 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Adjacency Matrix Configuration in GCN-based Models for Skeleton-based Action Recognition
Jun 29, 2022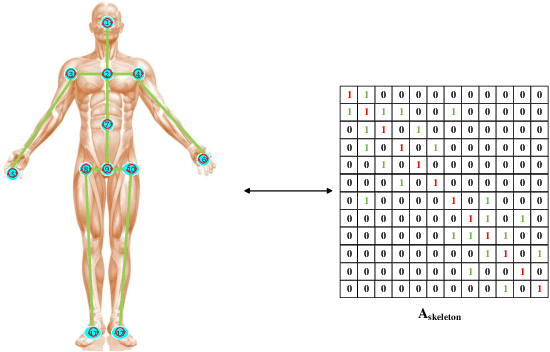
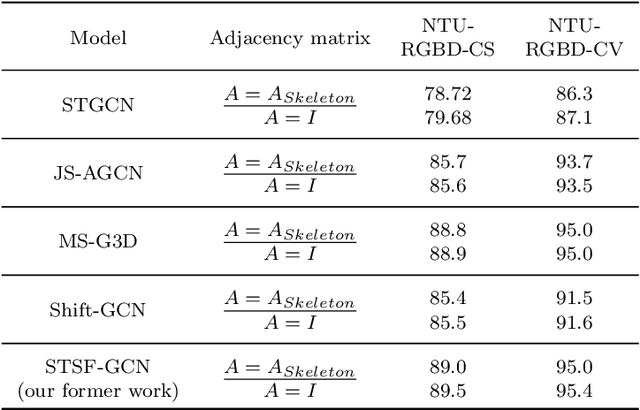
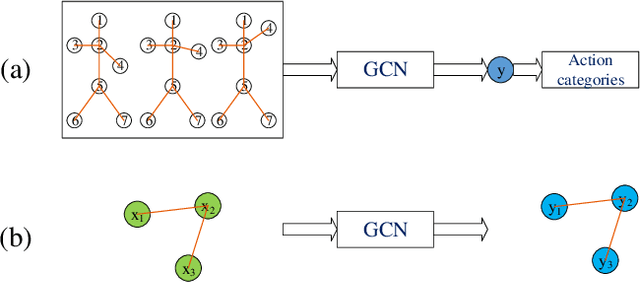
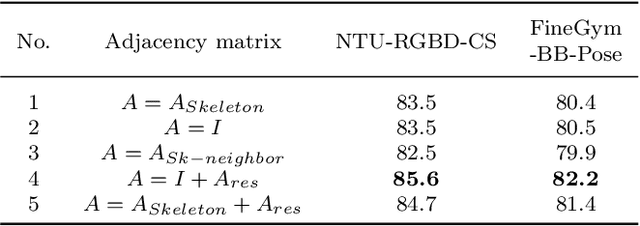
Human skeleton data has received increasing attention in action recognition due to its background robustness and high efficiency. In skeleton-based action recognition, graph convolutional network (GCN) has become the mainstream method. This paper analyzes the fundamental factor for GCN-based models -- the adjacency matrix. We notice that most GCN-based methods conduct their adjacency matrix based on the human natural skeleton structure. Based on our former work and analysis, we propose that the human natural skeleton structure adjacency matrix is not proper for skeleton-based action recognition. We propose a new adjacency matrix that abandons all rigid neighbor connections but lets the model adaptively learn the relationships of joints. We conduct extensive experiments and analysis with a validation model on two skeleton-based action recognition datasets (NTURGBD60 and FineGYM). Comprehensive experimental results and analysis reveals that 1) the most widely used human natural skeleton structure adjacency matrix is unsuitable in skeleton-based action recognition; 2) The proposed adjacency matrix is superior in model performance, noise robustness and transferability.
A Multi-Resolution Front-End for End-to-End Speech Anti-Spoofing
Oct 11, 2021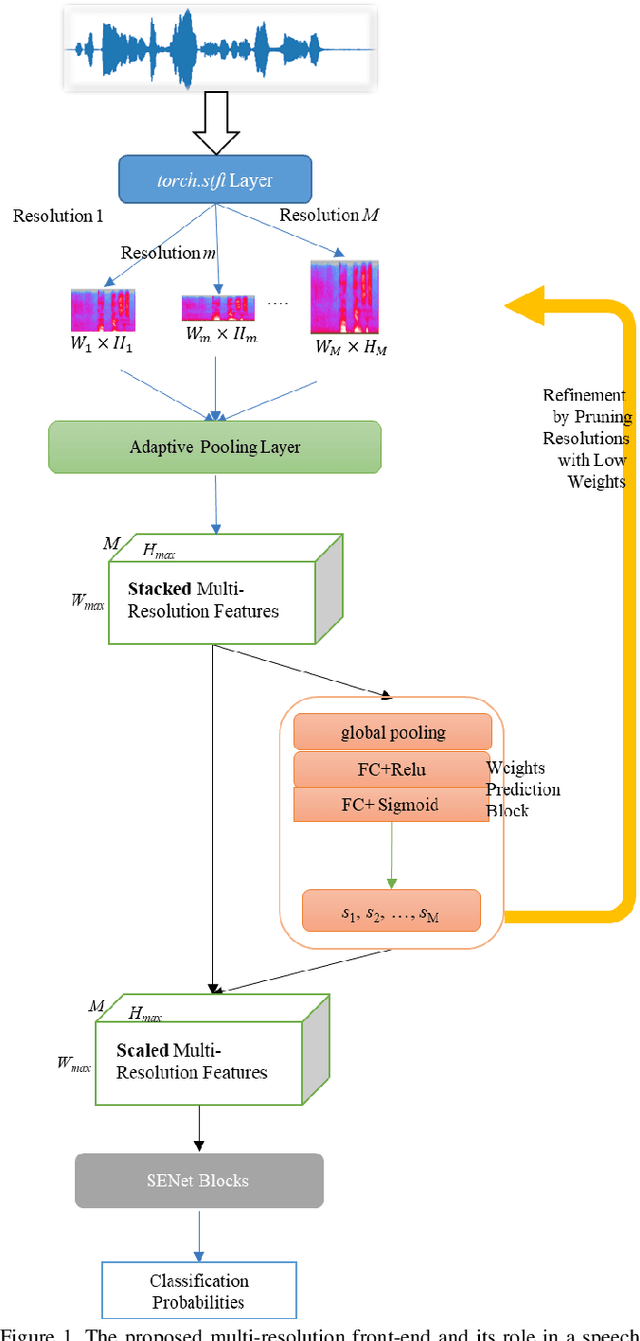
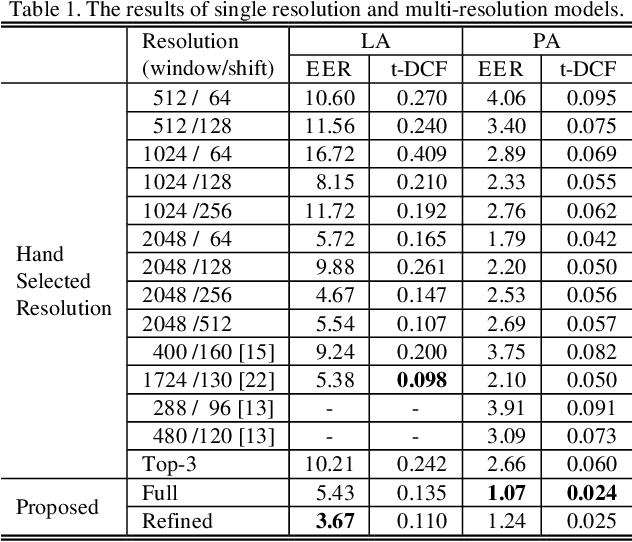
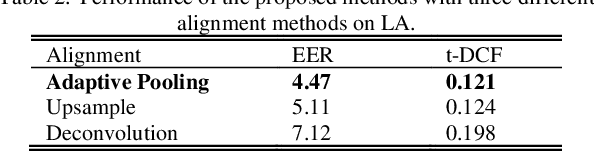
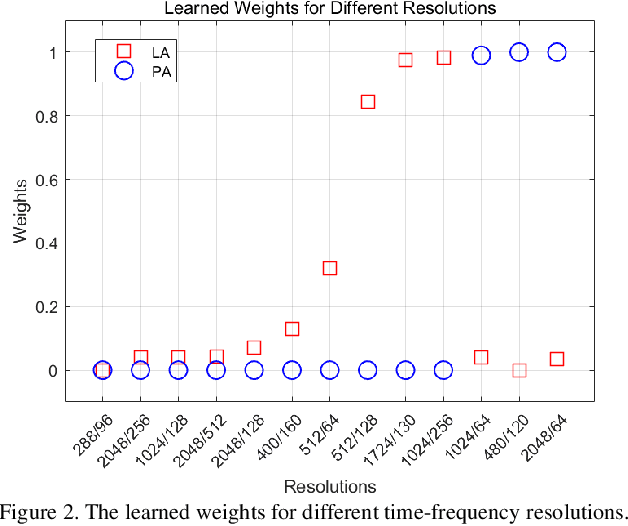
The choice of an optimal time-frequency resolution is usually a difficult but important step in tasks involving speech signal classification, e.g., speech anti-spoofing. The variations of the performance with different choices of timefrequency resolutions can be as large as those with different model architectures, which makes it difficult to judge what the improvement actually comes from when a new network architecture is invented and introduced as the classifier. In this paper, we propose a multi-resolution front-end for feature extraction in an end-to-end classification framework. Optimal weighted combinations of multiple time-frequency resolutions will be learned automatically given the objective of a classification task. Features extracted with different time-frequency resolutions are weighted and concatenated as inputs to the successive networks, where the weights are predicted by a learnable neural network inspired by the weighting block in squeeze-and-excitation networks (SENet). Furthermore, the refinement of the chosen timefrequency resolutions is investigated by pruning the ones with relatively low importance, which reduces the complexity and size of the model. The proposed method is evaluated on the tasks of speech anti-spoofing in ASVSpoof 2019 and its superiority has been justified by comparing with similar baselines.
Low Bit-Rate Wideband Speech Coding: A Deep Generative Model based Approach
Feb 04, 2021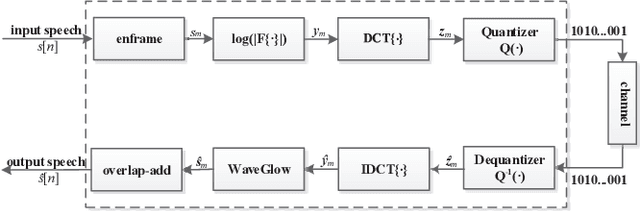



Traditional low bit-rate speech coding approach only handles narrowband speech at 8kHz, which limits further improvements in speech quality. Motivated by recent successful exploration of deep learning methods for image and speech compression, this paper presents a new approach through vector quantization (VQ) of mel-frequency cepstral coefficients (MFCCs) and using a deep generative model called WaveGlow to provide efficient and high-quality speech coding. The coding feature is sorely an 80-dimension MFCCs vector for 16kHz wideband speech, then speech coding at the bit-rate throughout 1000-2000 bit/s could be scalably implemented by applying different VQ schemes for MFCCs vector. This new deep generative network based codec works fast as the WaveGlow model abandons the sample-by-sample autoregressive mechanism. We evaluated this new approach over the multi-speaker TIMIT corpus, and experimental results demonstrate that it provides better speech quality compared with the state-of-the-art classic MELPe codec at lower bit-rate.