 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer
May 22, 2023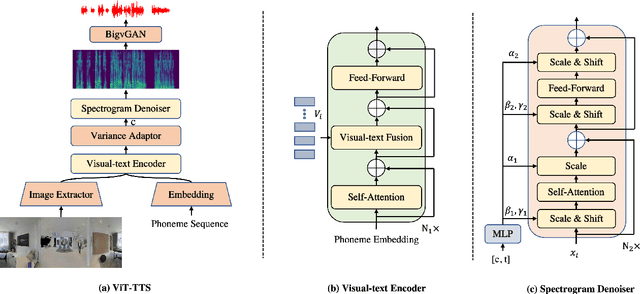
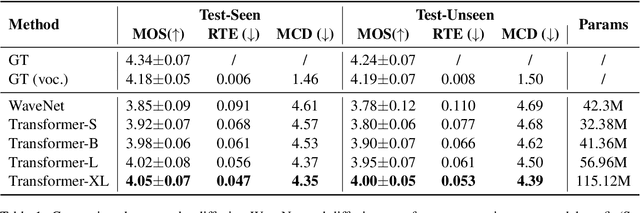

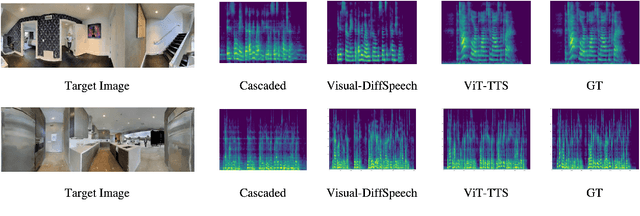
Text-to-speech(TTS) has undergone remarkable improvements in performance, particularly with the advent of Denoising Diffusion Probabilistic Models (DDPMs). However, the perceived quality of audio depends not solely on its content, pitch, rhythm, and energy, but also on the physical environment. In this work, we propose ViT-TTS, the first visual TTS model with scalable diffusion transformers. ViT-TTS complement the phoneme sequence with the visual information to generate high-perceived audio, opening up new avenues for practical applications of AR and VR to allow a more immersive and realistic audio experience. To mitigate the data scarcity in learning visual acoustic information, we 1) introduce a self-supervised learning framework to enhance both the visual-text encoder and denoiser decoder; 2) leverage the diffusion transformer scalable in terms of parameters and capacity to learn visual scene information. Experimental results demonstrate that ViT-TTS achieves new state-of-the-art results, outperforming cascaded systems and other baselines regardless of the visibility of the scene. With low-resource data (1h, 2h, 5h), ViT-TTS achieves comparative results with rich-resource baselines.~\footnote{Audio samples are available at \url{https://ViT-TTS.github.io/.}}
AntPivot: Livestream Highlight Detection via Hierarchical Attention Mechanism
Jun 10, 2022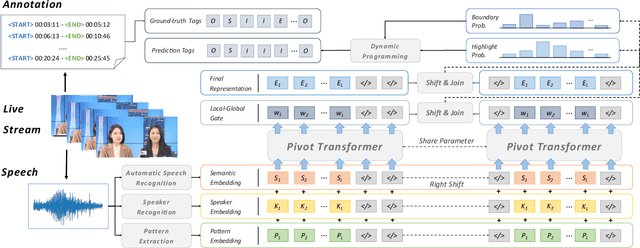

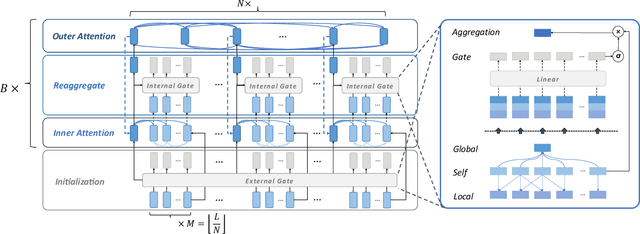

In recent days, streaming technology has greatly promoted the development in the field of livestream. Due to the excessive length of livestream records, it's quite essential to extract highlight segments with the aim of effective reproduction and redistribution. Although there are lots of approaches proven to be effective in the highlight detection for other modals, the challenges existing in livestream processing, such as the extreme durations, large topic shifts, much irrelevant information and so forth, heavily hamper the adaptation and compatibility of these methods. In this paper, we formulate a new task Livestream Highlight Detection, discuss and analyze the difficulties listed above and propose a novel architecture AntPivot to solve this problem. Concretely, we first encode the original data into multiple views and model their temporal relations to capture clues in a hierarchical attention mechanism. Afterwards, we try to convert the detection of highlight clips into the search for optimal decision sequences and use the fully integrated representations to predict the final results in a dynamic-programming mechanism. Furthermore, we construct a fully-annotated dataset AntHighlight to instantiate this task and evaluate the performance of our model. The extensive experiments indicate the effectiveness and validity of our proposed method.