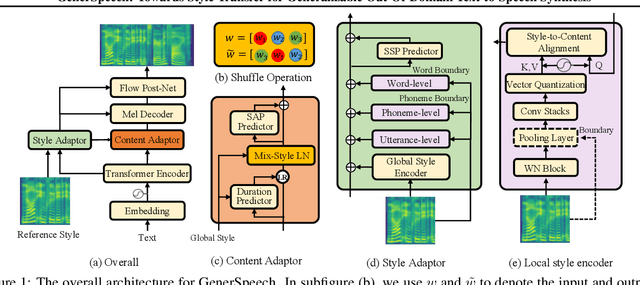
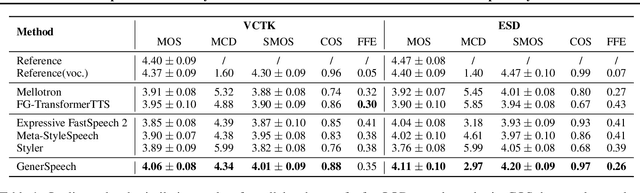
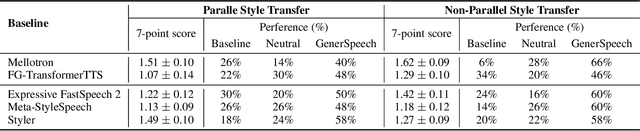
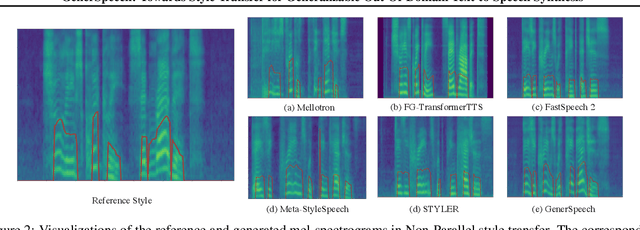
Style transfer for out-of-domain (OOD) speech synthesis aims to generate speech samples with unseen style (e.g., speaker identity, emotion, and prosody) derived from an acoustic reference, while facing the following challenges: 1) The highly dynamic style features in expressive voice are difficult to model and transfer; and 2) the TTS models should be robust enough to handle diverse OOD conditions that differ from the source data. This paper proposes GenerSpeech, a text-to-speech model towards high-fidelity zero-shot style transfer of OOD custom voice. GenerSpeech decomposes the speech variation into the style-agnostic and style-specific parts by introducing two components: 1) a multi-level style adaptor to efficiently model a large range of style conditions, including global speaker and emotion characteristics, and the local (utterance, phoneme, and word-level) fine-grained prosodic representations; and 2) a generalizable content adaptor with Mix-Style Layer Normalization to eliminate style information in the linguistic content representation and thus improve model generalization. Our evaluations on zero-shot style transfer demonstrate that GenerSpeech surpasses the state-of-the-art models in terms of audio quality and style similarity. The extension studies to adaptive style transfer further show that GenerSpeech performs robustly in the few-shot data setting. Audio samples are available at \url{https://GenerSpeech.github.io/}
Multi-Singer: Fast Multi-Singer Singing Voice Vocoder With A Large-Scale Corpus
Dec 20, 2021
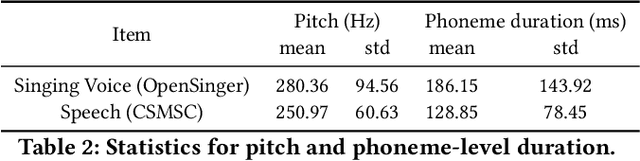
High-fidelity multi-singer singing voice synthesis is challenging for neural vocoder due to the singing voice data shortage, limited singer generalization, and large computational cost. Existing open corpora could not meet requirements for high-fidelity singing voice synthesis because of the scale and quality weaknesses. Previous vocoders have difficulty in multi-singer modeling, and a distinct degradation emerges when conducting unseen singer singing voice generation. To accelerate singing voice researches in the community, we release a large-scale, multi-singer Chinese singing voice dataset OpenSinger. To tackle the difficulty in unseen singer modeling, we propose Multi-Singer, a fast multi-singer vocoder with generative adversarial networks. Specifically, 1) Multi-Singer uses a multi-band generator to speed up both training and inference procedure. 2) to capture and rebuild singer identity from the acoustic feature (i.e., mel-spectrogram), Multi-Singer adopts a singer conditional discriminator and conditional adversarial training objective. 3) to supervise the reconstruction of singer identity in the spectrum envelopes in frequency domain, we propose an auxiliary singer perceptual loss. The joint training approach effectively works in GANs for multi-singer voices modeling. Experimental results verify the effectiveness of OpenSinger and show that Multi-Singer improves unseen singer singing voices modeling in both speed and quality over previous methods. The further experiment proves that combined with FastSpeech 2 as the acoustic model, Multi-Singer achieves strong robustness in the multi-singer singing voice synthesis pipeline. Samples are available at https://Multi-Singer.github.io/
SingGAN: Generative Adversarial Network For High-Fidelity Singing Voice Generation
Oct 26, 2021

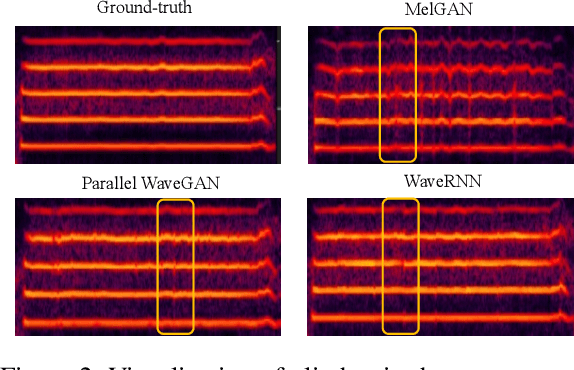

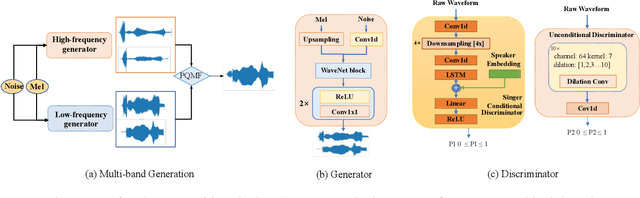
High-fidelity singing voice synthesis is challenging for neural vocoders due to extremely long continuous pronunciation, high sampling rate and strong expressiveness. Existing neural vocoders designed for text-to-speech cannot directly be applied to singing voice synthesis because they result in glitches in the generated spectrogram and poor high-frequency reconstruction. To tackle the difficulty of singing modeling, in this paper, we propose SingGAN, a singing voice vocoder with generative adversarial network. Specifically, 1) SingGAN uses source excitation to alleviate the glitch problem in the spectrogram; and 2) SingGAN adopts multi-band discriminators and introduces frequency-domain loss and sub-band feature matching loss to supervise high-frequency reconstruction. To our knowledge, SingGAN is the first vocoder designed towards high-fidelity multi-speaker singing voice synthesis. Experimental results show that SingGAN synthesizes singing voices with much higher quality (0.41 MOS gains) over the previous method. Further experiments show that combined with FastSpeech~2 as an acoustic model, SingGAN achieves high robustness in the singing voice synthesis pipeline and also performs well in speech synthesis.
EMOVIE: A Mandarin Emotion Speech Dataset with a Simple Emotional Text-to-Speech Model
Jun 17, 2021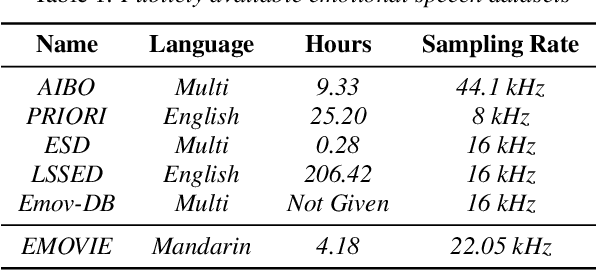
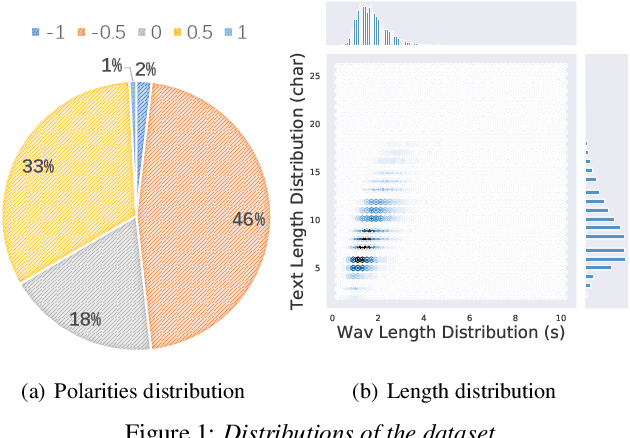

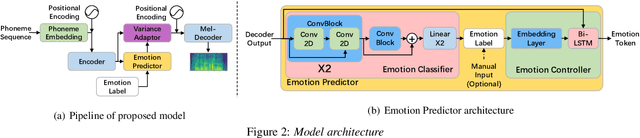
Recently, there has been an increasing interest in neural speech synthesis. While the deep neural network achieves the state-of-the-art result in text-to-speech (TTS) tasks, how to generate a more emotional and more expressive speech is becoming a new challenge to researchers due to the scarcity of high-quality emotion speech dataset and the lack of advanced emotional TTS model. In this paper, we first briefly introduce and publicly release a Mandarin emotion speech dataset including 9,724 samples with audio files and its emotion human-labeled annotation. After that, we propose a simple but efficient architecture for emotional speech synthesis called EMSpeech. Unlike those models which need additional reference audio as input, our model could predict emotion labels just from the input text and generate more expressive speech conditioned on the emotion embedding. In the experiment phase, we first validate the effectiveness of our dataset by an emotion classification task. Then we train our model on the proposed dataset and conduct a series of subjective evaluations. Finally, by showing a comparable performance in the emotional speech synthesis task, we successfully demonstrate the ability of the proposed model.