 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Audio-textual Architecture for Robust Spoken Language Understanding
Jun 13, 2023Recent voice assistants are usually based on the cascade spoken language understanding (SLU) solution, which consists of an automatic speech recognition (ASR) engine and a natural language understanding (NLU) system. Because such approach relies on the ASR output, it often suffers from the so-called ASR error propagation. In this work, we investigate impacts of this ASR error propagation on state-of-the-art NLU systems based on pre-trained language models (PLM), such as BERT and RoBERTa. Moreover, a multimodal language understanding (MLU) module is proposed to mitigate SLU performance degradation caused by errors present in the ASR transcript. The MLU benefits from self-supervised features learned from both audio and text modalities, specifically Wav2Vec for speech and Bert/RoBERTa for language. Our MLU combines an encoder network to embed the audio signal and a text encoder to process text transcripts followed by a late fusion layer to fuse audio and text logits. We found that the proposed MLU showed to be robust towards poor quality ASR transcripts, while the performance of BERT and RoBERTa are severely compromised. Our model is evaluated on five tasks from three SLU datasets and robustness is tested using ASR transcripts from three ASR engines. Results show that the proposed approach effectively mitigates the ASR error propagation problem, surpassing the PLM models' performance across all datasets for the academic ASR engine.
DenseShift: Towards Accurate and Transferable Low-Bit Shift Network
Aug 20, 2022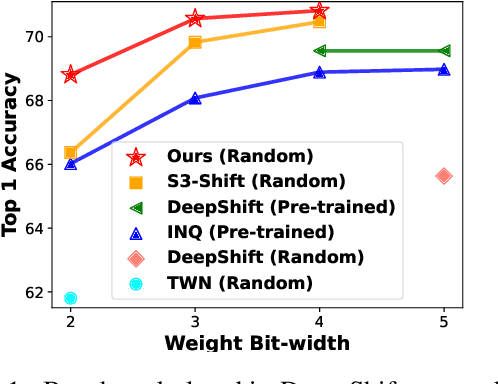
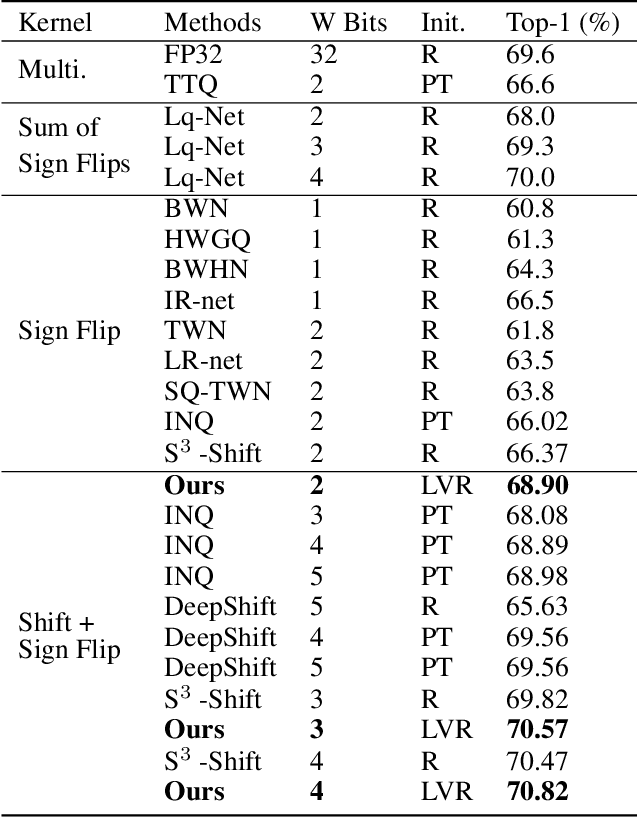
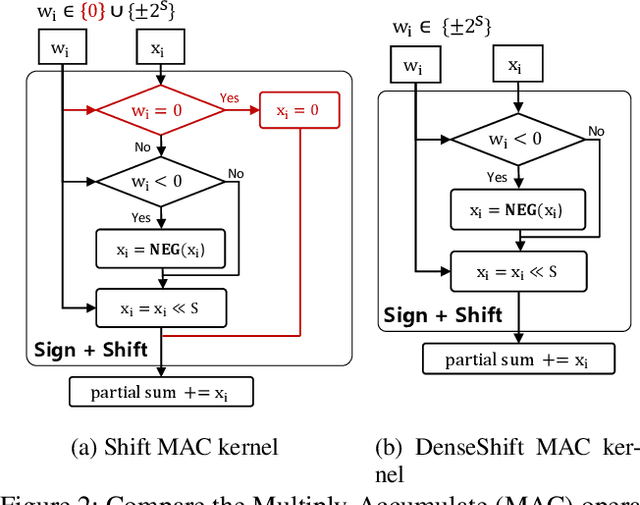
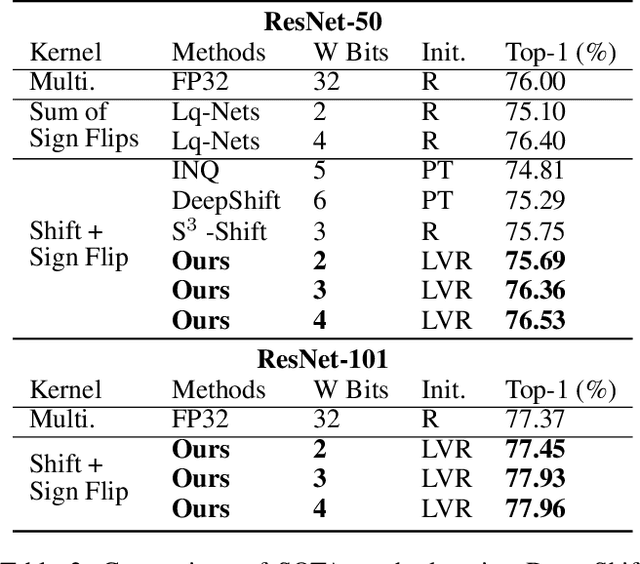
Deploying deep neural networks on low-resource edge devices is challenging due to their ever-increasing resource requirements. Recent investigations propose multiplication-free neural networks to reduce computation and memory consumption. Shift neural network is one of the most effective tools towards these reductions. However, existing low-bit shift networks are not as accurate as their full precision counterparts and cannot efficiently transfer to a wide range of tasks due to their inherent design flaws. We propose DenseShift network that exploits the following novel designs. First, we demonstrate that the zero-weight values in low-bit shift networks are neither useful to the model capacity nor simplify the model inference. Therefore, we propose to use a zero-free shifting mechanism to simplify inference while increasing the model capacity. Second, we design a new metric to measure the weight freezing issue in training low-bit shift networks, and propose a sign-scale decomposition to improve the training efficiency. Third, we propose the low-variance random initialization strategy to improve the model's performance in transfer learning scenarios. We run extensive experiments on various computer vision and speech tasks. The experimental results show that DenseShift network significantly outperforms existing low-bit multiplication-free networks and can achieve competitive performance to the full-precision counterpart. It also exhibits strong transfer learning performance with no drop in accuracy.
Low-bit Shift Network for End-to-End Spoken Language Understanding
Jul 15, 2022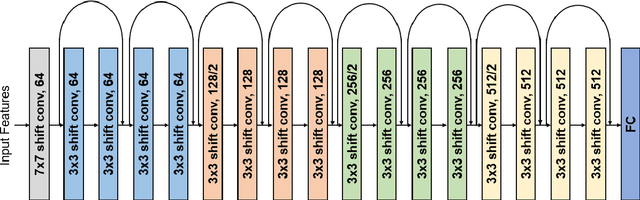
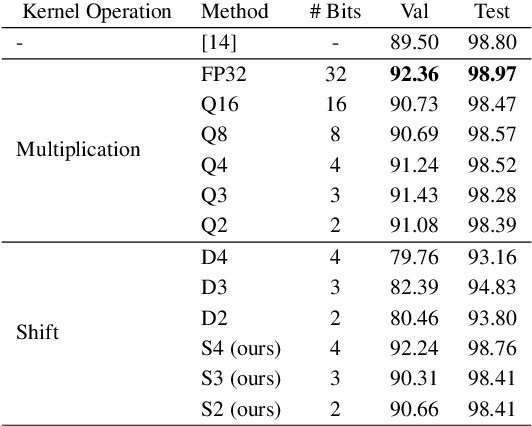
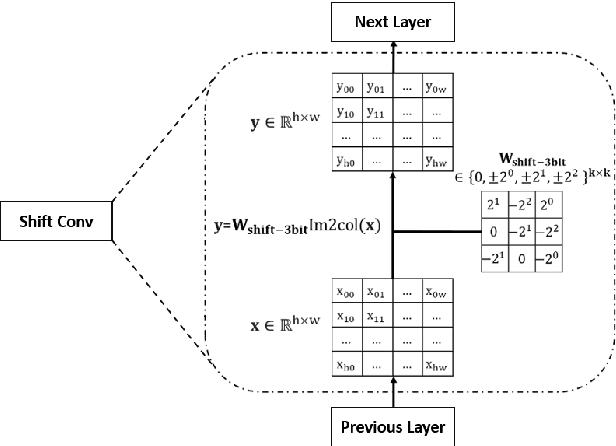
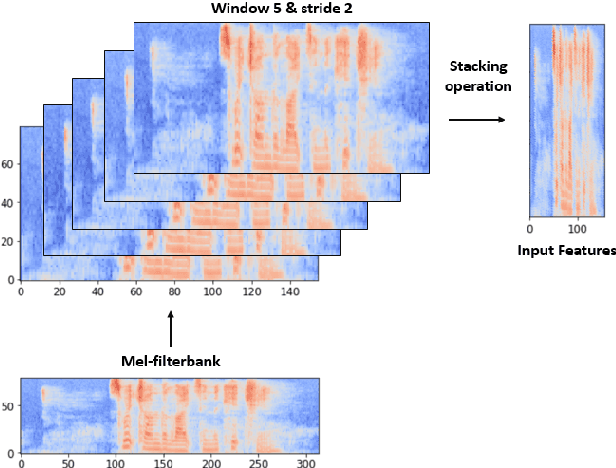
Deep neural networks (DNN) have achieved impressive success in multiple domains. Over the years, the accuracy of these models has increased with the proliferation of deeper and more complex architectures. Thus, state-of-the-art solutions are often computationally expensive, which makes them unfit to be deployed on edge computing platforms. In order to mitigate the high computation, memory, and power requirements of inferring convolutional neural networks (CNNs), we propose the use of power-of-two quantization, which quantizes continuous parameters into low-bit power-of-two values. This reduces computational complexity by removing expensive multiplication operations and with the use of low-bit weights. ResNet is adopted as the building block of our solution and the proposed model is evaluated on a spoken language understanding (SLU) task. Experimental results show improved performance for shift neural network architectures, with our low-bit quantization achieving 98.76 \% on the test set which is comparable performance to its full-precision counterpart and state-of-the-art solutions.
Revisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding
May 21, 2022
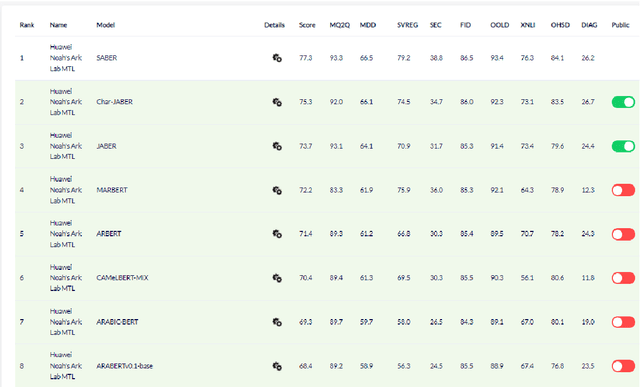

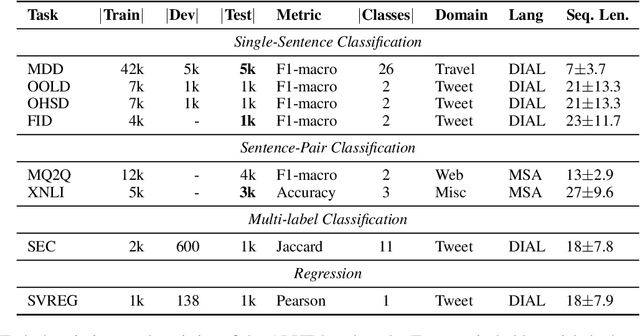
There is a growing body of work in recent years to develop pre-trained language models (PLMs) for the Arabic language. This work concerns addressing two major problems in existing Arabic PLMs which constraint progress of the Arabic NLU and NLG fields.First, existing Arabic PLMs are not well-explored and their pre-trainig can be improved significantly using a more methodical approach. Second, there is a lack of systematic and reproducible evaluation of these models in the literature. In this work, we revisit both the pre-training and evaluation of Arabic PLMs. In terms of pre-training, we explore improving Arabic LMs from three perspectives: quality of the pre-training data, size of the model, and incorporating character-level information. As a result, we release three new Arabic BERT-style models ( JABER, Char-JABER, and SABER), and two T5-style models (AT5S and AT5B). In terms of evaluation, we conduct a comprehensive empirical study to systematically evaluate the performance of existing state-of-the-art models on ALUE that is a leaderboard-powered benchmark for Arabic NLU tasks, and on a subset of the ARGEN benchmark for Arabic NLG tasks. We show that our models significantly outperform existing Arabic PLMs and achieve a new state-of-the-art performance on discriminative and generative Arabic NLU and NLG tasks. Our models and source code to reproduce of results will be made available shortly.
JABER and SABER: Junior and Senior Arabic BERt
Jan 09, 2022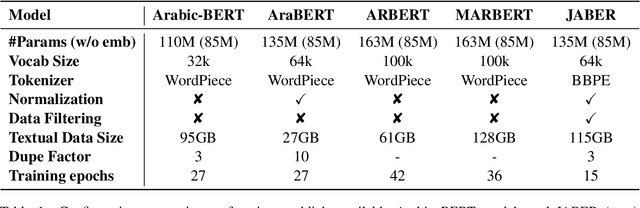
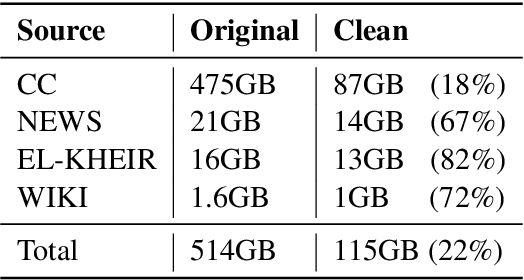
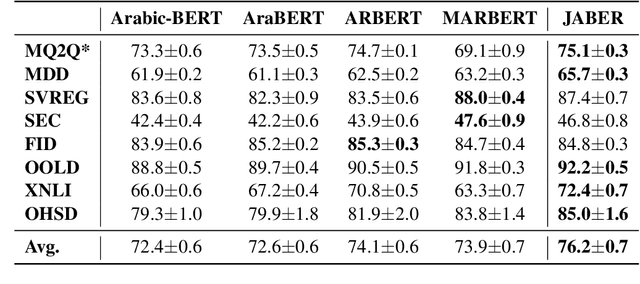
Language-specific pre-trained models have proven to be more accurate than multilingual ones in a monolingual evaluation setting, Arabic is no exception. However, we found that previously released Arabic BERT models were significantly under-trained. In this technical report, we present JABER and SABER, Junior and Senior Arabic BERt respectively, our pre-trained language model prototypes dedicated for Arabic. We conduct an empirical study to systematically evaluate the performance of models across a diverse set of existing Arabic NLU tasks. Experimental results show that JABER and SABER achieve state-of-the-art performances on ALUE, a new benchmark for Arabic Language Understanding Evaluation, as well as on a well-established NER benchmark.
A Streaming End-to-End Framework For Spoken Language Understanding
Jun 08, 2021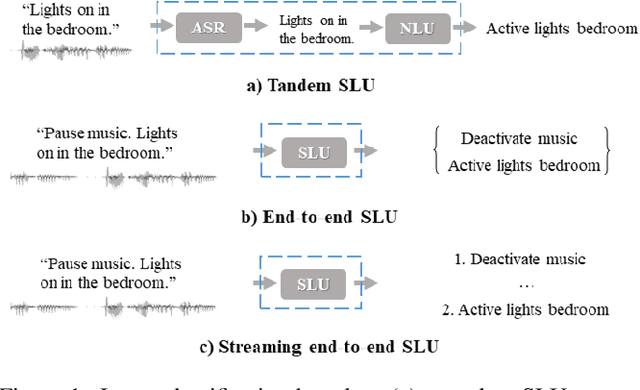
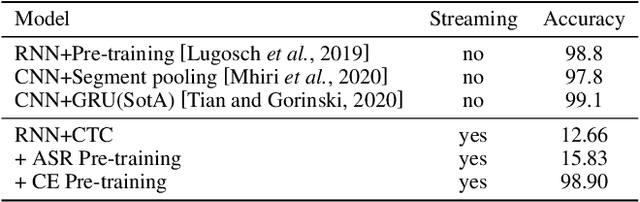
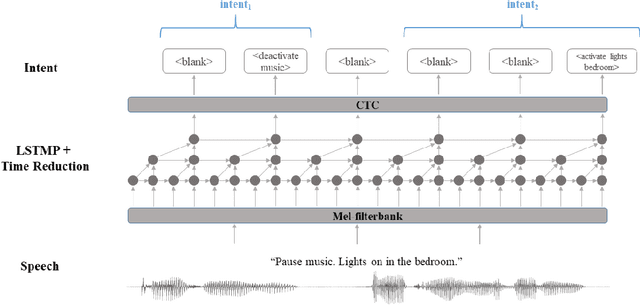

End-to-end spoken language understanding (SLU) has recently attracted increasing interest. Compared to the conventional tandem-based approach that combines speech recognition and language understanding as separate modules, the new approach extracts users' intentions directly from the speech signals, resulting in joint optimization and low latency. Such an approach, however, is typically designed to process one intention at a time, which leads users to take multiple rounds to fulfill their requirements while interacting with a dialogue system. In this paper, we propose a streaming end-to-end framework that can process multiple intentions in an online and incremental way. The backbone of our framework is a unidirectional RNN trained with the connectionist temporal classification (CTC) criterion. By this design, an intention can be identified when sufficient evidence has been accumulated, and multiple intentions can be identified sequentially. We evaluate our solution on the Fluent Speech Commands (FSC) dataset and the intent detection accuracy is about 97 % on all multi-intent settings. This result is comparable to the performance of the state-of-the-art non-streaming models, but is achieved in an online and incremental way. We also employ our model to a keyword spotting task using the Google Speech Commands dataset and the results are also highly promising.
Transformer-based ASR Incorporating Time-reduction Layer and Fine-tuning with Self-Knowledge Distillation
Mar 17, 2021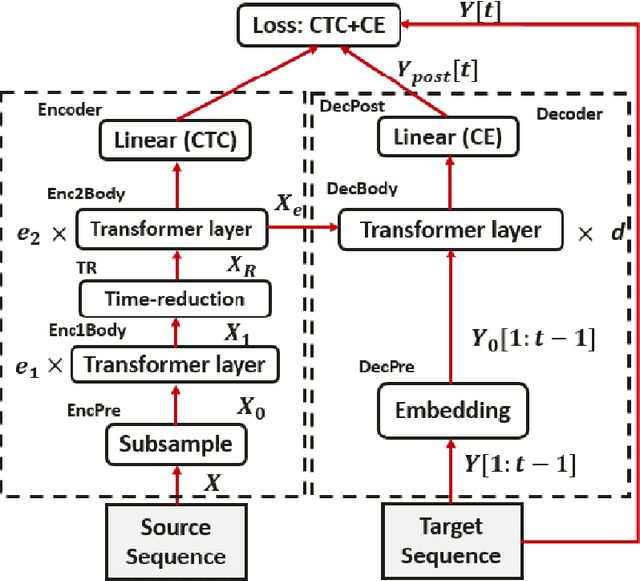
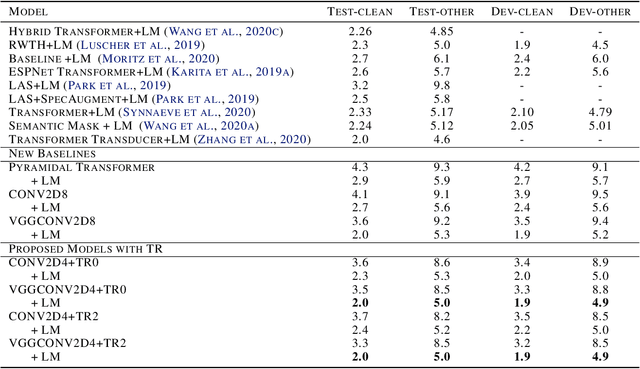
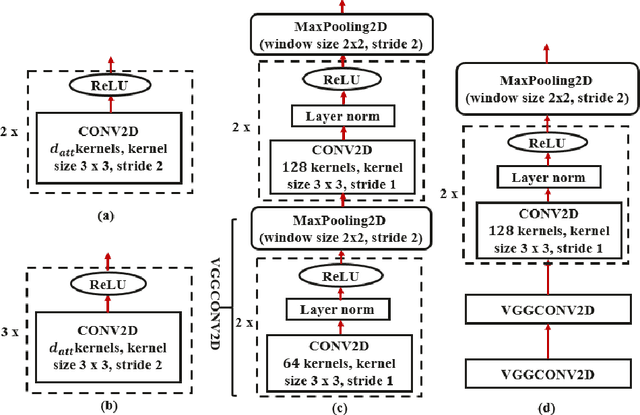
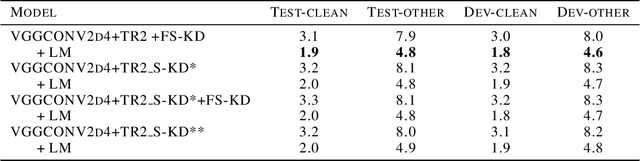
End-to-end automatic speech recognition (ASR), unlike conventional ASR, does not have modules to learn the semantic representation from speech encoder. Moreover, the higher frame-rate of speech representation prevents the model to learn the semantic representation properly. Therefore, the models that are constructed by the lower frame-rate of speech encoder lead to better performance. For Transformer-based ASR, the lower frame-rate is not only important for learning better semantic representation but also for reducing the computational complexity due to the self-attention mechanism which has O(n^2) order of complexity in both training and inference. In this paper, we propose a Transformer-based ASR model with the time reduction layer, in which we incorporate time reduction layer inside transformer encoder layers in addition to traditional sub-sampling methods to input features that further reduce the frame-rate. This can help in reducing the computational cost of the self-attention process for training and inference with performance improvement. Moreover, we introduce a fine-tuning approach for pre-trained ASR models using self-knowledge distillation (S-KD) which further improves the performance of our ASR model. Experiments on LibriSpeech datasets show that our proposed methods outperform all other Transformer-based ASR systems. Furthermore, with language model (LM) fusion, we achieve new state-of-the-art word error rate (WER) results for Transformer-based ASR models with just 30 million parameters trained without any external data.
Deep Label Distribution Learning with Label Ambiguity
May 10, 2017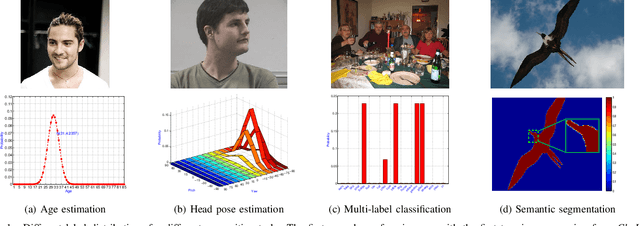

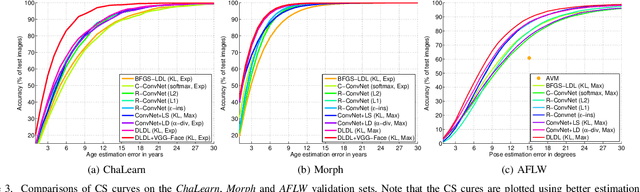
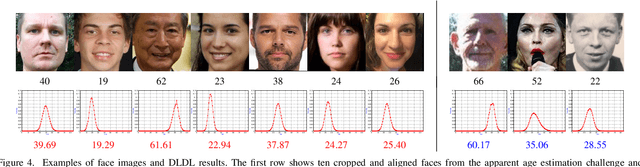
Convolutional Neural Networks (ConvNets) have achieved excellent recognition performance in various visual recognition tasks. A large labeled training set is one of the most important factors for its success. However, it is difficult to collect sufficient training images with precise labels in some domains such as apparent age estimation, head pose estimation, multi-label classification and semantic segmentation. Fortunately, there is ambiguous information among labels, which makes these tasks different from traditional classification. Based on this observation, we convert the label of each image into a discrete label distribution, and learn the label distribution by minimizing a Kullback-Leibler divergence between the predicted and ground-truth label distributions using deep ConvNets. The proposed DLDL (Deep Label Distribution Learning) method effectively utilizes the label ambiguity in both feature learning and classifier learning, which help prevent the network from over-fitting even when the training set is small. Experimental results show that the proposed approach produces significantly better results than state-of-the-art methods for age estimation and head pose estimation. At the same time, it also improves recognition performance for multi-label classification and semantic segmentation tasks.
* Accepted by IEEE TIP 2017. Projects page, see http://lamda.nju.edu.cn/gaobb/projects/DLDL.html
Chinese Song Iambics Generation with Neural Attention-based Model
Jun 21, 2016
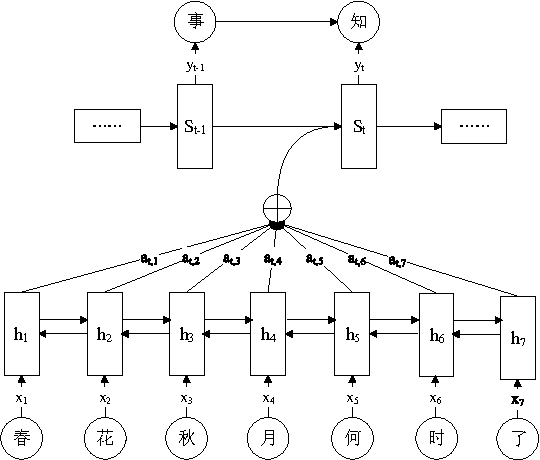


Learning and generating Chinese poems is a charming yet challenging task. Traditional approaches involve various language modeling and machine translation techniques, however, they perform not as well when generating poems with complex pattern constraints, for example Song iambics, a famous type of poems that involve variable-length sentences and strict rhythmic patterns. This paper applies the attention-based sequence-to-sequence model to generate Chinese Song iambics. Specifically, we encode the cue sentences by a bi-directional Long-Short Term Memory (LSTM) model and then predict the entire iambic with the information provided by the encoder, in the form of an attention-based LSTM that can regularize the generation process by the fine structure of the input cues. Several techniques are investigated to improve the model, including global context integration, hybrid style training, character vector initialization and adaptation. Both the automatic and subjective evaluation results show that our model indeed can learn the complex structural and rhythmic patterns of Song iambics, and the generation is rather successful.
Binary Speaker Embedding
Mar 31, 2016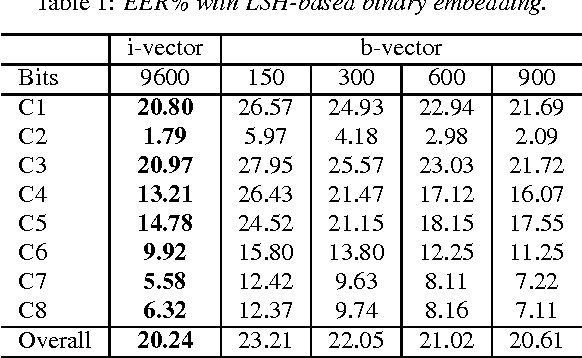
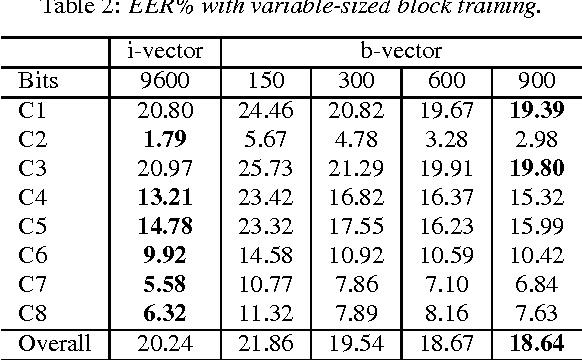
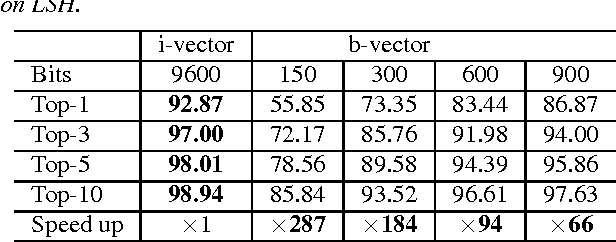
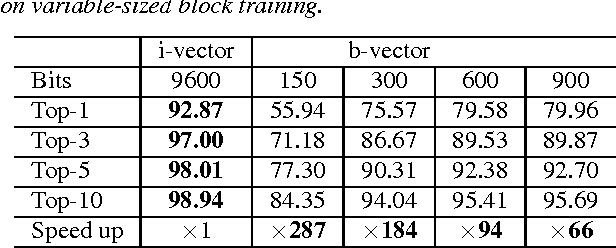
The popular i-vector model represents speakers as low-dimensional continuous vectors (i-vectors), and hence it is a way of continuous speaker embedding. In this paper, we investigate binary speaker embedding, which transforms i-vectors to binary vectors (codes) by a hash function. We start from locality sensitive hashing (LSH), a simple binarization approach where binary codes are derived from a set of random hash functions. A potential problem of LSH is that the randomly sampled hash functions might be suboptimal. We therefore propose an improved Hamming distance learning approach, where the hash function is learned by a variable-sized block training that projects each dimension of the original i-vectors to variable-sized binary codes independently. Our experiments show that binary speaker embedding can deliver competitive or even better results on both speaker verification and identification tasks, while the memory usage and the computation cost are significantly reduced.