Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Face Manipulation Detection via Feature Whitening
Paper and Code
Jun 21, 2021
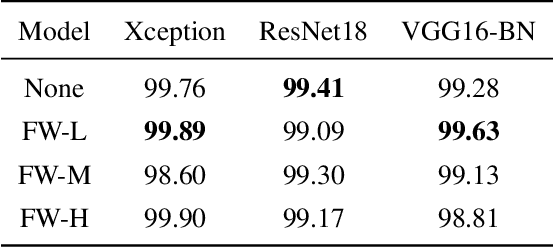
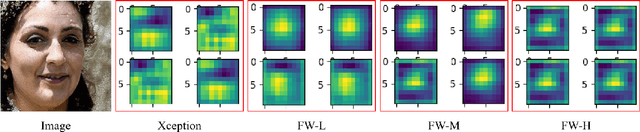
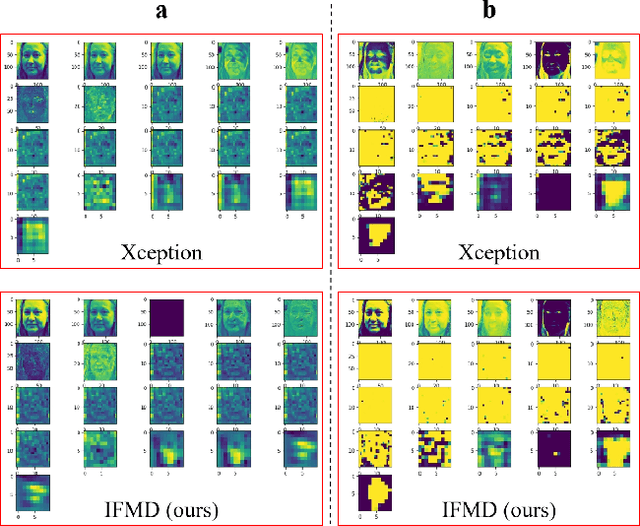
Why should we trust the detections of deep neural networks for manipulated faces? Understanding the reasons is important for users in improving the fairness, reliability, privacy and trust of the detection models. In this work, we propose an interpretable face manipulation detection approach to achieve the trustworthy and accurate inference. The approach could make the face manipulation detection process transparent by embedding the feature whitening module. This module aims to whiten the internal working mechanism of deep networks through feature decorrelation and feature constraint. The experimental results demonstrate that our proposed approach can strike a balance between the detection accuracy and the model interpretability.
View paper on