 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCM-DiffRAG: Personalized Syndrome Differentiation Reasoning Method for Traditional Chinese Medicine based on Knowledge Graph and Chain of Thought
Feb 26, 2026Background: Retrieval augmented generation (RAG) technology can empower large language models (LLMs) to generate more accurate, professional, and timely responses without fine tuning. However, due to the complex reasoning processes and substantial individual differences involved in traditional Chinese medicine (TCM) clinical diagnosis and treatment, traditional RAG methods often exhibit poor performance in this domain. Objective: To address the limitations of conventional RAG approaches in TCM applications, this study aims to develop an improved RAG framework tailored to the characteristics of TCM reasoning. Methods: We developed TCM-DiffRAG, an innovative RAG framework that integrates knowledge graphs (KG) with chains of thought (CoT). TCM-DiffRAG was evaluated on three distinctive TCM test datasets. Results: The experimental results demonstrated that TCM-DiffRAG achieved significant performance improvements over native LLMs. For example, the qwen-plus model achieved scores of 0.927, 0.361, and 0.038, which were significantly enhanced to 0.952, 0.788, and 0.356 with TCM-DiffRAG. The improvements were even more pronounced for non-Chinese LLMs. Additionally, TCM-DiffRAG outperformed directly supervised fine-tuned (SFT) LLMs and other benchmark RAG methods. Conclusions: TCM-DiffRAG shows that integrating structured TCM knowledge graphs with Chain of Thought based reasoning substantially improves performance in individualized diagnostic tasks. The joint use of universal and personalized knowledge graphs enables effective alignment between general knowledge and clinical reasoning. These results highlight the potential of reasoning-aware RAG frameworks for advancing LLM applications in traditional Chinese medicine.
PhaseNAS: Language-Model Driven Architecture Search with Dynamic Phase Adaptation
Jul 28, 2025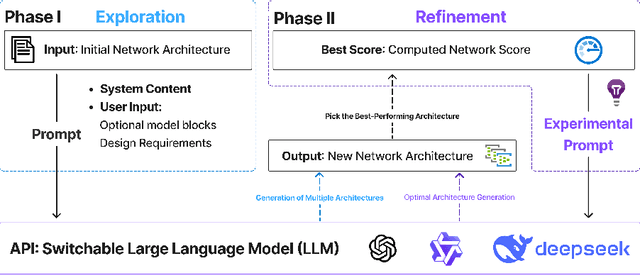
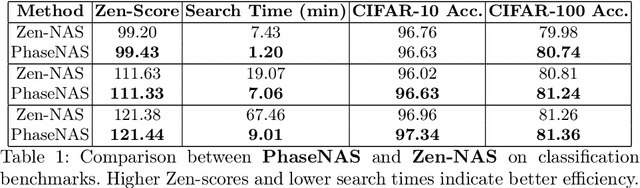
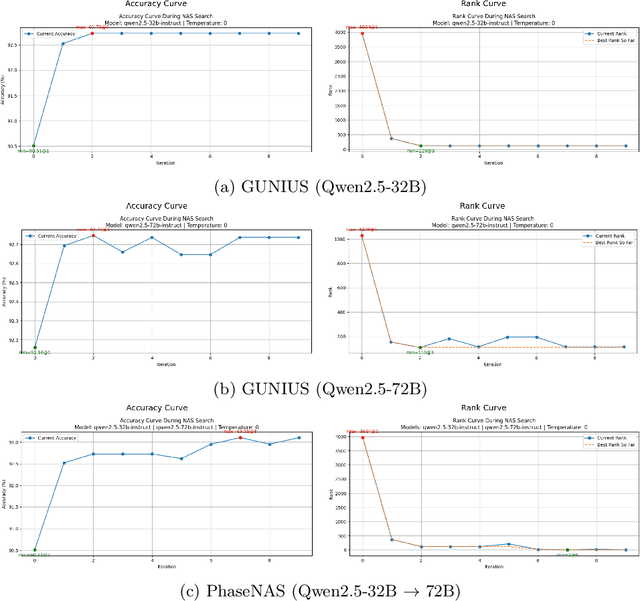
Neural Architecture Search (NAS) is challenged by the trade-off between search space exploration and efficiency, especially for complex tasks. While recent LLM-based NAS methods have shown promise, they often suffer from static search strategies and ambiguous architecture representations. We propose PhaseNAS, an LLM-based NAS framework with dynamic phase transitions guided by real-time score thresholds and a structured architecture template language for consistent code generation. On the NAS-Bench-Macro benchmark, PhaseNAS consistently discovers architectures with higher accuracy and better rank. For image classification (CIFAR-10/100), PhaseNAS reduces search time by up to 86% while maintaining or improving accuracy. In object detection, it automatically produces YOLOv8 variants with higher mAP and lower resource cost. These results demonstrate that PhaseNAS enables efficient, adaptive, and generalizable NAS across diverse vision tasks.
Improving TCM Question Answering through Tree-Organized Self-Reflective Retrieval with LLMs
Feb 13, 2025



Objectives: Large language models (LLMs) can harness medical knowledge for intelligent question answering (Q&A), promising support for auxiliary diagnosis and medical talent cultivation. However, there is a deficiency of highly efficient retrieval-augmented generation (RAG) frameworks within the domain of Traditional Chinese Medicine (TCM). Our purpose is to observe the effect of the Tree-Organized Self-Reflective Retrieval (TOSRR) framework on LLMs in TCM Q&A tasks. Materials and Methods: We introduce the novel approach of knowledge organization, constructing a tree structure knowledge base with hierarchy. At inference time, our self-reflection framework retrieves from this knowledge base, integrating information across chapters. Questions from the TCM Medical Licensing Examination (MLE) and the college Classics Course Exam (CCE) were randomly selected as benchmark datasets. Results: By coupling with GPT-4, the framework can improve the best performance on the TCM MLE benchmark by 19.85% in absolute accuracy, and improve recall accuracy from 27% to 38% on CCE datasets. In manual evaluation, the framework improves a total of 18.52 points across dimensions of safety, consistency, explainability, compliance, and coherence. Conclusion: The TOSRR framework can effectively improve LLM's capability in Q&A tasks of TCM.
Learning Natural Consistency Representation for Face Forgery Video Detection
Jul 15, 2024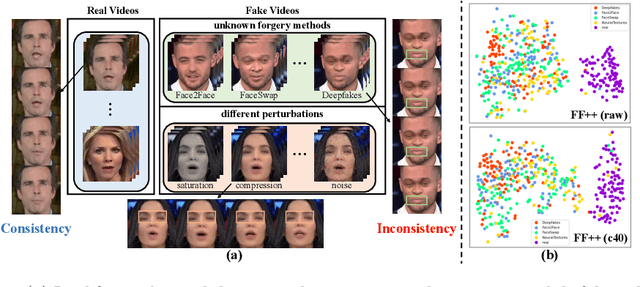
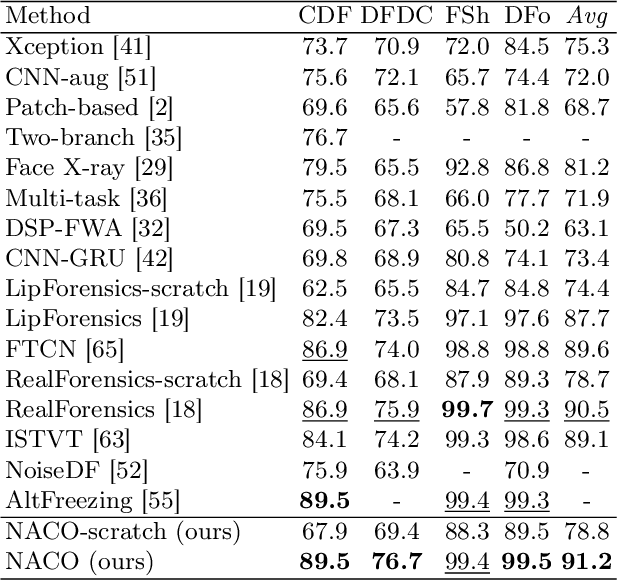
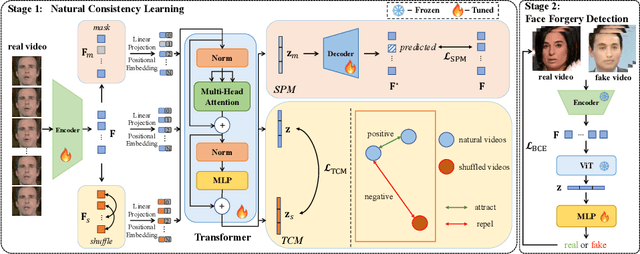
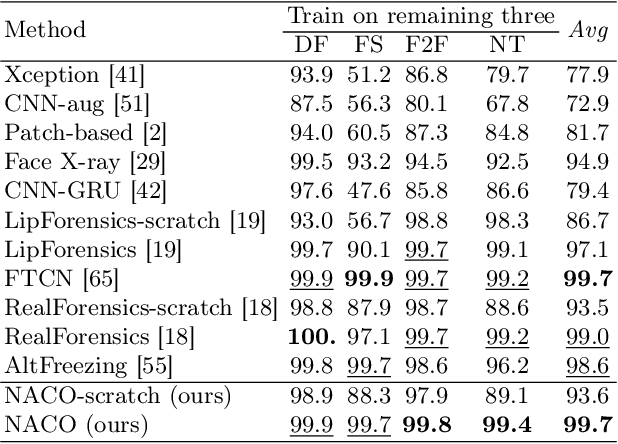
Face Forgery videos have elicited critical social public concerns and various detectors have been proposed. However, fully-supervised detectors may lead to easily overfitting to specific forgery methods or videos, and existing self-supervised detectors are strict on auxiliary tasks, such as requiring audio or multi-modalities, leading to limited generalization and robustness. In this paper, we examine whether we can address this issue by leveraging visual-only real face videos. To this end, we propose to learn the Natural Consistency representation (NACO) of real face videos in a self-supervised manner, which is inspired by the observation that fake videos struggle to maintain the natural spatiotemporal consistency even under unknown forgery methods and different perturbations. Our NACO first extracts spatial features of each frame by CNNs then integrates them into Transformer to learn the long-range spatiotemporal representation, leveraging the advantages of CNNs and Transformer on local spatial receptive field and long-term memory respectively. Furthermore, a Spatial Predictive Module~(SPM) and a Temporal Contrastive Module~(TCM) are introduced to enhance the natural consistency representation learning. The SPM aims to predict random masked spatial features from spatiotemporal representation, and the TCM regularizes the latent distance of spatiotemporal representation by shuffling the natural order to disturb the consistency, which could both force our NACO more sensitive to the natural spatiotemporal consistency. After the representation learning stage, a MLP head is fine-tuned to perform the usual forgery video classification task. Extensive experiments show that our method outperforms other state-of-the-art competitors with impressive generalization and robustness.
Infrared Adversarial Car Stickers
May 16, 2024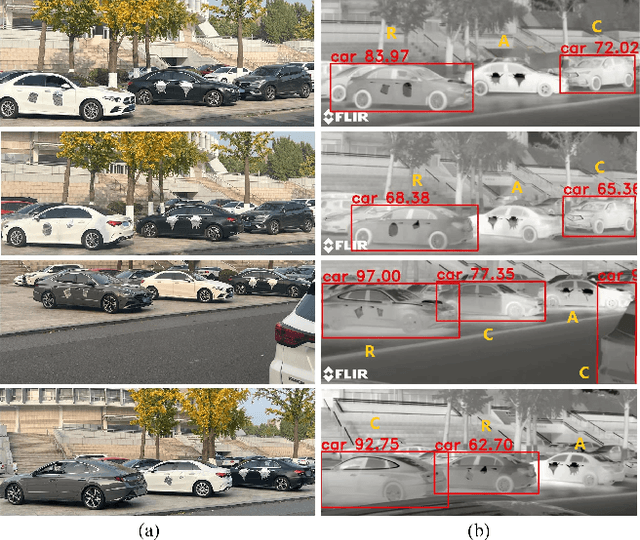
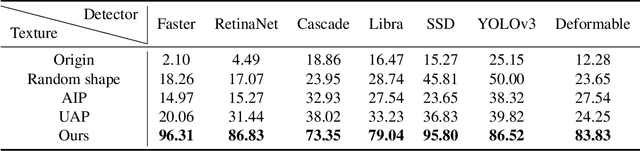
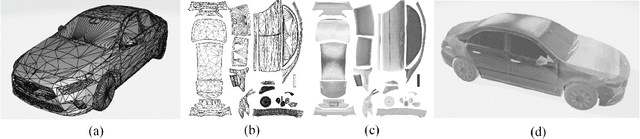
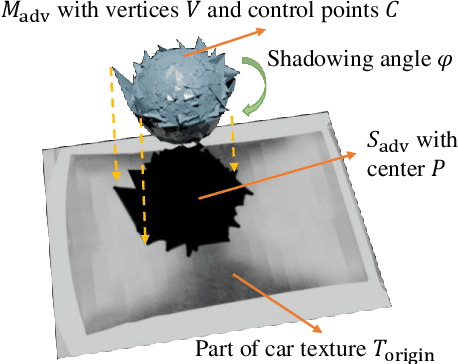
Infrared physical adversarial examples are of great significance for studying the security of infrared AI systems that are widely used in our lives such as autonomous driving. Previous infrared physical attacks mainly focused on 2D infrared pedestrian detection which may not fully manifest its destructiveness to AI systems. In this work, we propose a physical attack method against infrared detectors based on 3D modeling, which is applied to a real car. The goal is to design a set of infrared adversarial stickers to make cars invisible to infrared detectors at various viewing angles, distances, and scenes. We build a 3D infrared car model with real infrared characteristics and propose an infrared adversarial pattern generation method based on 3D mesh shadow. We propose a 3D control points-based mesh smoothing algorithm and use a set of smoothness loss functions to enhance the smoothness of adversarial meshes and facilitate the sticker implementation. Besides, We designed the aluminum stickers and conducted physical experiments on two real Mercedes-Benz A200L cars. Our adversarial stickers hid the cars from Faster RCNN, an object detector, at various viewing angles, distances, and scenes. The attack success rate (ASR) was 91.49% for real cars. In comparison, the ASRs of random stickers and no sticker were only 6.21% and 0.66%, respectively. In addition, the ASRs of the designed stickers against six unseen object detectors such as YOLOv3 and Deformable DETR were between 73.35%-95.80%, showing good transferability of the attack performance across detectors.
SAFDNet: A Simple and Effective Network for Fully Sparse 3D Object Detection
Mar 09, 2024LiDAR-based 3D object detection plays an essential role in autonomous driving. Existing high-performing 3D object detectors usually build dense feature maps in the backbone network and prediction head. However, the computational costs introduced by the dense feature maps grow quadratically as the perception range increases, making these models hard to scale up to long-range detection. Some recent works have attempted to construct fully sparse detectors to solve this issue; nevertheless, the resulting models either rely on a complex multi-stage pipeline or exhibit inferior performance. In this work, we propose SAFDNet, a straightforward yet highly effective architecture, tailored for fully sparse 3D object detection. In SAFDNet, an adaptive feature diffusion strategy is designed to address the center feature missing problem. We conducted extensive experiments on Waymo Open, nuScenes, and Argoverse2 datasets. SAFDNet performed slightly better than the previous SOTA on the first two datasets but much better on the last dataset, which features long-range detection, verifying the efficacy of SAFDNet in scenarios where long-range detection is required. Notably, on Argoverse2, SAFDNet surpassed the previous best hybrid detector HEDNet by 2.6% mAP while being 2.1x faster, and yielded 2.1% mAP gains over the previous best sparse detector FSDv2 while being 1.3x faster. The code will be available at https://github.com/zhanggang001/HEDNet.
InstructPix2NeRF: Instructed 3D Portrait Editing from a Single Image
Nov 06, 2023



With the success of Neural Radiance Field (NeRF) in 3D-aware portrait editing, a variety of works have achieved promising results regarding both quality and 3D consistency. However, these methods heavily rely on per-prompt optimization when handling natural language as editing instructions. Due to the lack of labeled human face 3D datasets and effective architectures, the area of human-instructed 3D-aware editing for open-world portraits in an end-to-end manner remains under-explored. To solve this problem, we propose an end-to-end diffusion-based framework termed InstructPix2NeRF, which enables instructed 3D-aware portrait editing from a single open-world image with human instructions. At its core lies a conditional latent 3D diffusion process that lifts 2D editing to 3D space by learning the correlation between the paired images' difference and the instructions via triplet data. With the help of our proposed token position randomization strategy, we could even achieve multi-semantic editing through one single pass with the portrait identity well-preserved. Besides, we further propose an identity consistency module that directly modulates the extracted identity signals into our diffusion process, which increases the multi-view 3D identity consistency. Extensive experiments verify the effectiveness of our method and show its superiority against strong baselines quantitatively and qualitatively.
HEDNet: A Hierarchical Encoder-Decoder Network for 3D Object Detection in Point Clouds
Oct 31, 20233D object detection in point clouds is important for autonomous driving systems. A primary challenge in 3D object detection stems from the sparse distribution of points within the 3D scene. Existing high-performance methods typically employ 3D sparse convolutional neural networks with small kernels to extract features. To reduce computational costs, these methods resort to submanifold sparse convolutions, which prevent the information exchange among spatially disconnected features. Some recent approaches have attempted to address this problem by introducing large-kernel convolutions or self-attention mechanisms, but they either achieve limited accuracy improvements or incur excessive computational costs. We propose HEDNet, a hierarchical encoder-decoder network for 3D object detection, which leverages encoder-decoder blocks to capture long-range dependencies among features in the spatial space, particularly for large and distant objects. We conducted extensive experiments on the Waymo Open and nuScenes datasets. HEDNet achieved superior detection accuracy on both datasets than previous state-of-the-art methods with competitive efficiency. The code is available at https://github.com/zhanggang001/HEDNet.
Self-Supervised Transformer with Domain Adaptive Reconstruction for General Face Forgery Video Detection
Sep 09, 2023Face forgery videos have caused severe social public concern, and various detectors have been proposed recently. However, most of them are trained in a supervised manner with limited generalization when detecting videos from different forgery methods or real source videos. To tackle this issue, we explore to take full advantage of the difference between real and forgery videos by only exploring the common representation of real face videos. In this paper, a Self-supervised Transformer cooperating with Contrastive and Reconstruction learning (CoReST) is proposed, which is first pre-trained only on real face videos in a self-supervised manner, and then fine-tuned a linear head on specific face forgery video datasets. Two specific auxiliary tasks incorporated contrastive and reconstruction learning are designed to enhance the representation learning. Furthermore, a Domain Adaptive Reconstruction (DAR) module is introduced to bridge the gap between different forgery domains by reconstructing on unlabeled target videos when fine-tuning. Extensive experiments on public datasets demonstrate that our proposed method performs even better than the state-of-the-art supervised competitors with impressive generalization.
PREIM3D: 3D Consistent Precise Image Attribute Editing from a Single Image
Apr 20, 2023
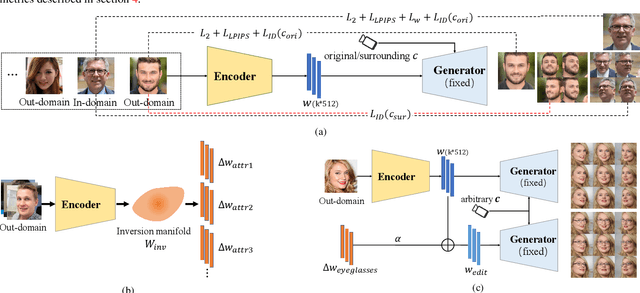
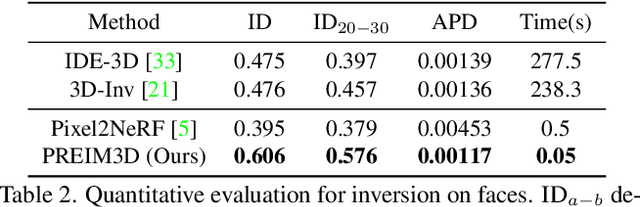
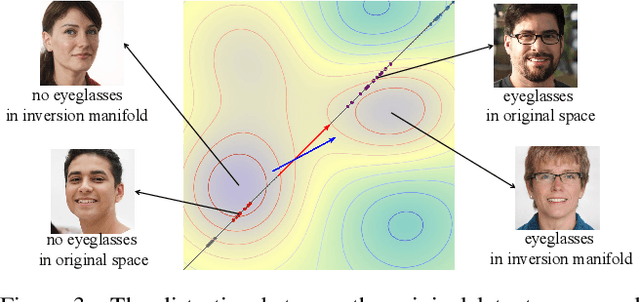
We study the 3D-aware image attribute editing problem in this paper, which has wide applications in practice. Recent methods solved the problem by training a shared encoder to map images into a 3D generator's latent space or by per-image latent code optimization and then edited images in the latent space. Despite their promising results near the input view, they still suffer from the 3D inconsistency of produced images at large camera poses and imprecise image attribute editing, like affecting unspecified attributes during editing. For more efficient image inversion, we train a shared encoder for all images. To alleviate 3D inconsistency at large camera poses, we propose two novel methods, an alternating training scheme and a multi-view identity loss, to maintain 3D consistency and subject identity. As for imprecise image editing, we attribute the problem to the gap between the latent space of real images and that of generated images. We compare the latent space and inversion manifold of GAN models and demonstrate that editing in the inversion manifold can achieve better results in both quantitative and qualitative evaluations. Extensive experiments show that our method produces more 3D consistent images and achieves more precise image editing than previous work. Source code and pretrained models can be found on our project page: https://mybabyyh.github.io/Preim3D/