 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank and Sparse Model Merging for Multi-Lingual Speech Recognition and Translation
Feb 26, 2025Language diversity presents a significant challenge in speech-to-text (S2T) tasks, such as automatic speech recognition and translation. Traditional multi-task training approaches aim to address this by jointly optimizing multiple speech recognition and translation tasks across various languages. While models like Whisper, built on these strategies, demonstrate strong performance, they still face issues of high computational cost, language interference, suboptimal training configurations, and limited extensibility. To overcome these challenges, we introduce LoRS-Merging (low-rank and sparse model merging), a novel technique designed to efficiently integrate models trained on different languages or tasks while preserving performance and reducing computational overhead. LoRS-Merging combines low-rank and sparse pruning to retain essential structures while eliminating redundant parameters, mitigating language and task interference, and enhancing extensibility. Experimental results across a range of languages demonstrate that LoRS-Merging reduces the word error rate by 10% and improves BLEU scores by 4% compared to conventional multi-lingual multi-task training baselines. Our findings suggest that model merging, particularly LoRS-Merging, is a scalable and effective complement to traditional multi-lingual training strategies for S2T applications.
Speaker Adaptation for Quantised End-to-End ASR Models
Aug 07, 2024

End-to-end models have shown superior performance for automatic speech recognition (ASR). However, such models are often very large in size and thus challenging to deploy on resource-constrained edge devices. While quantisation can reduce model sizes, it can lead to increased word error rates (WERs). Although improved quantisation methods were proposed to address the issue of performance degradation, the fact that quantised models deployed on edge devices often target only on a small group of users is under-explored. To this end, we propose personalisation for quantised models (P4Q), a novel strategy that uses speaker adaptation (SA) to improve quantised end-to-end ASR models by fitting them to the characteristics of the target speakers. In this paper, we study the P4Q strategy based on Whisper and Conformer attention-based encoder-decoder (AED) end-to-end ASR models, which leverages a 4-bit block-wise NormalFloat4 (NF4) approach for quantisation and the low-rank adaptation (LoRA) approach for SA. Experimental results on the LibriSpeech and the TED-LIUM 3 corpora show that, with a 7-time reduction in model size and 1% extra speaker-specific parameters, 15.1% and 23.3% relative WER reductions were achieved on quantised Whisper and Conformer AED models respectively, comparing to the full precision models.
SAML: Speaker Adaptive Mixture of LoRA Experts for End-to-End ASR
Jun 28, 2024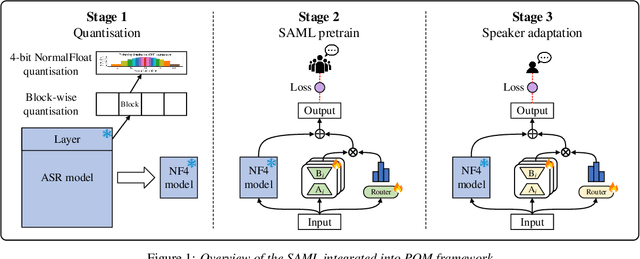



Mixture-of-experts (MoE) models have achieved excellent results in many tasks. However, conventional MoE models are often very large, making them challenging to deploy on resource-constrained edge devices. In this paper, we propose a novel speaker adaptive mixture of LoRA experts (SAML) approach, which uses low-rank adaptation (LoRA) modules as experts to reduce the number of trainable parameters in MoE. Specifically, SAML is applied to the quantised and personalised end-to-end automatic speech recognition models, which combines test-time speaker adaptation to improve the performance of heavily compressed models in speaker-specific scenarios. Experiments have been performed on the LibriSpeech and the TED-LIUM 3 corpora. Remarkably, with a 7x reduction in model size, 29.1% and 31.1% relative word error rate reductions were achieved on the quantised Whisper model and Conformer-based attention-based encoder-decoder ASR model respectively, comparing to the original full precision models.
Enhancing Quantised End-to-End ASR Models via Personalisation
Sep 17, 2023Recent end-to-end automatic speech recognition (ASR) models have become increasingly larger, making them particularly challenging to be deployed on resource-constrained devices. Model quantisation is an effective solution that sometimes causes the word error rate (WER) to increase. In this paper, a novel strategy of personalisation for a quantised model (PQM) is proposed, which combines speaker adaptive training (SAT) with model quantisation to improve the performance of heavily compressed models. Specifically, PQM uses a 4-bit NormalFloat Quantisation (NF4) approach for model quantisation and low-rank adaptation (LoRA) for SAT. Experiments have been performed on the LibriSpeech and the TED-LIUM 3 corpora. Remarkably, with a 7x reduction in model size and 1% additional speaker-specific parameters, 15.1% and 23.3% relative WER reductions were achieved on quantised Whisper and Conformer-based attention-based encoder-decoder ASR models respectively, comparing to the original full precision models.