 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceVista: All-Scale Visual Spatial Reasoning from mm to km
Oct 10, 2025With the current surge in spatial reasoning explorations, researchers have made significant progress in understanding indoor scenes, but still struggle with diverse applications such as robotics and autonomous driving. This paper aims to advance all-scale spatial reasoning across diverse scenarios by tackling two key challenges: 1) the heavy reliance on indoor 3D scans and labor-intensive manual annotations for dataset curation; 2) the absence of effective all-scale scene modeling, which often leads to overfitting to individual scenes. In this paper, we introduce a holistic solution that integrates a structured spatial reasoning knowledge system, scale-aware modeling, and a progressive training paradigm, as the first attempt to broaden the all-scale spatial intelligence of MLLMs to the best of our knowledge. Using a task-specific, specialist-driven automated pipeline, we curate over 38K video scenes across 5 spatial scales to create SpaceVista-1M, a dataset comprising approximately 1M spatial QA pairs spanning 19 diverse task types. While specialist models can inject useful domain knowledge, they are not reliable for evaluation. We then build an all-scale benchmark with precise annotations by manually recording, retrieving, and assembling video-based data. However, naive training with SpaceVista-1M often yields suboptimal results due to the potential knowledge conflict. Accordingly, we introduce SpaceVista-7B, a spatial reasoning model that accepts dense inputs beyond semantics and uses scale as an anchor for scale-aware experts and progressive rewards. Finally, extensive evaluations across 5 benchmarks, including our SpaceVista-Bench, demonstrate competitive performance, showcasing strong generalization across all scales and scenarios. Our dataset, model, and benchmark will be released on https://peiwensun2000.github.io/mm2km .
ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing
Jun 26, 2025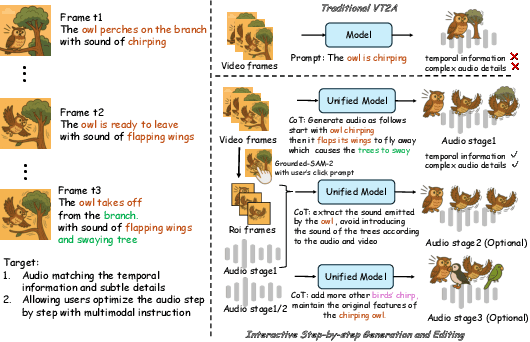
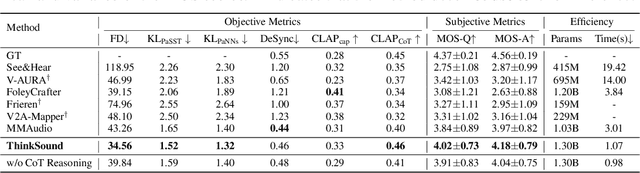
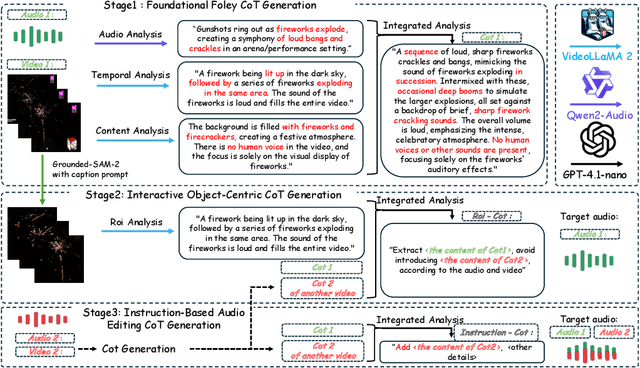
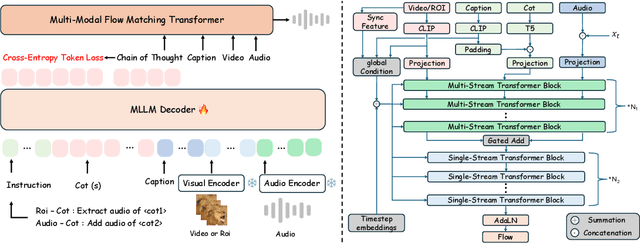
While end-to-end video-to-audio generation has greatly improved, producing high-fidelity audio that authentically captures the nuances of visual content remains challenging. Like professionals in the creative industries, such generation requires sophisticated reasoning about items such as visual dynamics, acoustic environments, and temporal relationships. We present \textbf{ThinkSound}, a novel framework that leverages Chain-of-Thought (CoT) reasoning to enable stepwise, interactive audio generation and editing for videos. Our approach decomposes the process into three complementary stages: foundational foley generation that creates semantically coherent soundscapes, interactive object-centric refinement through precise user interactions, and targeted editing guided by natural language instructions. At each stage, a multimodal large language model generates contextually aligned CoT reasoning that guides a unified audio foundation model. Furthermore, we introduce \textbf{AudioCoT}, a comprehensive dataset with structured reasoning annotations that establishes connections between visual content, textual descriptions, and sound synthesis. Experiments demonstrate that ThinkSound achieves state-of-the-art performance in video-to-audio generation across both audio metrics and CoT metrics and excels in out-of-distribution Movie Gen Audio benchmark. The demo page is available at https://ThinkSound-Demo.github.io.
OmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025
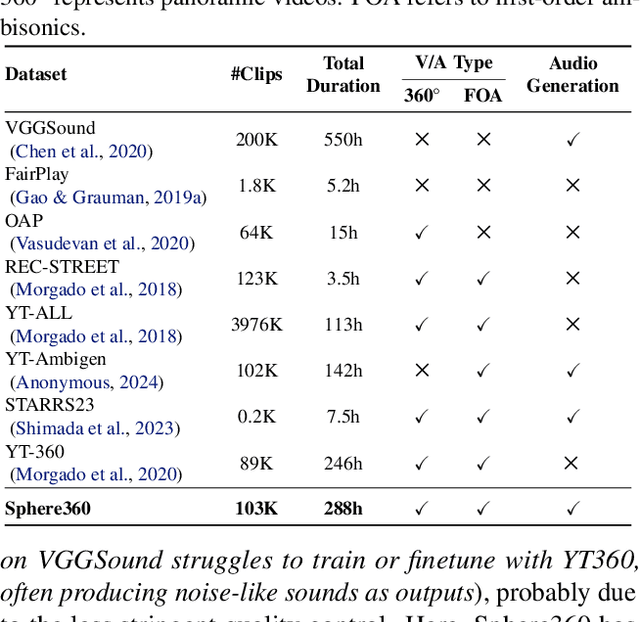
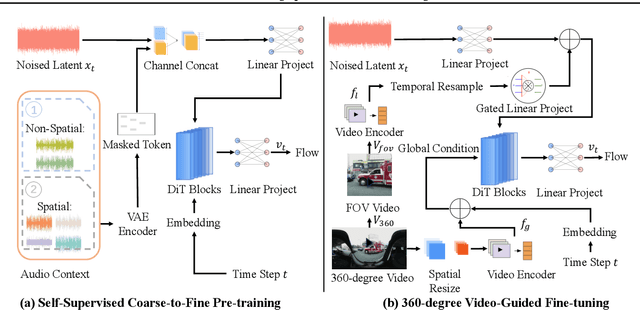
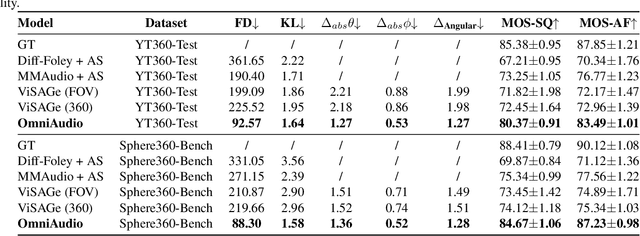
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024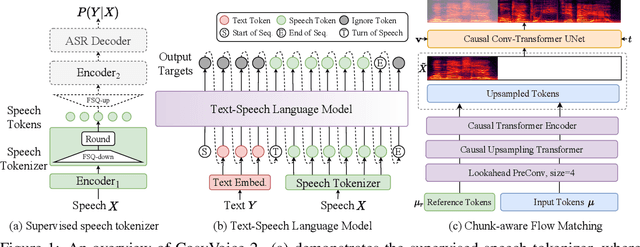

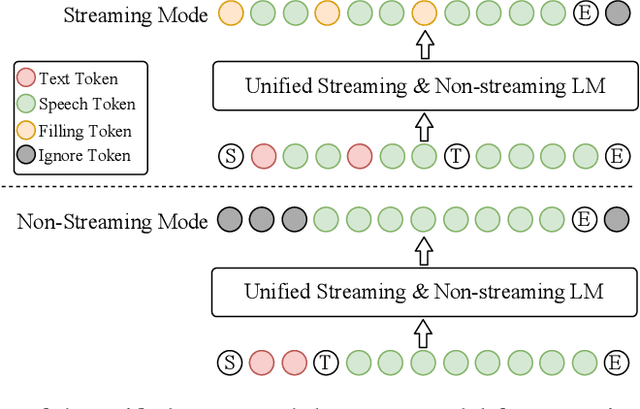

In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
FlashAudio: Rectified Flows for Fast and High-Fidelity Text-to-Audio Generation
Oct 16, 2024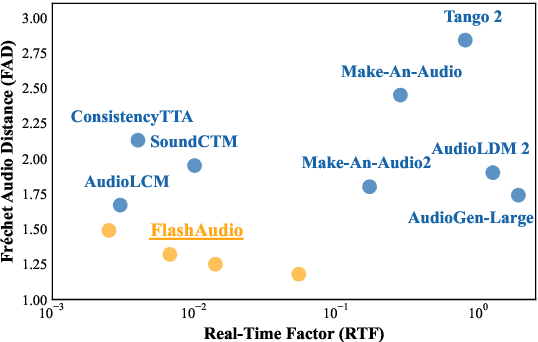


Recent advancements in latent diffusion models (LDMs) have markedly enhanced text-to-audio generation, yet their iterative sampling processes impose substantial computational demands, limiting practical deployment. While recent methods utilizing consistency-based distillation aim to achieve few-step or single-step inference, their one-step performance is constrained by curved trajectories, preventing them from surpassing traditional diffusion models. In this work, we introduce FlashAudio with rectified flows to learn straight flow for fast simulation. To alleviate the inefficient timesteps allocation and suboptimal distribution of noise, FlashAudio optimizes the time distribution of rectified flow with Bifocal Samplers and proposes immiscible flow to minimize the total distance of data-noise pairs in a batch vias assignment. Furthermore, to address the amplified accumulation error caused by the classifier-free guidance (CFG), we propose Anchored Optimization, which refines the guidance scale by anchoring it to a reference trajectory. Experimental results on text-to-audio generation demonstrate that FlashAudio's one-step generation performance surpasses the diffusion-based models with hundreds of sampling steps on audio quality and enables a sampling speed of 400x faster than real-time on a single NVIDIA 4090Ti GPU.
Both Ears Wide Open: Towards Language-Driven Spatial Audio Generation
Oct 14, 2024



Recently, diffusion models have achieved great success in mono-channel audio generation. However, when it comes to stereo audio generation, the soundscapes often have a complex scene of multiple objects and directions. Controlling stereo audio with spatial contexts remains challenging due to high data costs and unstable generative models. To the best of our knowledge, this work represents the first attempt to address these issues. We first construct a large-scale, simulation-based, and GPT-assisted dataset, BEWO-1M, with abundant soundscapes and descriptions even including moving and multiple sources. Beyond text modality, we have also acquired a set of images and rationally paired stereo audios through retrieval to advance multimodal generation. Existing audio generation models tend to generate rather random and indistinct spatial audio. To provide accurate guidance for latent diffusion models, we introduce the SpatialSonic model utilizing spatial-aware encoders and azimuth state matrices to reveal reasonable spatial guidance. By leveraging spatial guidance, our unified model not only achieves the objective of generating immersive and controllable spatial audio from text and image but also enables interactive audio generation during inference. Finally, under fair settings, we conduct subjective and objective evaluations on simulated and real-world data to compare our approach with prevailing methods. The results demonstrate the effectiveness of our method, highlighting its capability to generate spatial audio that adheres to physical rules.
MEDIC: Zero-shot Music Editing with Disentangled Inversion Control
Jul 18, 2024Text-guided diffusion models catalyze a paradigm shift in audio generation, facilitating the adaptability of source audio to conform to specific textual prompts. Recent advancements introduce inversion techniques, like DDIM inversion, to zero-shot editing, exploiting pre-trained diffusion models for audio modification. Nonetheless, our investigation exposes that DDIM inversion suffers from an accumulation of errors across each diffusion step, undermining its efficacy. And the lack of attention control hinders the fine-grained manipulations of music. To counteract these limitations, we introduce the \textit{Disentangled Inversion} technique, which is designed to disentangle the diffusion process into triple branches, thereby magnifying their individual capabilities for both precise editing and preservation. Furthermore, we propose the \textit{Harmonized Attention Control} framework, which unifies the mutual self-attention and cross-attention with an additional Harmonic Branch to achieve the desired composition and structural information in the target music. Collectively, these innovations comprise the \textit{Disentangled Inversion Control (DIC)} framework, enabling accurate music editing whilst safeguarding structural integrity. To benchmark audio editing efficacy, we introduce \textit{ZoME-Bench}, a comprehensive music editing benchmark hosting 1,100 samples spread across 10 distinct editing categories, which facilitates both zero-shot and instruction-based music editing tasks. Our method demonstrates unparalleled performance in edit fidelity and essential content preservation, outperforming contemporary state-of-the-art inversion techniques.
AudioLCM: Text-to-Audio Generation with Latent Consistency Models
Jun 01, 2024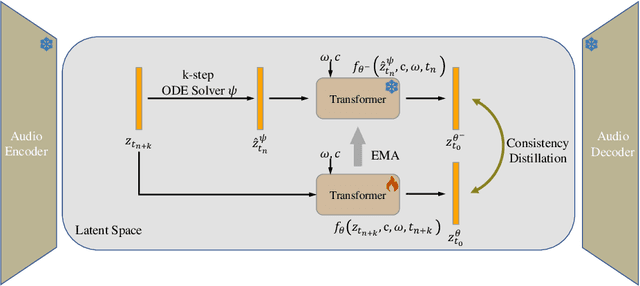
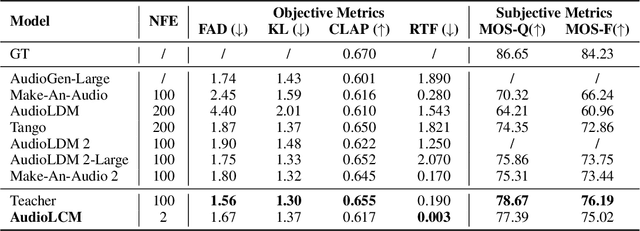
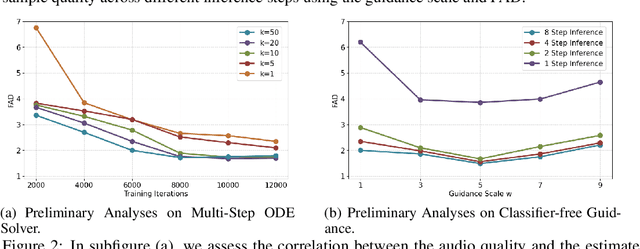
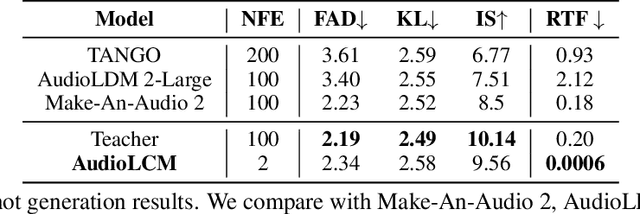
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
AV-TranSpeech: Audio-Visual Robust Speech-to-Speech Translation
May 24, 2023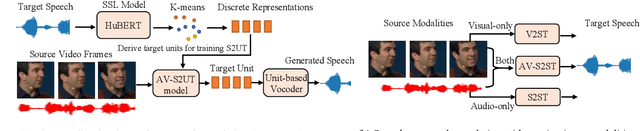
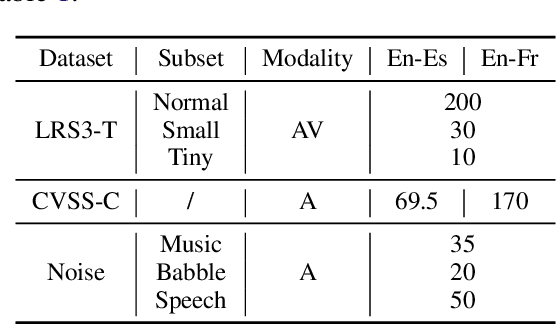
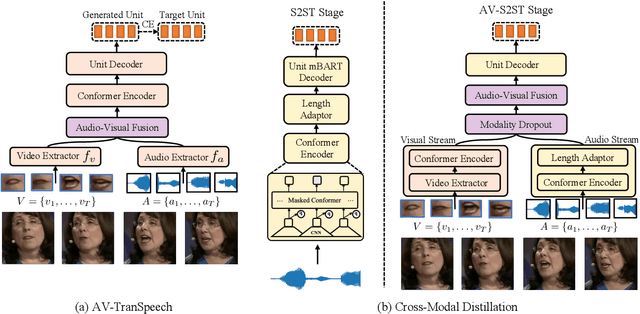
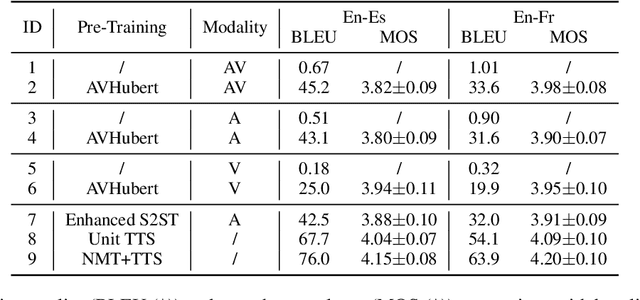
Direct speech-to-speech translation (S2ST) aims to convert speech from one language into another, and has demonstrated significant progress to date. Despite the recent success, current S2ST models still suffer from distinct degradation in noisy environments and fail to translate visual speech (i.e., the movement of lips and teeth). In this work, we present AV-TranSpeech, the first audio-visual speech-to-speech (AV-S2ST) translation model without relying on intermediate text. AV-TranSpeech complements the audio stream with visual information to promote system robustness and opens up a host of practical applications: dictation or dubbing archival films. To mitigate the data scarcity with limited parallel AV-S2ST data, we 1) explore self-supervised pre-training with unlabeled audio-visual data to learn contextual representation, and 2) introduce cross-modal distillation with S2ST models trained on the audio-only corpus to further reduce the requirements of visual data. Experimental results on two language pairs demonstrate that AV-TranSpeech outperforms audio-only models under all settings regardless of the type of noise. With low-resource audio-visual data (10h, 30h), cross-modal distillation yields an improvement of 7.6 BLEU on average compared with baselines. Audio samples are available at https://AV-TranSpeech.github.io
ViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer
May 22, 2023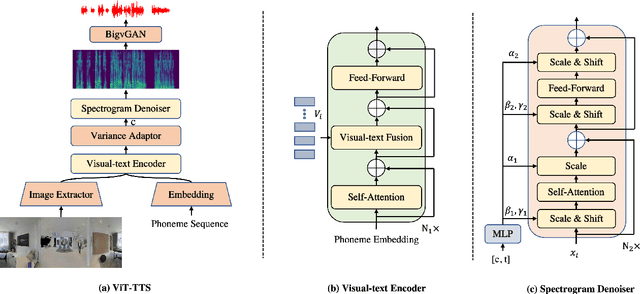
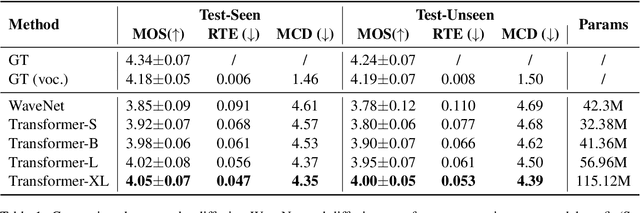

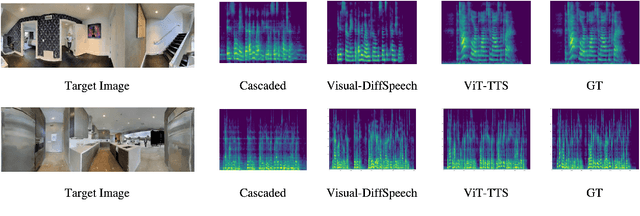
Text-to-speech(TTS) has undergone remarkable improvements in performance, particularly with the advent of Denoising Diffusion Probabilistic Models (DDPMs). However, the perceived quality of audio depends not solely on its content, pitch, rhythm, and energy, but also on the physical environment. In this work, we propose ViT-TTS, the first visual TTS model with scalable diffusion transformers. ViT-TTS complement the phoneme sequence with the visual information to generate high-perceived audio, opening up new avenues for practical applications of AR and VR to allow a more immersive and realistic audio experience. To mitigate the data scarcity in learning visual acoustic information, we 1) introduce a self-supervised learning framework to enhance both the visual-text encoder and denoiser decoder; 2) leverage the diffusion transformer scalable in terms of parameters and capacity to learn visual scene information. Experimental results demonstrate that ViT-TTS achieves new state-of-the-art results, outperforming cascaded systems and other baselines regardless of the visibility of the scene. With low-resource data (1h, 2h, 5h), ViT-TTS achieves comparative results with rich-resource baselines.~\footnote{Audio samples are available at \url{https://ViT-TTS.github.io/.}}