 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint Noise Disentanglement and Adversarial Training Framework for Robust Speaker Verification
Aug 22, 2024
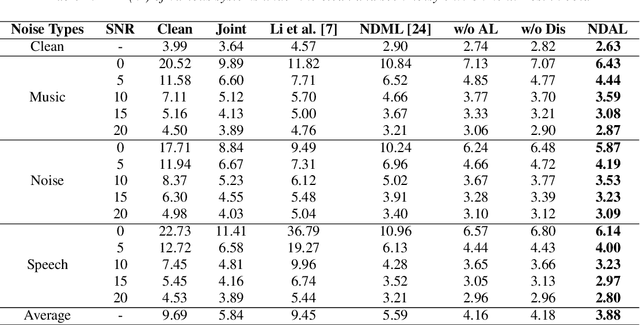

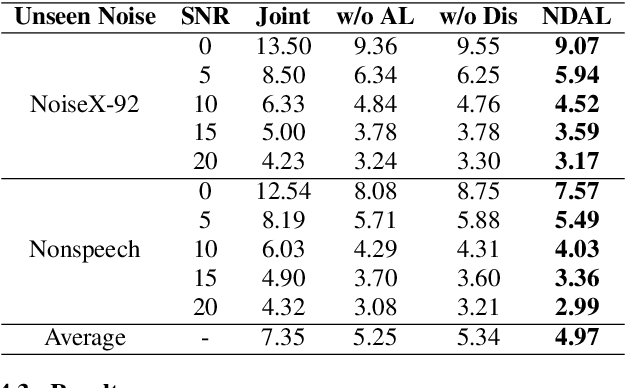
Automatic Speaker Verification (ASV) suffers from performance degradation in noisy conditions. To address this issue, we propose a novel adversarial learning framework that incorporates noise-disentanglement to establish a noise-independent speaker invariant embedding space. Specifically, the disentanglement module includes two encoders for separating speaker related and irrelevant information, respectively. The reconstruction module serves as a regularization term to constrain the noise. A feature-robust loss is also used to supervise the speaker encoder to learn noise-independent speaker embeddings without losing speaker information. In addition, adversarial training is introduced to discourage the speaker encoder from encoding acoustic condition information for achieving a speaker-invariant embedding space. Experiments on VoxCeleb1 indicate that the proposed method improves the performance of the speaker verification system under both clean and noisy conditions.