 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Model Transcription with Differentially Private Synthetic Distillation
Jan 27, 2026While many deep learning models trained on private datasets have been deployed in various practical tasks, they may pose a privacy leakage risk as attackers could recover informative data or label knowledge from models. In this work, we present \emph{privacy-preserving model transcription}, a data-free model-to-model conversion solution to facilitate model deployment with a privacy guarantee. To this end, we propose a cooperative-competitive learning approach termed \emph{differentially private synthetic distillation} that learns to convert a pretrained model (teacher) into its privacy-preserving counterpart (student) via a trainable generator without access to private data. The learning collaborates with three players in a unified framework and performs alternate optimization: i)~the generator is learned to generate synthetic data, ii)~the teacher and student accept the synthetic data and compute differential private labels by flexible data or label noisy perturbation, and iii)~the student is updated with noisy labels and the generator is updated by taking the student as a discriminator for adversarial training. We theoretically prove that our approach can guarantee differential privacy and convergence. The transcribed student has good performance and privacy protection, while the resulting generator can generate private synthetic data for downstream tasks. Extensive experiments clearly demonstrate that our approach outperforms 26 state-of-the-arts.
PKI: Prior Knowledge-Infused Neural Network for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) aims to continually adapt a model on a limited number of new-class examples, facing two well-known challenges: catastrophic forgetting and overfitting to new classes. Existing methods tend to freeze more parts of network components and finetune others with an extra memory during incremental sessions. These methods emphasize preserving prior knowledge to ensure proficiency in recognizing old classes, thereby mitigating catastrophic forgetting. Meanwhile, constraining fewer parameters can help in overcoming overfitting with the assistance of prior knowledge. Following previous methods, we retain more prior knowledge and propose a prior knowledge-infused neural network (PKI) to facilitate FSCIL. PKI consists of a backbone, an ensemble of projectors, a classifier, and an extra memory. In each incremental session, we build a new projector and add it to the ensemble. Subsequently, we finetune the new projector and the classifier jointly with other frozen network components, ensuring the rich prior knowledge is utilized effectively. By cascading projectors, PKI integrates prior knowledge accumulated from previous sessions and learns new knowledge flexibly, which helps to recognize old classes and efficiently learn new classes. Further, to reduce the resource consumption associated with keeping many projectors, we design two variants of the prior knowledge-infused neural network (PKIV-1 and PKIV-2) to trade off a balance between resource consumption and performance by reducing the number of projectors. Extensive experiments on three popular benchmarks demonstrate that our approach outperforms state-of-the-art methods.
CD^2: Constrained Dataset Distillation for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) receives significant attention from the public to perform classification continuously with a few training samples, which suffers from the key catastrophic forgetting problem. Existing methods usually employ an external memory to store previous knowledge and treat it with incremental classes equally, which cannot properly preserve previous essential knowledge. To solve this problem and inspired by recent distillation works on knowledge transfer, we propose a framework termed \textbf{C}onstrained \textbf{D}ataset \textbf{D}istillation (\textbf{CD$^2$}) to facilitate FSCIL, which includes a dataset distillation module (\textbf{DDM}) and a distillation constraint module~(\textbf{DCM}). Specifically, the DDM synthesizes highly condensed samples guided by the classifier, forcing the model to learn compacted essential class-related clues from a few incremental samples. The DCM introduces a designed loss to constrain the previously learned class distribution, which can preserve distilled knowledge more sufficiently. Extensive experiments on three public datasets show the superiority of our method against other state-of-the-art competitors.
Divide and Conquer: Static-Dynamic Collaboration for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) aims to continuously recognize novel classes under limited data, which suffers from the key stability-plasticity dilemma: balancing the retention of old knowledge with the acquisition of new knowledge. To address this issue, we divide the task into two different stages and propose a framework termed Static-Dynamic Collaboration (SDC) to achieve a better trade-off between stability and plasticity. Specifically, our method divides the normal pipeline of FSCIL into Static Retaining Stage (SRS) and Dynamic Learning Stage (DLS), which harnesses old static and incremental dynamic class information, respectively. During SRS, we train an initial model with sufficient data in the base session and preserve the key part as static memory to retain fundamental old knowledge. During DLS, we introduce an extra dynamic projector jointly trained with the previous static memory. By employing both stages, our method achieves improved retention of old knowledge while continuously adapting to new classes. Extensive experiments on three public benchmarks and a real-world application dataset demonstrate that our method achieves state-of-the-art performance against other competitors.
How Far are Modern Trackers from UAV-Anti-UAV? A Million-Scale Benchmark and New Baseline
Dec 08, 2025Unmanned Aerial Vehicles (UAVs) offer wide-ranging applications but also pose significant safety and privacy violation risks in areas like airport and infrastructure inspection, spurring the rapid development of Anti-UAV technologies in recent years. However, current Anti-UAV research primarily focuses on RGB, infrared (IR), or RGB-IR videos captured by fixed ground cameras, with little attention to tracking target UAVs from another moving UAV platform. To fill this gap, we propose a new multi-modal visual tracking task termed UAV-Anti-UAV, which involves a pursuer UAV tracking a target adversarial UAV in the video stream. Compared to existing Anti-UAV tasks, UAV-Anti-UAV is more challenging due to severe dual-dynamic disturbances caused by the rapid motion of both the capturing platform and the target. To advance research in this domain, we construct a million-scale dataset consisting of 1,810 videos, each manually annotated with bounding boxes, a language prompt, and 15 tracking attributes. Furthermore, we propose MambaSTS, a Mamba-based baseline method for UAV-Anti-UAV tracking, which enables integrated spatial-temporal-semantic learning. Specifically, we employ Mamba and Transformer models to learn global semantic and spatial features, respectively, and leverage the state space model's strength in long-sequence modeling to establish video-level long-term context via a temporal token propagation mechanism. We conduct experiments on the UAV-Anti-UAV dataset to validate the effectiveness of our method. A thorough experimental evaluation of 50 modern deep tracking algorithms demonstrates that there is still significant room for improvement in the UAV-Anti-UAV domain. The dataset and codes will be available at {\color{magenta}https://github.com/983632847/Awesome-Multimodal-Object-Tracking}.
COST: Contrastive One-Stage Transformer for Vision-Language Small Object Tracking
Apr 02, 2025Transformer has recently demonstrated great potential in improving vision-language (VL) tracking algorithms. However, most of the existing VL trackers rely on carefully designed mechanisms to perform the multi-stage multi-modal fusion. Additionally, direct multi-modal fusion without alignment ignores distribution discrepancy between modalities in feature space, potentially leading to suboptimal representations. In this work, we propose COST, a contrastive one-stage transformer fusion framework for VL tracking, aiming to learn semantically consistent and unified VL representations. Specifically, we introduce a contrastive alignment strategy that maximizes mutual information (MI) between a video and its corresponding language description. This enables effective cross-modal alignment, yielding semantically consistent features in the representation space. By leveraging a visual-linguistic transformer, we establish an efficient multi-modal fusion and reasoning mechanism, empirically demonstrating that a simple stack of transformer encoders effectively enables unified VL representations. Moreover, we contribute a newly collected VL tracking benchmark dataset for small object tracking, named VL-SOT500, with bounding boxes and language descriptions. Our dataset comprises two challenging subsets, VL-SOT230 and VL-SOT270, dedicated to evaluating generic and high-speed small object tracking, respectively. Small object tracking is notoriously challenging due to weak appearance and limited features, and this dataset is, to the best of our knowledge, the first to explore the usage of language cues to enhance visual representation for small object tracking. Extensive experiments demonstrate that COST achieves state-of-the-art performance on five existing VL tracking datasets, as well as on our proposed VL-SOT500 dataset. Source codes and dataset will be made publicly available.
Efficient Low-Resolution Face Recognition via Bridge Distillation
Sep 18, 2024Face recognition in the wild is now advancing towards light-weight models, fast inference speed and resolution-adapted capability. In this paper, we propose a bridge distillation approach to turn a complex face model pretrained on private high-resolution faces into a light-weight one for low-resolution face recognition. In our approach, such a cross-dataset resolution-adapted knowledge transfer problem is solved via two-step distillation. In the first step, we conduct cross-dataset distillation to transfer the prior knowledge from private high-resolution faces to public high-resolution faces and generate compact and discriminative features. In the second step, the resolution-adapted distillation is conducted to further transfer the prior knowledge to synthetic low-resolution faces via multi-task learning. By learning low-resolution face representations and mimicking the adapted high-resolution knowledge, a light-weight student model can be constructed with high efficiency and promising accuracy in recognizing low-resolution faces. Experimental results show that the student model performs impressively in recognizing low-resolution faces with only 0.21M parameters and 0.057MB memory. Meanwhile, its speed reaches up to 14,705, ~934 and 763 faces per second on GPU, CPU and mobile phone, respectively.
* This paper is published in IEEE TIP 2020
Distilling Channels for Efficient Deep Tracking
Sep 18, 2024
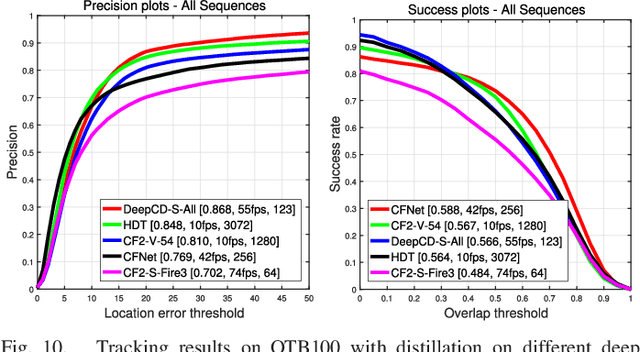

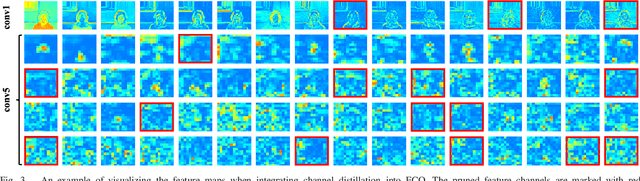
Deep trackers have proven success in visual tracking. Typically, these trackers employ optimally pre-trained deep networks to represent all diverse objects with multi-channel features from some fixed layers. The deep networks employed are usually trained to extract rich knowledge from massive data used in object classification and so they are capable to represent generic objects very well. However, these networks are too complex to represent a specific moving object, leading to poor generalization as well as high computational and memory costs. This paper presents a novel and general framework termed channel distillation to facilitate deep trackers. To validate the effectiveness of channel distillation, we take discriminative correlation filter (DCF) and ECO for example. We demonstrate that an integrated formulation can turn feature compression, response map generation, and model update into a unified energy minimization problem to adaptively select informative feature channels that improve the efficacy of tracking moving objects on the fly. Channel distillation can accurately extract good channels, alleviating the influence of noisy channels and generally reducing the number of channels, as well as adaptively generalizing to different channels and networks. The resulting deep tracker is accurate, fast, and has low memory requirements. Extensive experimental evaluations on popular benchmarks clearly demonstrate the effectiveness and generalizability of our framework.
Distilling Generative-Discriminative Representations for Very Low-Resolution Face Recognition
Sep 10, 2024



Very low-resolution face recognition is challenging due to the serious loss of informative facial details in resolution degradation. In this paper, we propose a generative-discriminative representation distillation approach that combines generative representation with cross-resolution aligned knowledge distillation. This approach facilitates very low-resolution face recognition by jointly distilling generative and discriminative models via two distillation modules. Firstly, the generative representation distillation takes the encoder of a diffusion model pretrained for face super-resolution as the generative teacher to supervise the learning of the student backbone via feature regression, and then freezes the student backbone. After that, the discriminative representation distillation further considers a pretrained face recognizer as the discriminative teacher to supervise the learning of the student head via cross-resolution relational contrastive distillation. In this way, the general backbone representation can be transformed into discriminative head representation, leading to a robust and discriminative student model for very low-resolution face recognition. Our approach improves the recovery of the missing details in very low-resolution faces and achieves better knowledge transfer. Extensive experiments on face datasets demonstrate that our approach enhances the recognition accuracy of very low-resolution faces, showcasing its effectiveness and adaptability.
Look One and More: Distilling Hybrid Order Relational Knowledge for Cross-Resolution Image Recognition
Sep 09, 2024



In spite of great success in many image recognition tasks achieved by recent deep models, directly applying them to recognize low-resolution images may suffer from low accuracy due to the missing of informative details during resolution degradation. However, these images are still recognizable for subjects who are familiar with the corresponding high-resolution ones. Inspired by that, we propose a teacher-student learning approach to facilitate low-resolution image recognition via hybrid order relational knowledge distillation. The approach refers to three streams: the teacher stream is pretrained to recognize high-resolution images in high accuracy, the student stream is learned to identify low-resolution images by mimicking the teacher's behaviors, and the extra assistant stream is introduced as bridge to help knowledge transfer across the teacher to the student. To extract sufficient knowledge for reducing the loss in accuracy, the learning of student is supervised with multiple losses, which preserves the similarities in various order relational structures. In this way, the capability of recovering missing details of familiar low-resolution images can be effectively enhanced, leading to a better knowledge transfer. Extensive experiments on metric learning, low-resolution image classification and low-resolution face recognition tasks show the effectiveness of our approach, while taking reduced models.