 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePKI: Prior Knowledge-Infused Neural Network for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) aims to continually adapt a model on a limited number of new-class examples, facing two well-known challenges: catastrophic forgetting and overfitting to new classes. Existing methods tend to freeze more parts of network components and finetune others with an extra memory during incremental sessions. These methods emphasize preserving prior knowledge to ensure proficiency in recognizing old classes, thereby mitigating catastrophic forgetting. Meanwhile, constraining fewer parameters can help in overcoming overfitting with the assistance of prior knowledge. Following previous methods, we retain more prior knowledge and propose a prior knowledge-infused neural network (PKI) to facilitate FSCIL. PKI consists of a backbone, an ensemble of projectors, a classifier, and an extra memory. In each incremental session, we build a new projector and add it to the ensemble. Subsequently, we finetune the new projector and the classifier jointly with other frozen network components, ensuring the rich prior knowledge is utilized effectively. By cascading projectors, PKI integrates prior knowledge accumulated from previous sessions and learns new knowledge flexibly, which helps to recognize old classes and efficiently learn new classes. Further, to reduce the resource consumption associated with keeping many projectors, we design two variants of the prior knowledge-infused neural network (PKIV-1 and PKIV-2) to trade off a balance between resource consumption and performance by reducing the number of projectors. Extensive experiments on three popular benchmarks demonstrate that our approach outperforms state-of-the-art methods.
Learning Natural Consistency Representation for Face Forgery Video Detection
Jul 15, 2024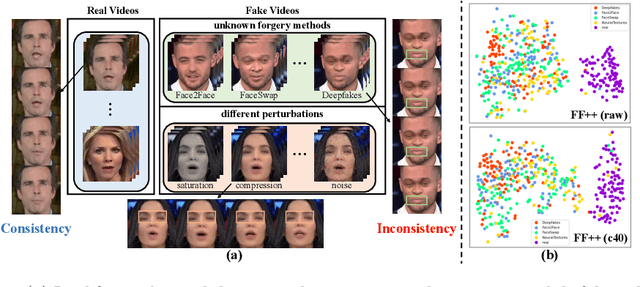
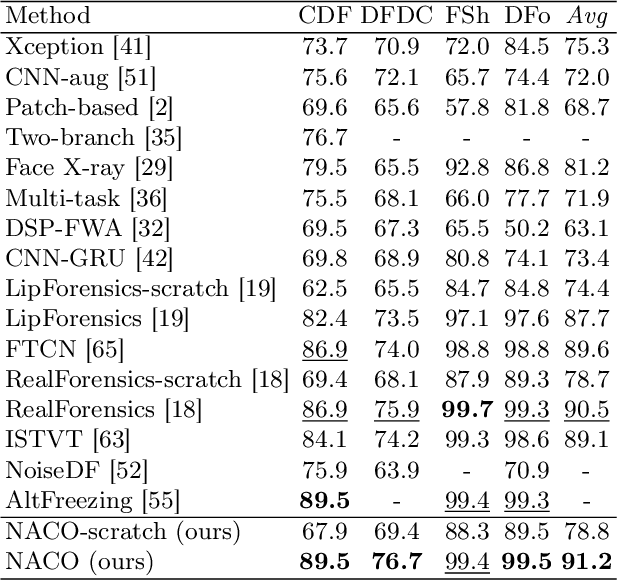
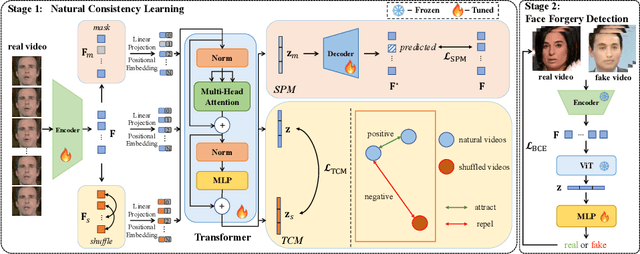
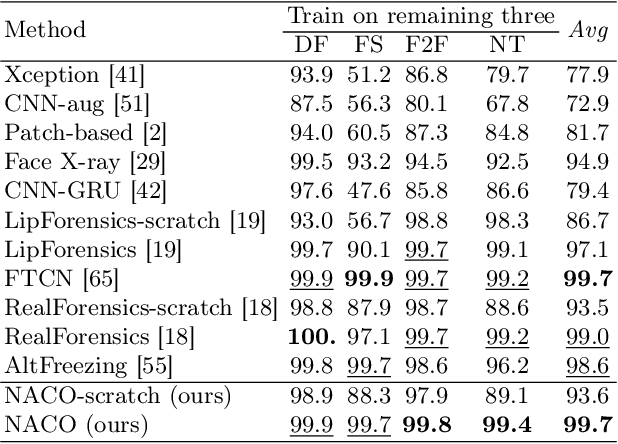
Face Forgery videos have elicited critical social public concerns and various detectors have been proposed. However, fully-supervised detectors may lead to easily overfitting to specific forgery methods or videos, and existing self-supervised detectors are strict on auxiliary tasks, such as requiring audio or multi-modalities, leading to limited generalization and robustness. In this paper, we examine whether we can address this issue by leveraging visual-only real face videos. To this end, we propose to learn the Natural Consistency representation (NACO) of real face videos in a self-supervised manner, which is inspired by the observation that fake videos struggle to maintain the natural spatiotemporal consistency even under unknown forgery methods and different perturbations. Our NACO first extracts spatial features of each frame by CNNs then integrates them into Transformer to learn the long-range spatiotemporal representation, leveraging the advantages of CNNs and Transformer on local spatial receptive field and long-term memory respectively. Furthermore, a Spatial Predictive Module~(SPM) and a Temporal Contrastive Module~(TCM) are introduced to enhance the natural consistency representation learning. The SPM aims to predict random masked spatial features from spatiotemporal representation, and the TCM regularizes the latent distance of spatiotemporal representation by shuffling the natural order to disturb the consistency, which could both force our NACO more sensitive to the natural spatiotemporal consistency. After the representation learning stage, a MLP head is fine-tuned to perform the usual forgery video classification task. Extensive experiments show that our method outperforms other state-of-the-art competitors with impressive generalization and robustness.
DANCE: Dual-View Distribution Alignment for Dataset Condensation
Jun 03, 2024



Dataset condensation addresses the problem of data burden by learning a small synthetic training set that preserves essential knowledge from the larger real training set. To date, the state-of-the-art (SOTA) results are often yielded by optimization-oriented methods, but their inefficiency hinders their application to realistic datasets. On the other hand, the Distribution-Matching (DM) methods show remarkable efficiency but sub-optimal results compared to optimization-oriented methods. In this paper, we reveal the limitations of current DM-based methods from the inner-class and inter-class views, i.e., Persistent Training and Distribution Shift. To address these problems, we propose a new DM-based method named Dual-view distribution AligNment for dataset CondEnsation (DANCE), which exploits a few pre-trained models to improve DM from both inner-class and inter-class views. Specifically, from the inner-class view, we construct multiple "middle encoders" to perform pseudo long-term distribution alignment, making the condensed set a good proxy of the real one during the whole training process; while from the inter-class view, we use the expert models to perform distribution calibration, ensuring the synthetic data remains in the real class region during condensing. Experiments demonstrate the proposed method achieves a SOTA performance while maintaining comparable efficiency with the original DM across various scenarios. Source codes are available at https://github.com/Hansong-Zhang/DANCE.
Deepfake Video Detection with Spatiotemporal Dropout Transformer
Jul 14, 2022
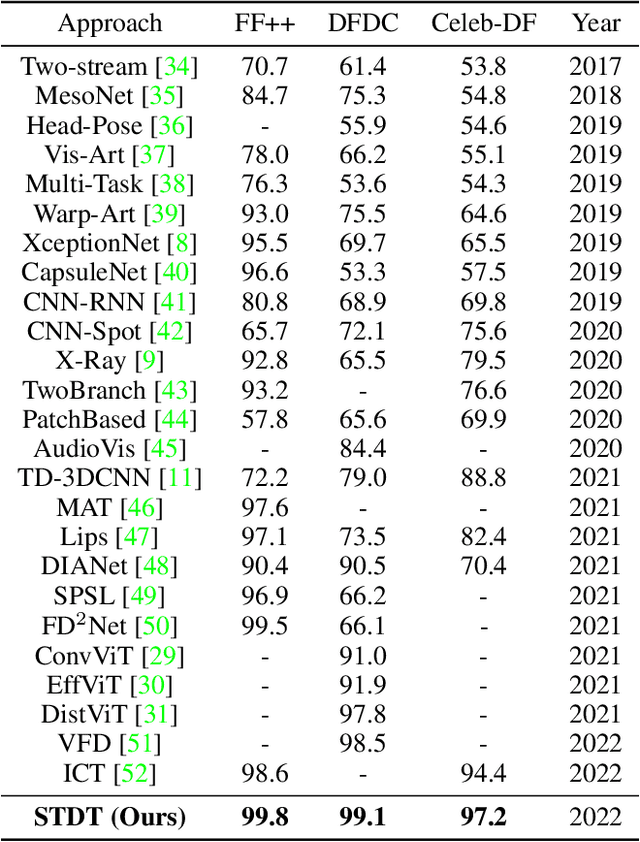
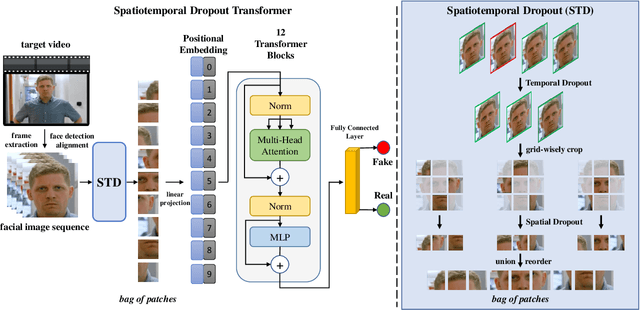
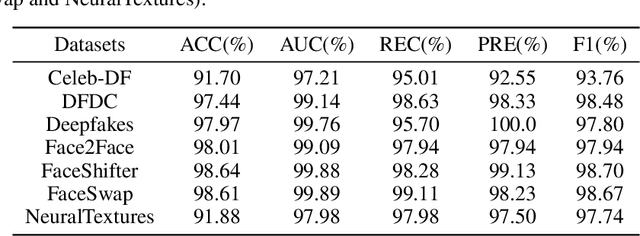
While the abuse of deepfake technology has caused serious concerns recently, how to detect deepfake videos is still a challenge due to the high photo-realistic synthesis of each frame. Existing image-level approaches often focus on single frame and ignore the spatiotemporal cues hidden in deepfake videos, resulting in poor generalization and robustness. The key of a video-level detector is to fully exploit the spatiotemporal inconsistency distributed in local facial regions across different frames in deepfake videos. Inspired by that, this paper proposes a simple yet effective patch-level approach to facilitate deepfake video detection via spatiotemporal dropout transformer. The approach reorganizes each input video into bag of patches that is then fed into a vision transformer to achieve robust representation. Specifically, a spatiotemporal dropout operation is proposed to fully explore patch-level spatiotemporal cues and serve as effective data augmentation to further enhance model's robustness and generalization ability. The operation is flexible and can be easily plugged into existing vision transformers. Extensive experiments demonstrate the effectiveness of our approach against 25 state-of-the-arts with impressive robustness, generalizability, and representation ability.