 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCD^2: Constrained Dataset Distillation for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) receives significant attention from the public to perform classification continuously with a few training samples, which suffers from the key catastrophic forgetting problem. Existing methods usually employ an external memory to store previous knowledge and treat it with incremental classes equally, which cannot properly preserve previous essential knowledge. To solve this problem and inspired by recent distillation works on knowledge transfer, we propose a framework termed \textbf{C}onstrained \textbf{D}ataset \textbf{D}istillation (\textbf{CD$^2$}) to facilitate FSCIL, which includes a dataset distillation module (\textbf{DDM}) and a distillation constraint module~(\textbf{DCM}). Specifically, the DDM synthesizes highly condensed samples guided by the classifier, forcing the model to learn compacted essential class-related clues from a few incremental samples. The DCM introduces a designed loss to constrain the previously learned class distribution, which can preserve distilled knowledge more sufficiently. Extensive experiments on three public datasets show the superiority of our method against other state-of-the-art competitors.
Divide and Conquer: Static-Dynamic Collaboration for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) aims to continuously recognize novel classes under limited data, which suffers from the key stability-plasticity dilemma: balancing the retention of old knowledge with the acquisition of new knowledge. To address this issue, we divide the task into two different stages and propose a framework termed Static-Dynamic Collaboration (SDC) to achieve a better trade-off between stability and plasticity. Specifically, our method divides the normal pipeline of FSCIL into Static Retaining Stage (SRS) and Dynamic Learning Stage (DLS), which harnesses old static and incremental dynamic class information, respectively. During SRS, we train an initial model with sufficient data in the base session and preserve the key part as static memory to retain fundamental old knowledge. During DLS, we introduce an extra dynamic projector jointly trained with the previous static memory. By employing both stages, our method achieves improved retention of old knowledge while continuously adapting to new classes. Extensive experiments on three public benchmarks and a real-world application dataset demonstrate that our method achieves state-of-the-art performance against other competitors.
Learning Natural Consistency Representation for Face Forgery Video Detection
Jul 15, 2024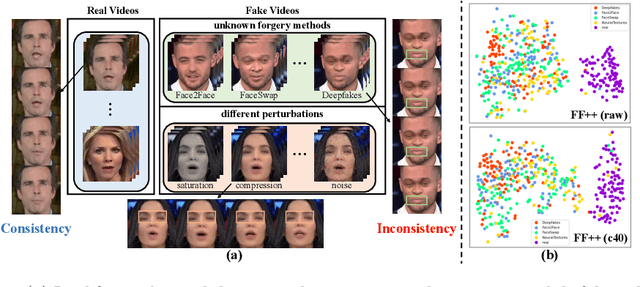
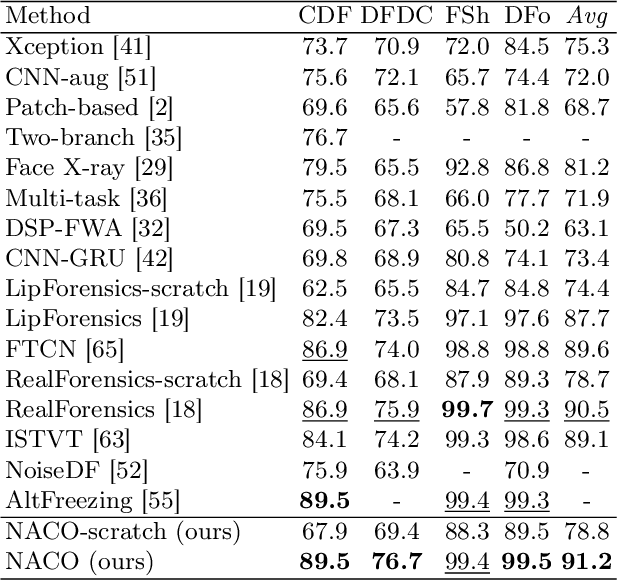
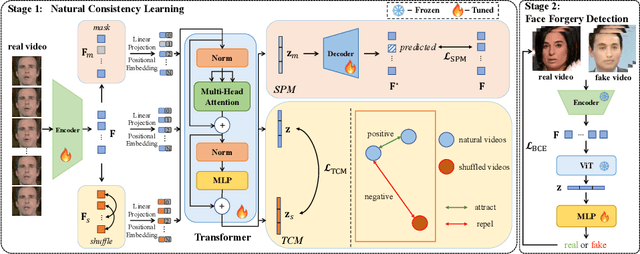
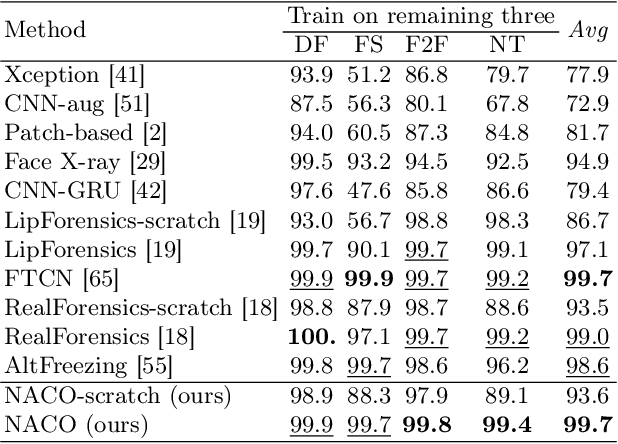
Face Forgery videos have elicited critical social public concerns and various detectors have been proposed. However, fully-supervised detectors may lead to easily overfitting to specific forgery methods or videos, and existing self-supervised detectors are strict on auxiliary tasks, such as requiring audio or multi-modalities, leading to limited generalization and robustness. In this paper, we examine whether we can address this issue by leveraging visual-only real face videos. To this end, we propose to learn the Natural Consistency representation (NACO) of real face videos in a self-supervised manner, which is inspired by the observation that fake videos struggle to maintain the natural spatiotemporal consistency even under unknown forgery methods and different perturbations. Our NACO first extracts spatial features of each frame by CNNs then integrates them into Transformer to learn the long-range spatiotemporal representation, leveraging the advantages of CNNs and Transformer on local spatial receptive field and long-term memory respectively. Furthermore, a Spatial Predictive Module~(SPM) and a Temporal Contrastive Module~(TCM) are introduced to enhance the natural consistency representation learning. The SPM aims to predict random masked spatial features from spatiotemporal representation, and the TCM regularizes the latent distance of spatiotemporal representation by shuffling the natural order to disturb the consistency, which could both force our NACO more sensitive to the natural spatiotemporal consistency. After the representation learning stage, a MLP head is fine-tuned to perform the usual forgery video classification task. Extensive experiments show that our method outperforms other state-of-the-art competitors with impressive generalization and robustness.
Self-Supervised Transformer with Domain Adaptive Reconstruction for General Face Forgery Video Detection
Sep 09, 2023Face forgery videos have caused severe social public concern, and various detectors have been proposed recently. However, most of them are trained in a supervised manner with limited generalization when detecting videos from different forgery methods or real source videos. To tackle this issue, we explore to take full advantage of the difference between real and forgery videos by only exploring the common representation of real face videos. In this paper, a Self-supervised Transformer cooperating with Contrastive and Reconstruction learning (CoReST) is proposed, which is first pre-trained only on real face videos in a self-supervised manner, and then fine-tuned a linear head on specific face forgery video datasets. Two specific auxiliary tasks incorporated contrastive and reconstruction learning are designed to enhance the representation learning. Furthermore, a Domain Adaptive Reconstruction (DAR) module is introduced to bridge the gap between different forgery domains by reconstructing on unlabeled target videos when fine-tuning. Extensive experiments on public datasets demonstrate that our proposed method performs even better than the state-of-the-art supervised competitors with impressive generalization.
Deepfake Video Detection with Spatiotemporal Dropout Transformer
Jul 14, 2022
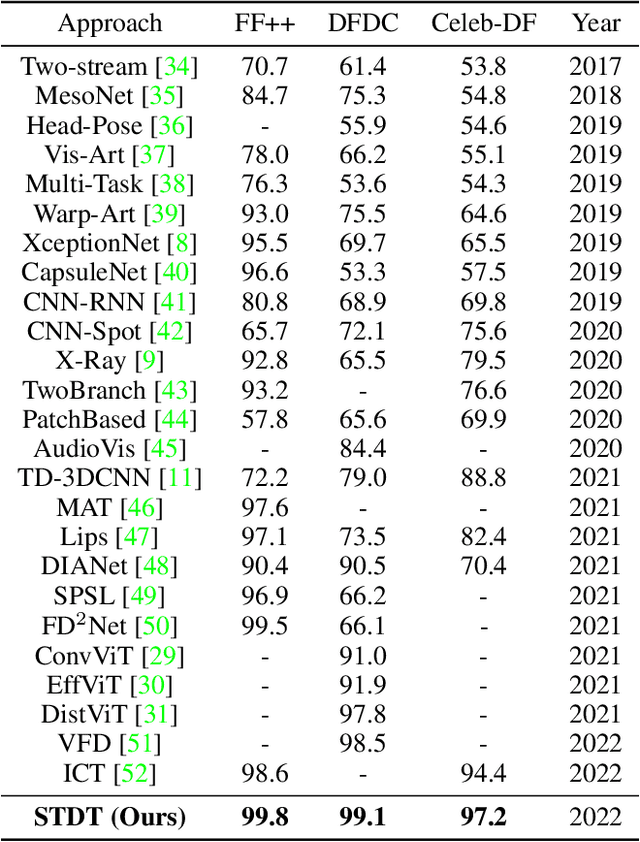
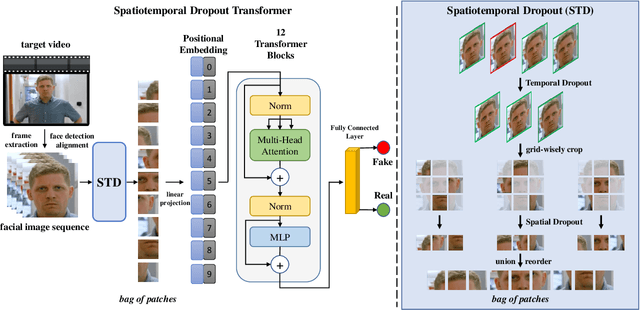
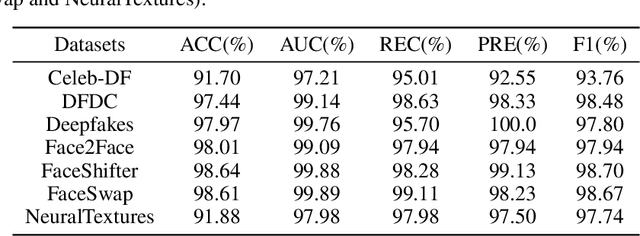
While the abuse of deepfake technology has caused serious concerns recently, how to detect deepfake videos is still a challenge due to the high photo-realistic synthesis of each frame. Existing image-level approaches often focus on single frame and ignore the spatiotemporal cues hidden in deepfake videos, resulting in poor generalization and robustness. The key of a video-level detector is to fully exploit the spatiotemporal inconsistency distributed in local facial regions across different frames in deepfake videos. Inspired by that, this paper proposes a simple yet effective patch-level approach to facilitate deepfake video detection via spatiotemporal dropout transformer. The approach reorganizes each input video into bag of patches that is then fed into a vision transformer to achieve robust representation. Specifically, a spatiotemporal dropout operation is proposed to fully explore patch-level spatiotemporal cues and serve as effective data augmentation to further enhance model's robustness and generalization ability. The operation is flexible and can be easily plugged into existing vision transformers. Extensive experiments demonstrate the effectiveness of our approach against 25 state-of-the-arts with impressive robustness, generalizability, and representation ability.
Interpretable Face Manipulation Detection via Feature Whitening
Jun 21, 2021
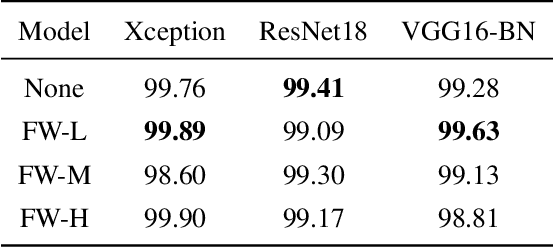
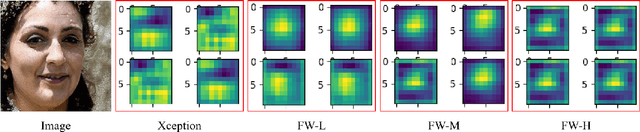
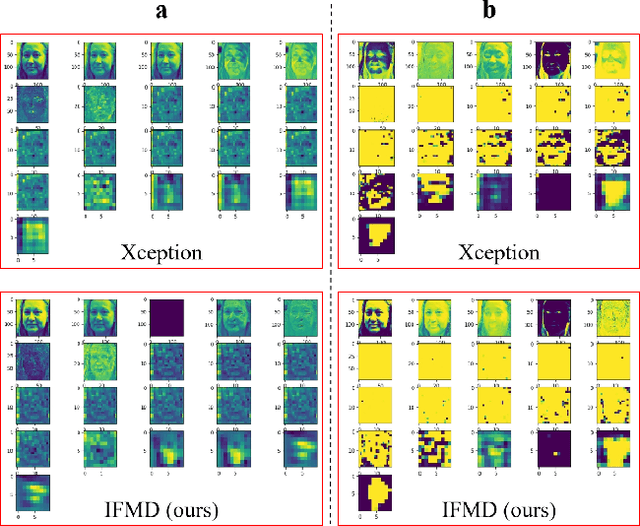
Why should we trust the detections of deep neural networks for manipulated faces? Understanding the reasons is important for users in improving the fairness, reliability, privacy and trust of the detection models. In this work, we propose an interpretable face manipulation detection approach to achieve the trustworthy and accurate inference. The approach could make the face manipulation detection process transparent by embedding the feature whitening module. This module aims to whiten the internal working mechanism of deep networks through feature decorrelation and feature constraint. The experimental results demonstrate that our proposed approach can strike a balance between the detection accuracy and the model interpretability.