 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank and Sparse Model Merging for Multi-Lingual Speech Recognition and Translation
Feb 26, 2025Language diversity presents a significant challenge in speech-to-text (S2T) tasks, such as automatic speech recognition and translation. Traditional multi-task training approaches aim to address this by jointly optimizing multiple speech recognition and translation tasks across various languages. While models like Whisper, built on these strategies, demonstrate strong performance, they still face issues of high computational cost, language interference, suboptimal training configurations, and limited extensibility. To overcome these challenges, we introduce LoRS-Merging (low-rank and sparse model merging), a novel technique designed to efficiently integrate models trained on different languages or tasks while preserving performance and reducing computational overhead. LoRS-Merging combines low-rank and sparse pruning to retain essential structures while eliminating redundant parameters, mitigating language and task interference, and enhancing extensibility. Experimental results across a range of languages demonstrate that LoRS-Merging reduces the word error rate by 10% and improves BLEU scores by 4% compared to conventional multi-lingual multi-task training baselines. Our findings suggest that model merging, particularly LoRS-Merging, is a scalable and effective complement to traditional multi-lingual training strategies for S2T applications.
Whisper-PMFA: Partial Multi-Scale Feature Aggregation for Speaker Verification using Whisper Models
Aug 28, 2024



In this paper, Whisper, a large-scale pre-trained model for automatic speech recognition, is proposed to apply to speaker verification. A partial multi-scale feature aggregation (PMFA) approach is proposed based on a subset of Whisper encoder blocks to derive highly discriminative speaker embeddings.Experimental results demonstrate that using the middle to later blocks of the Whisper encoder keeps more speaker information. On the VoxCeleb1 and CN-Celeb1 datasets, our system achieves 1.42% and 8.23% equal error rates (EERs) respectively, receiving 0.58% and 1.81% absolute EER reductions over the ECAPA-TDNN baseline, and 0.46% and 0.97% over the ResNet34 baseline. Furthermore, our results indicate that using Whisper models trained on multilingual data can effectively enhance the model's robustness across languages. Finally, the low-rank adaptation approach is evaluated, which reduces the trainable model parameters by approximately 45 times while only slightly increasing EER by 0.2%.
A Joint Noise Disentanglement and Adversarial Training Framework for Robust Speaker Verification
Aug 22, 2024
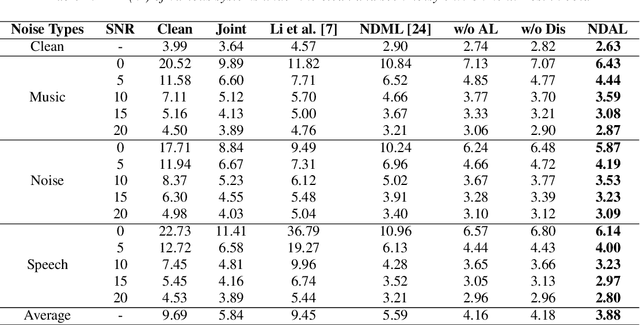

Automatic Speaker Verification (ASV) suffers from performance degradation in noisy conditions. To address this issue, we propose a novel adversarial learning framework that incorporates noise-disentanglement to establish a noise-independent speaker invariant embedding space. Specifically, the disentanglement module includes two encoders for separating speaker related and irrelevant information, respectively. The reconstruction module serves as a regularization term to constrain the noise. A feature-robust loss is also used to supervise the speaker encoder to learn noise-independent speaker embeddings without losing speaker information. In addition, adversarial training is introduced to discourage the speaker encoder from encoding acoustic condition information for achieving a speaker-invariant embedding space. Experiments on VoxCeleb1 indicate that the proposed method improves the performance of the speaker verification system under both clean and noisy conditions.
Speaker Adaptation for Quantised End-to-End ASR Models
Aug 07, 2024

End-to-end models have shown superior performance for automatic speech recognition (ASR). However, such models are often very large in size and thus challenging to deploy on resource-constrained edge devices. While quantisation can reduce model sizes, it can lead to increased word error rates (WERs). Although improved quantisation methods were proposed to address the issue of performance degradation, the fact that quantised models deployed on edge devices often target only on a small group of users is under-explored. To this end, we propose personalisation for quantised models (P4Q), a novel strategy that uses speaker adaptation (SA) to improve quantised end-to-end ASR models by fitting them to the characteristics of the target speakers. In this paper, we study the P4Q strategy based on Whisper and Conformer attention-based encoder-decoder (AED) end-to-end ASR models, which leverages a 4-bit block-wise NormalFloat4 (NF4) approach for quantisation and the low-rank adaptation (LoRA) approach for SA. Experimental results on the LibriSpeech and the TED-LIUM 3 corpora show that, with a 7-time reduction in model size and 1% extra speaker-specific parameters, 15.1% and 23.3% relative WER reductions were achieved on quantised Whisper and Conformer AED models respectively, comparing to the full precision models.
SAML: Speaker Adaptive Mixture of LoRA Experts for End-to-End ASR
Jun 28, 2024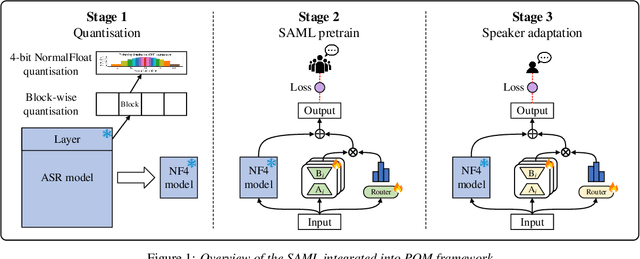



Mixture-of-experts (MoE) models have achieved excellent results in many tasks. However, conventional MoE models are often very large, making them challenging to deploy on resource-constrained edge devices. In this paper, we propose a novel speaker adaptive mixture of LoRA experts (SAML) approach, which uses low-rank adaptation (LoRA) modules as experts to reduce the number of trainable parameters in MoE. Specifically, SAML is applied to the quantised and personalised end-to-end automatic speech recognition models, which combines test-time speaker adaptation to improve the performance of heavily compressed models in speaker-specific scenarios. Experiments have been performed on the LibriSpeech and the TED-LIUM 3 corpora. Remarkably, with a 7x reduction in model size, 29.1% and 31.1% relative word error rate reductions were achieved on the quantised Whisper model and Conformer-based attention-based encoder-decoder ASR model respectively, comparing to the original full precision models.
Enhancing Quantised End-to-End ASR Models via Personalisation
Sep 17, 2023Recent end-to-end automatic speech recognition (ASR) models have become increasingly larger, making them particularly challenging to be deployed on resource-constrained devices. Model quantisation is an effective solution that sometimes causes the word error rate (WER) to increase. In this paper, a novel strategy of personalisation for a quantised model (PQM) is proposed, which combines speaker adaptive training (SAT) with model quantisation to improve the performance of heavily compressed models. Specifically, PQM uses a 4-bit NormalFloat Quantisation (NF4) approach for model quantisation and low-rank adaptation (LoRA) for SAT. Experiments have been performed on the LibriSpeech and the TED-LIUM 3 corpora. Remarkably, with a 7x reduction in model size and 1% additional speaker-specific parameters, 15.1% and 23.3% relative WER reductions were achieved on quantised Whisper and Conformer-based attention-based encoder-decoder ASR models respectively, comparing to the original full precision models.
How Speech is Recognized to Be Emotional - A Study Based on Information Decomposition
Nov 24, 2021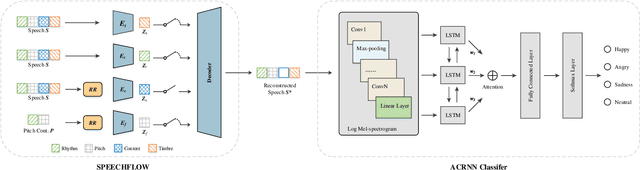
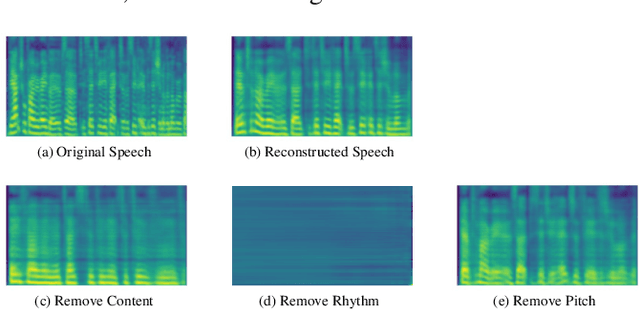
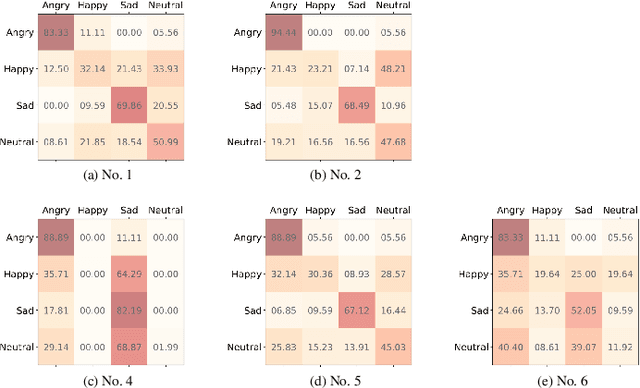
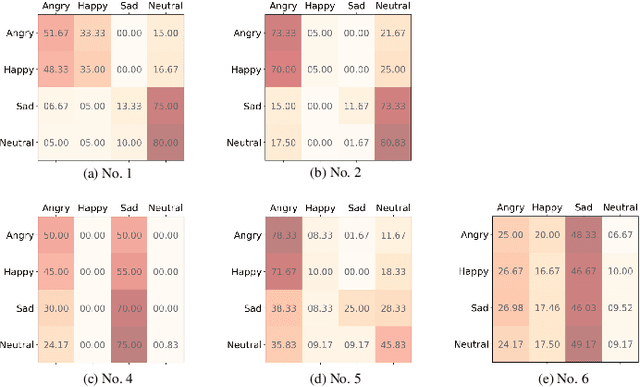
The way that humans encode their emotion into speech signals is complex. For instance, an angry man may increase his pitch and speaking rate, and use impolite words. In this paper, we present a preliminary study on various emotional factors and investigate how each of them impacts modern emotion recognition systems. The key tool of our study is the SpeechFlow model presented recently, by which we are able to decompose speech signals into separate information factors (content, pitch, rhythm). Based on this decomposition, we carefully studied the performance of each information component and their combinations. We conducted the study on three different speech emotion corpora and chose an attention-based convolutional RNN as the emotion classifier. Our results show that rhythm is the most important component for emotional expression. Moreover, the cross-corpus results are very bad (even worse than guess), demonstrating that the present speech emotion recognition model is rather weak. Interestingly, by removing one or several unimportant components, the cross-corpus results can be improved. This demonstrates the potential of the decomposition approach towards a generalizable emotion recognition.
A Multi-Resolution Front-End for End-to-End Speech Anti-Spoofing
Oct 11, 2021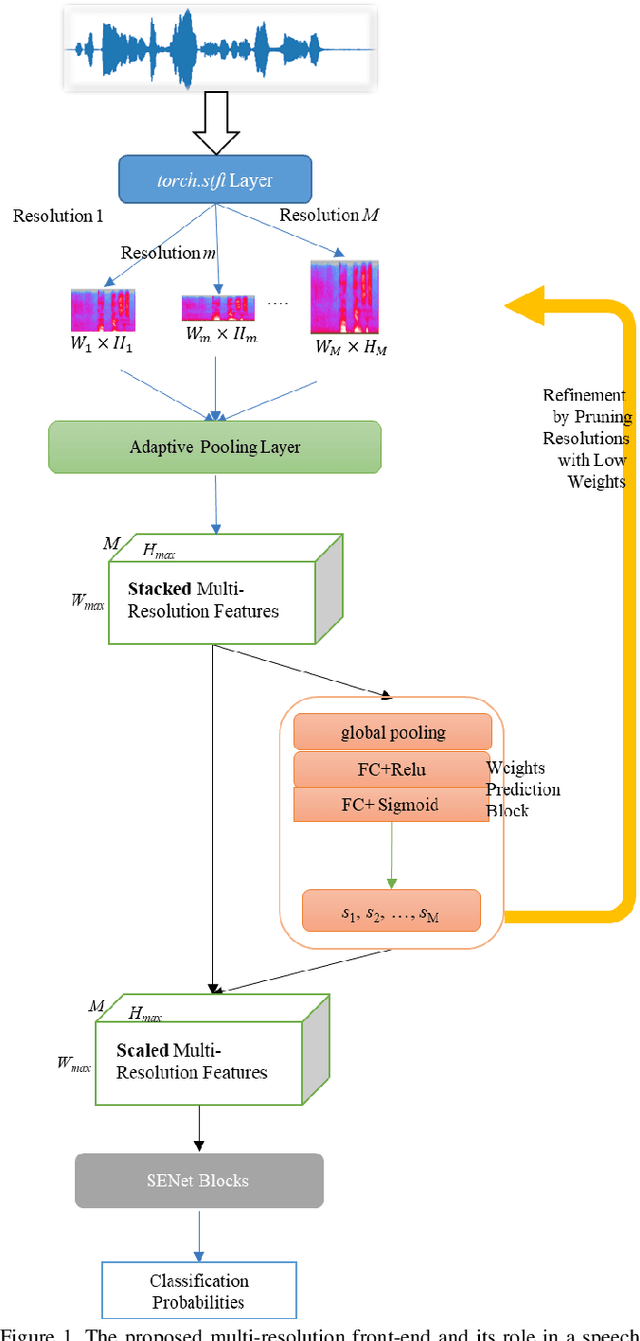
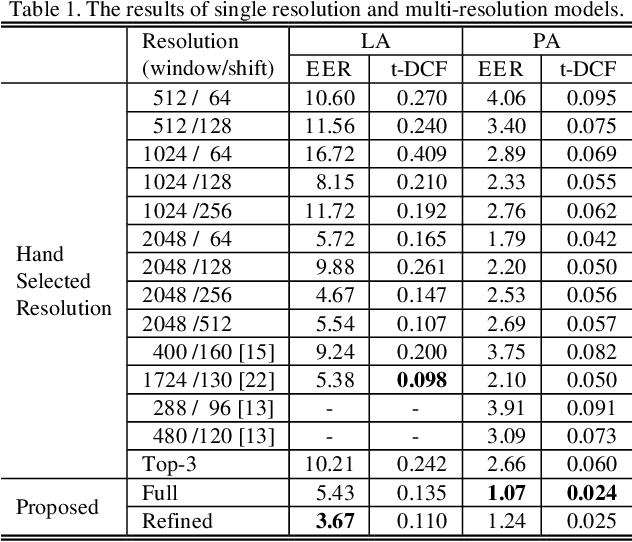
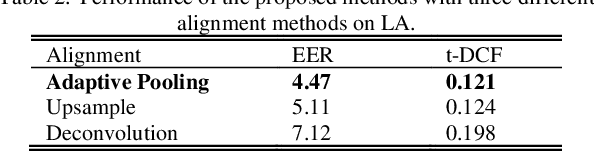
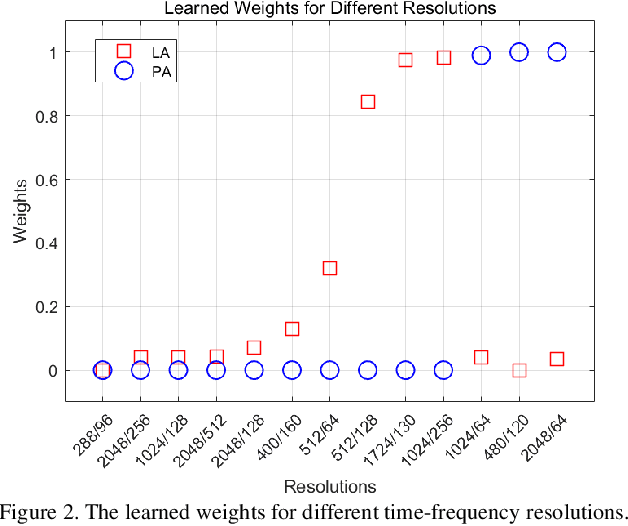
The choice of an optimal time-frequency resolution is usually a difficult but important step in tasks involving speech signal classification, e.g., speech anti-spoofing. The variations of the performance with different choices of timefrequency resolutions can be as large as those with different model architectures, which makes it difficult to judge what the improvement actually comes from when a new network architecture is invented and introduced as the classifier. In this paper, we propose a multi-resolution front-end for feature extraction in an end-to-end classification framework. Optimal weighted combinations of multiple time-frequency resolutions will be learned automatically given the objective of a classification task. Features extracted with different time-frequency resolutions are weighted and concatenated as inputs to the successive networks, where the weights are predicted by a learnable neural network inspired by the weighting block in squeeze-and-excitation networks (SENet). Furthermore, the refinement of the chosen timefrequency resolutions is investigated by pruning the ones with relatively low importance, which reduces the complexity and size of the model. The proposed method is evaluated on the tasks of speech anti-spoofing in ASVSpoof 2019 and its superiority has been justified by comparing with similar baselines.
Attack on practical speaker verification system using universal adversarial perturbations
May 19, 2021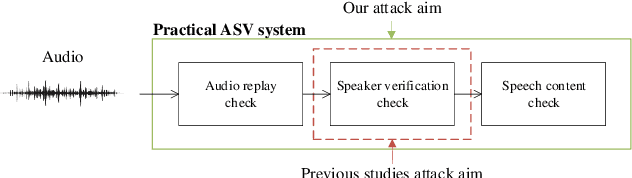


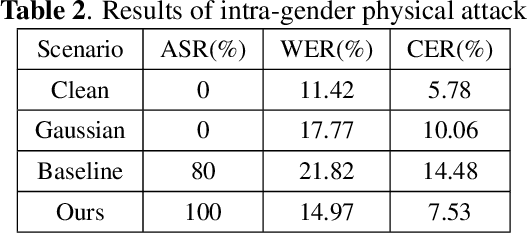
In authentication scenarios, applications of practical speaker verification systems usually require a person to read a dynamic authentication text. Previous studies played an audio adversarial example as a digital signal to perform physical attacks, which would be easily rejected by audio replay detection modules. This work shows that by playing our crafted adversarial perturbation as a separate source when the adversary is speaking, the practical speaker verification system will misjudge the adversary as a target speaker. A two-step algorithm is proposed to optimize the universal adversarial perturbation to be text-independent and has little effect on the authentication text recognition. We also estimated room impulse response (RIR) in the algorithm which allowed the perturbation to be effective after being played over the air. In the physical experiment, we achieved targeted attacks with success rate of 100%, while the word error rate (WER) on speech recognition was only increased by 3.55%. And recorded audios could pass replay detection for the live person speaking.
CN-Celeb: multi-genre speaker recognition
Dec 23, 2020
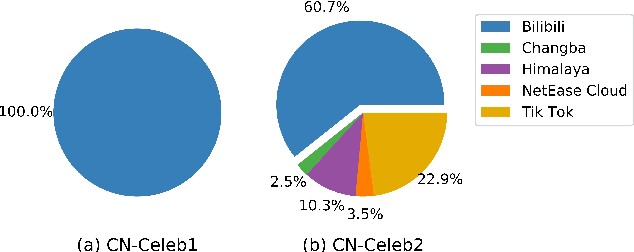
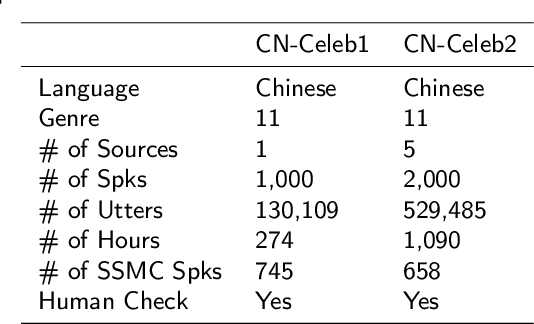
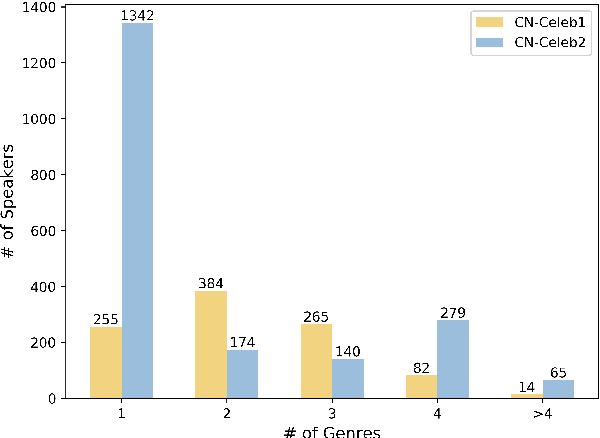
Research on speaker recognition is extending to address the vulnerability in the wild conditions, among which genre mismatch is perhaps the most challenging, for instance, enrollment with reading speech while testing with conversational or singing audio. This mismatch leads to complex and composite inter-session variations, both intrinsic (i.e., speaking style, physiological status) and extrinsic (i.e., recording device, background noise). Unfortunately, the few existing multi-genre corpora are not only limited in size but are also recorded under controlled conditions, which cannot support conclusive research on the multi-genre problem. In this work, we firstly publish CN-Celeb, a large-scale multi-genre corpus that includes in-the-wild speech utterances of 3,000 speakers in 11 different genres. Secondly, using this dataset, we conduct a comprehensive study on the multi-genre phenomenon, in particular the impact of the multi-genre challenge on speaker recognition, and on how to utilize the valuable multi-genre data more efficiently.