 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUD-SfPNet: An Underwater Descattering Shape-from-Polarization Network for 3D Normal Reconstruction
Mar 01, 2026Underwater optical imaging is severely hindered by scattering, but polarization imaging offers the unique dual advantages of descattering and shape-from-polarization (SfP) 3D reconstruction. To exploit these advantages, this paper proposes UD-SfPNet, an underwater descattering shape-from-polarization network that leverages polarization cues for improved 3D surface normal prediction. The framework jointly models polarization-based image descattering and SfP normal estimation in a unified pipeline, avoiding error accumulation from sequential processing and enabling global optimization across both tasks. UD-SfPNet further incorporates a novel color embedding module to enhance geometric consistency by exploiting the relationship between color encodings and surface orientation. A detail enhancement convolution module is also included to better preserve high-frequency geometric details that are lost under scattering. Experiments on the MuS-Polar3D dataset show that the proposed method significantly improves reconstruction accuracy, achieving a mean surface normal angular error of 15.12$^\circ$ (the lowest among compared methods). These results confirm the efficacy of combining descattering with polarization-based shape inference, and highlight the practical significance and potential applications of UD-SfPNet for optical 3D imaging in challenging underwater environments. The code is available at https://github.com/WangPuyun/UD-SfPNet.
MuS-Polar3D: A Benchmark Dataset for Computational Polarimetric 3D Imaging under Multi-Scattering Conditions
Dec 25, 2025Polarization-based underwater 3D imaging exploits polarization cues to suppress background scattering, exhibiting distinct advantages in turbid water. Although data-driven polarization-based underwater 3D reconstruction methods show great potential, existing public datasets lack sufficient diversity in scattering and observation conditions, hindering fair comparisons among different approaches, including single-view and multi-view polarization imaging methods. To address this limitation, we construct MuS-Polar3D, a benchmark dataset comprising polarization images of 42 objects captured under seven quantitatively controlled scattering conditions and five viewpoints, together with high-precision 3D models (+/- 0.05 mm accuracy), normal maps, and foreground masks. The dataset supports multiple vision tasks, including normal estimation, object segmentation, descattering, and 3D reconstruction. Inspired by computational imaging, we further decouple underwater 3D reconstruction under scattering into a two-stage pipeline, namely descattering followed by 3D reconstruction, from an imaging-chain perspective. Extensive evaluations using multiple baseline methods under complex scattering conditions demonstrate the effectiveness of the proposed benchmark, achieving a best mean angular error of 15.49 degrees. To the best of our knowledge, MuS-Polar3D is the first publicly available benchmark dataset for quantitative turbidity underwater polarization-based 3D imaging, enabling accurate reconstruction and fair algorithm evaluation under controllable scattering conditions. The dataset and code are publicly available at https://github.com/WangPuyun/MuS-Polar3D.
Binary Speaker Embedding
Mar 31, 2016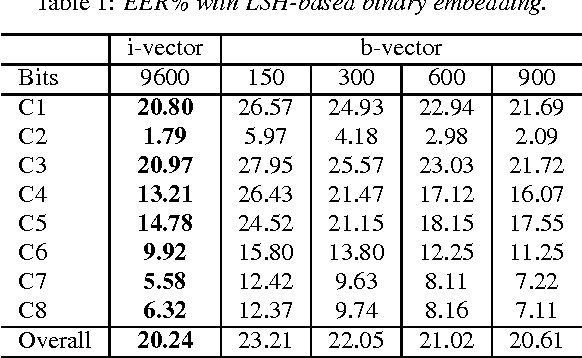
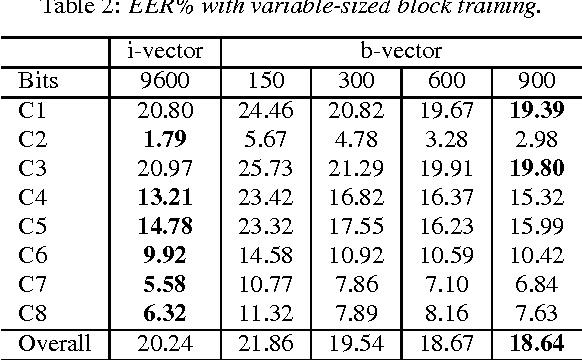
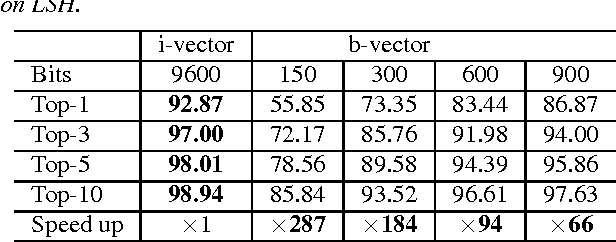
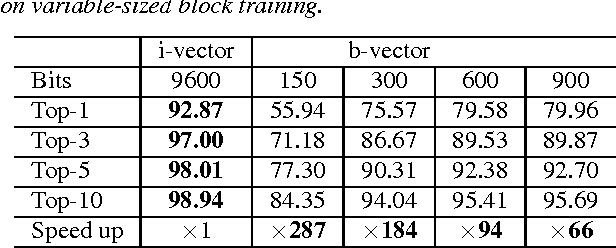
The popular i-vector model represents speakers as low-dimensional continuous vectors (i-vectors), and hence it is a way of continuous speaker embedding. In this paper, we investigate binary speaker embedding, which transforms i-vectors to binary vectors (codes) by a hash function. We start from locality sensitive hashing (LSH), a simple binarization approach where binary codes are derived from a set of random hash functions. A potential problem of LSH is that the randomly sampled hash functions might be suboptimal. We therefore propose an improved Hamming distance learning approach, where the hash function is learned by a variable-sized block training that projects each dimension of the original i-vectors to variable-sized binary codes independently. Our experiments show that binary speaker embedding can deliver competitive or even better results on both speaker verification and identification tasks, while the memory usage and the computation cost are significantly reduced.