 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025
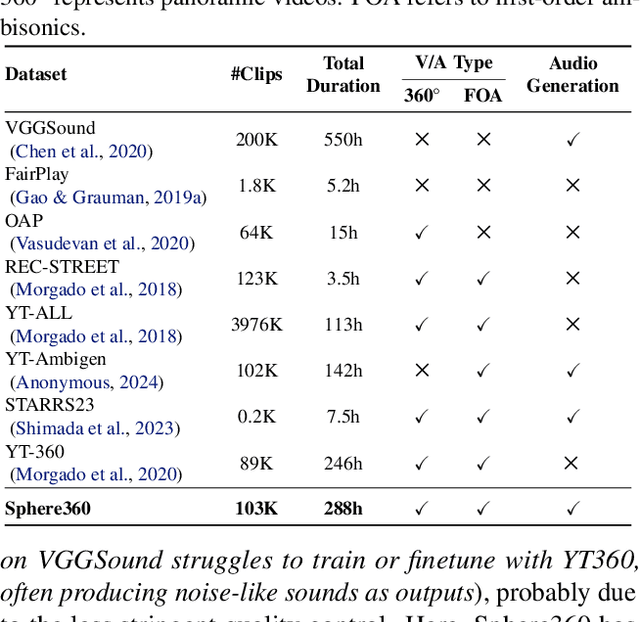
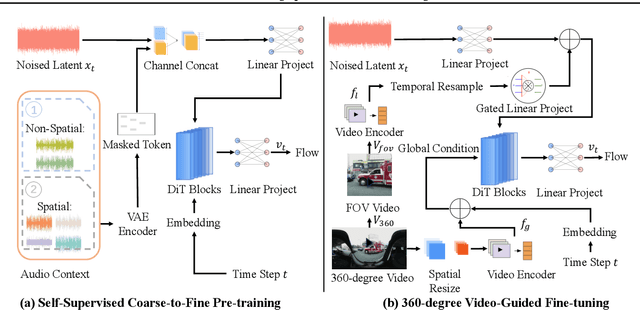
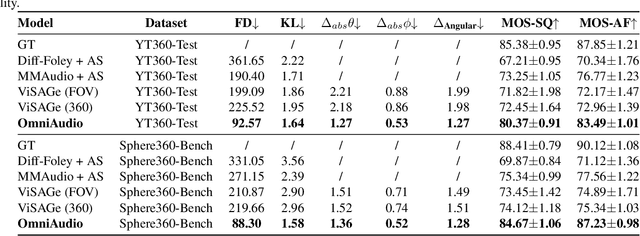
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
To Aggregate or Not? Learning with Separate Noisy Labels
Jun 14, 2022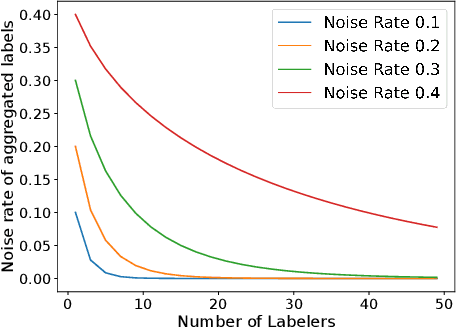
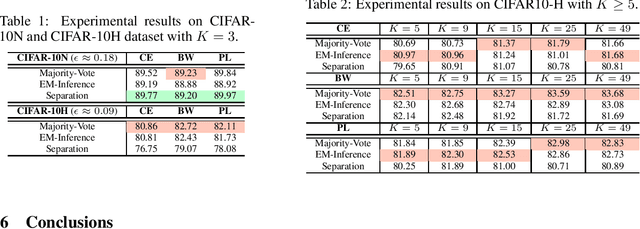
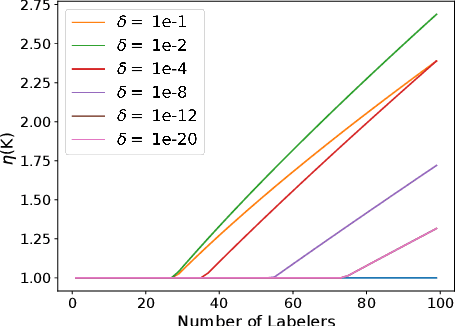
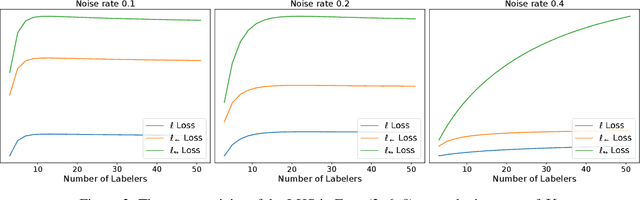
The rawly collected training data often comes with separate noisy labels collected from multiple imperfect annotators (e.g., via crowdsourcing). Typically one would first aggregate the separate noisy labels into one and apply standard training methods. The literature has also studied extensively on effective aggregation approaches. This paper revisits this choice and aims to provide an answer to the question of whether one should aggregate separate noisy labels into single ones or use them separately as given. We theoretically analyze the performance of both approaches under the empirical risk minimization framework for a number of popular loss functions, including the ones designed specifically for the problem of learning with noisy labels. Our theorems conclude that label separation is preferred over label aggregation when the noise rates are high, or the number of labelers/annotations is insufficient. Extensive empirical results validate our conclusion.
Interpretable Research Replication Prediction via Variational Contextual Consistency Sentence Masking
Mar 28, 2022

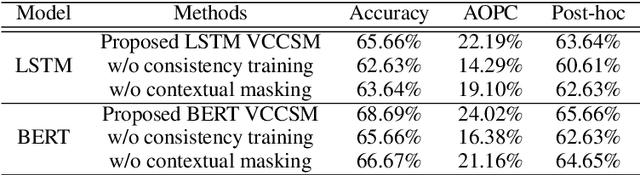

Research Replication Prediction (RRP) is the task of predicting whether a published research result can be replicated or not. Building an interpretable neural text classifier for RRP promotes the understanding of why a research paper is predicted as replicable or non-replicable and therefore makes its real-world application more reliable and trustworthy. However, the prior works on model interpretation mainly focused on improving the model interpretability at the word/phrase level, which are insufficient especially for long research papers in RRP. Furthermore, the existing methods cannot utilize a large size of unlabeled dataset to further improve the model interpretability. To address these limitations, we aim to build an interpretable neural model which can provide sentence-level explanations and apply weakly supervised approach to further leverage the large corpus of unlabeled datasets to boost the interpretability in addition to improving prediction performance as existing works have done. In this work, we propose the Variational Contextual Consistency Sentence Masking (VCCSM) method to automatically extract key sentences based on the context in the classifier, using both labeled and unlabeled datasets. Results of our experiments on RRP along with European Convention of Human Rights (ECHR) datasets demonstrate that VCCSM is able to improve the model interpretability for the long document classification tasks using the area over the perturbation curve and post-hoc accuracy as evaluation metrics.
Compressed Predictive Information Coding
Mar 03, 2022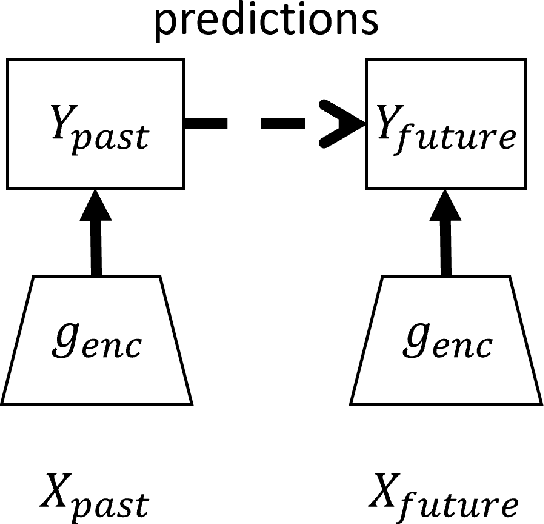
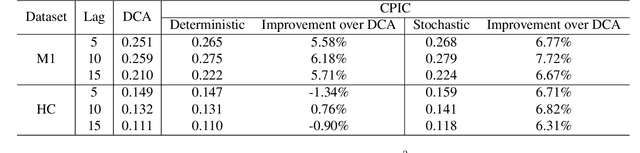

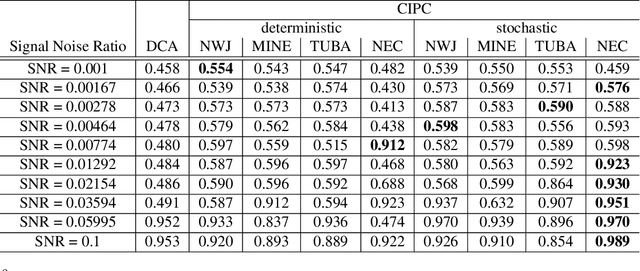
Unsupervised learning plays an important role in many fields, such as artificial intelligence, machine learning, and neuroscience. Compared to static data, methods for extracting low-dimensional structure for dynamic data are lagging. We developed a novel information-theoretic framework, Compressed Predictive Information Coding (CPIC), to extract useful representations from dynamic data. CPIC selectively projects the past (input) into a linear subspace that is predictive about the compressed data projected from the future (output). The key insight of our framework is to learn representations by minimizing the compression complexity and maximizing the predictive information in latent space. We derive variational bounds of the CPIC loss which induces the latent space to capture information that is maximally predictive. Our variational bounds are tractable by leveraging bounds of mutual information. We find that introducing stochasticity in the encoder robustly contributes to better representation. Furthermore, variational approaches perform better in mutual information estimation compared with estimates under a Gaussian assumption. We demonstrate that CPIC is able to recover the latent space of noisy dynamical systems with low signal-to-noise ratios, and extracts features predictive of exogenous variables in neuroscience data.
The Rich Get Richer: Disparate Impact of Semi-Supervised Learning
Oct 12, 2021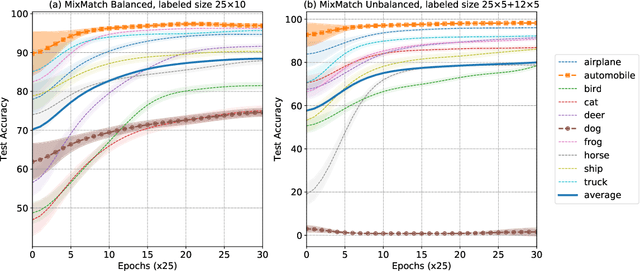

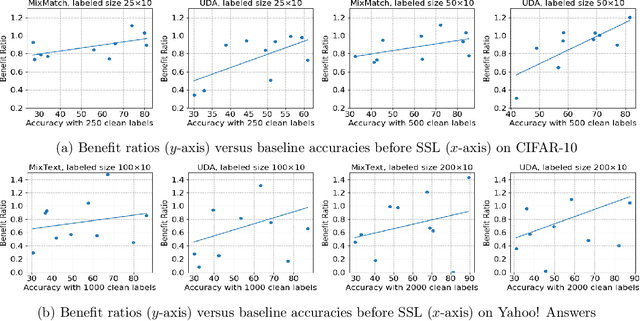

Semi-supervised learning (SSL) has demonstrated its potential to improve the model accuracy for a variety of learning tasks when the high-quality supervised data is severely limited. Although it is often established that the average accuracy for the entire population of data is improved, it is unclear how SSL fares with different sub-populations. Understanding the above question has substantial fairness implications when these different sub-populations are defined by the demographic groups we aim to treat fairly. In this paper, we reveal the disparate impacts of deploying SSL: the sub-population who has a higher baseline accuracy without using SSL (the ``rich" sub-population) tends to benefit more from SSL; while the sub-population who suffers from a low baseline accuracy (the ``poor" sub-population) might even observe a performance drop after adding the SSL module. We theoretically and empirically establish the above observation for a broad family of SSL algorithms, which either explicitly or implicitly use an auxiliary ``pseudo-label". Our experiments on a set of image and text classification tasks confirm our claims. We discuss how this disparate impact can be mitigated and hope that our paper will alarm the potential pitfall of using SSL and encourage a multifaceted evaluation of future SSL algorithms. Code is available at github.com/UCSC-REAL/Disparate-SSL.
Machine Truth Serum
Sep 28, 2019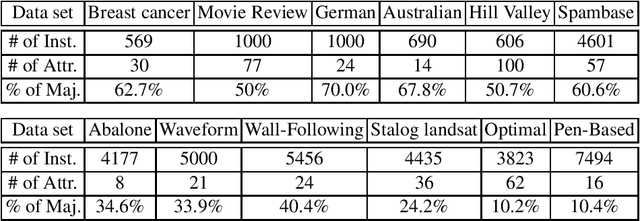
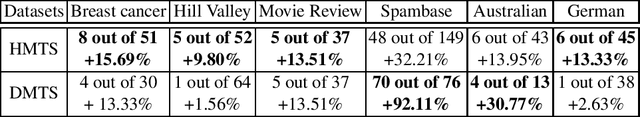


Wisdom of the crowd revealed a striking fact that the majority answer from a crowd is often more accurate than any individual expert. We observed the same story in machine learning--ensemble methods leverage this idea to combine multiple learning algorithms to obtain better classification performance. Among many popular examples is the celebrated Random Forest, which applies the majority voting rule in aggregating different decision trees to make the final prediction. Nonetheless, these aggregation rules would fail when the majority is more likely to be wrong. In this paper, we extend the idea proposed in Bayesian Truth Serum that "a surprisingly more popular answer is more likely the true answer" to classification problems. The challenge for us is to define or detect when an answer should be considered as being "surprising". We present two machine learning aided methods which aim to reveal the truth when it is minority instead of majority who has the true answer. Our experiments over real-world datasets show that better classification performance can be obtained compared to always trusting the majority voting. Our proposed methods also outperform popular ensemble algorithms. Our approach can be generically applied as a subroutine in ensemble methods to replace majority voting rule.
Chinese Song Iambics Generation with Neural Attention-based Model
Jun 21, 2016
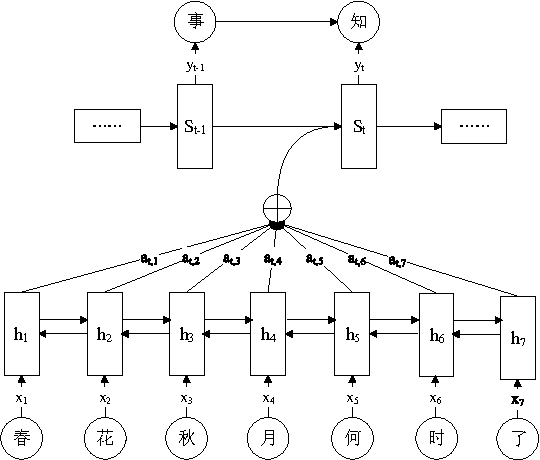


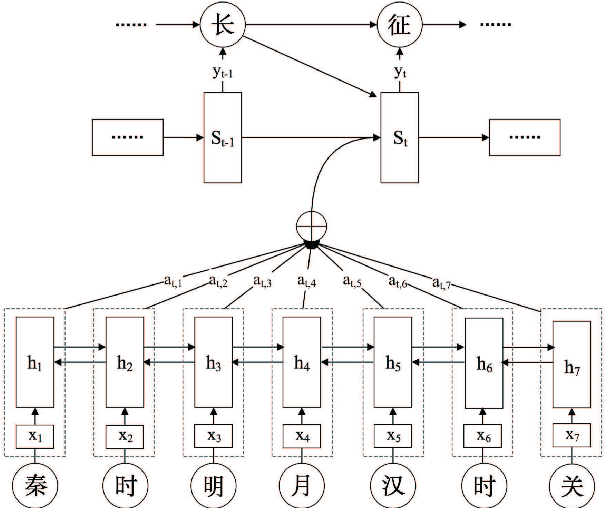
Learning and generating Chinese poems is a charming yet challenging task. Traditional approaches involve various language modeling and machine translation techniques, however, they perform not as well when generating poems with complex pattern constraints, for example Song iambics, a famous type of poems that involve variable-length sentences and strict rhythmic patterns. This paper applies the attention-based sequence-to-sequence model to generate Chinese Song iambics. Specifically, we encode the cue sentences by a bi-directional Long-Short Term Memory (LSTM) model and then predict the entire iambic with the information provided by the encoder, in the form of an attention-based LSTM that can regularize the generation process by the fine structure of the input cues. Several techniques are investigated to improve the model, including global context integration, hybrid style training, character vector initialization and adaptation. Both the automatic and subjective evaluation results show that our model indeed can learn the complex structural and rhythmic patterns of Song iambics, and the generation is rather successful.
Can Machine Generate Traditional Chinese Poetry? A Feigenbaum Test
Jun 19, 2016

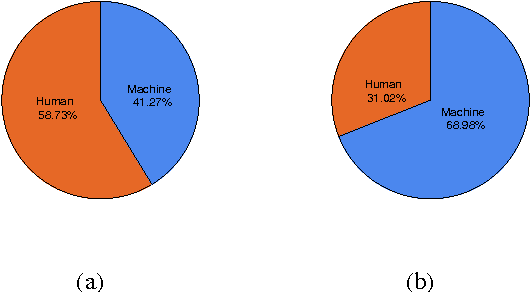
Recent progress in neural learning demonstrated that machines can do well in regularized tasks, e.g., the game of Go. However, artistic activities such as poem generation are still widely regarded as human's special capability. In this paper, we demonstrate that a simple neural model can imitate human in some tasks of art generation. We particularly focus on traditional Chinese poetry, and show that machines can do as well as many contemporary poets and weakly pass the Feigenbaum Test, a variant of Turing test in professional domains. Our method is based on an attention-based recurrent neural network, which accepts a set of keywords as the theme and generates poems by looking at each keyword during the generation. A number of techniques are proposed to improve the model, including character vector initialization, attention to input and hybrid-style training. Compared to existing poetry generation methods, our model can generate much more theme-consistent and semantic-rich poems.
Stochastic Top-k ListNet
Nov 01, 2015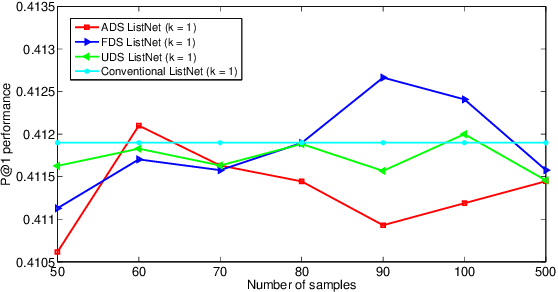
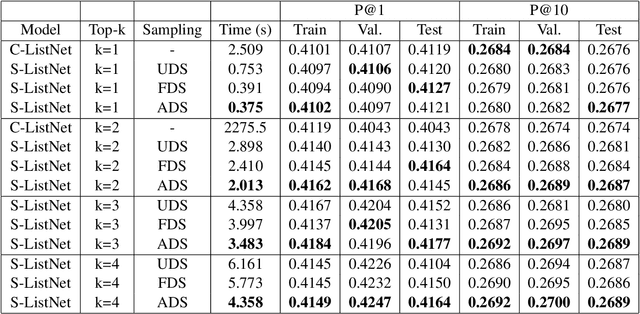
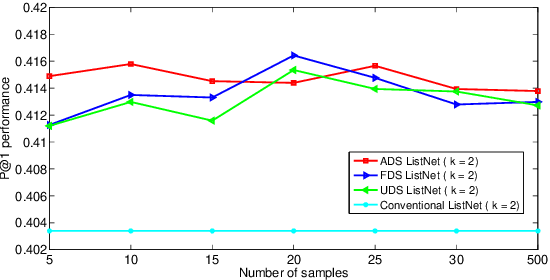
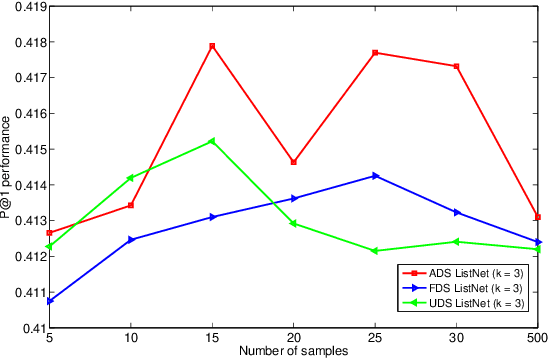
ListNet is a well-known listwise learning to rank model and has gained much attention in recent years. A particular problem of ListNet, however, is the high computation complexity in model training, mainly due to the large number of object permutations involved in computing the gradients. This paper proposes a stochastic ListNet approach which computes the gradient within a bounded permutation subset. It significantly reduces the computation complexity of model training and allows extension to Top-k models, which is impossible with the conventional implementation based on full-set permutations. Meanwhile, the new approach utilizes partial ranking information of human labels, which helps improve model quality. Our experiments demonstrated that the stochastic ListNet method indeed leads to better ranking performance and speeds up the model training remarkably.
Learning from LDA using Deep Neural Networks
Aug 05, 2015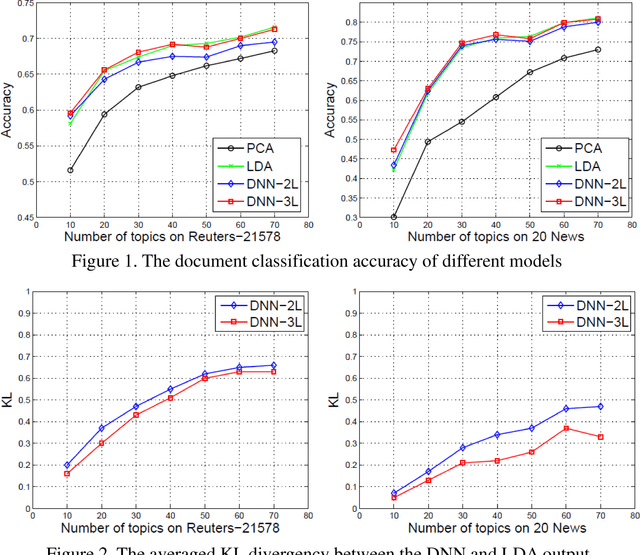
Latent Dirichlet Allocation (LDA) is a three-level hierarchical Bayesian model for topic inference. In spite of its great success, inferring the latent topic distribution with LDA is time-consuming. Motivated by the transfer learning approach proposed by~\newcite{hinton2015distilling}, we present a novel method that uses LDA to supervise the training of a deep neural network (DNN), so that the DNN can approximate the costly LDA inference with less computation. Our experiments on a document classification task show that a simple DNN can learn the LDA behavior pretty well, while the inference is speeded up tens or hundreds of times.