 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Channels for Efficient Deep Tracking
Sep 18, 2024
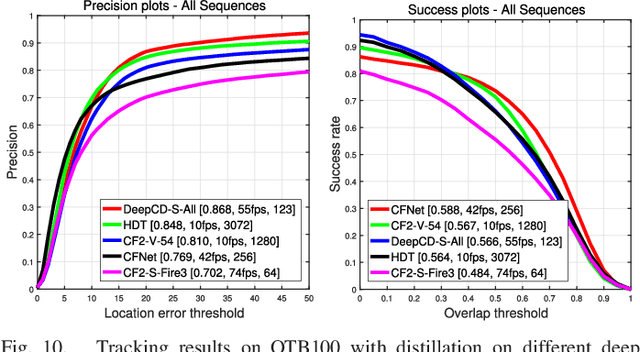

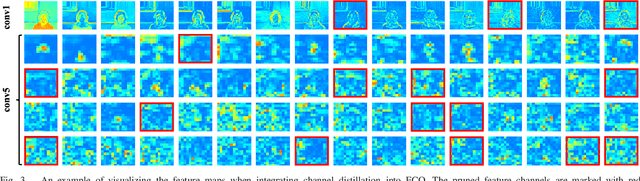
Deep trackers have proven success in visual tracking. Typically, these trackers employ optimally pre-trained deep networks to represent all diverse objects with multi-channel features from some fixed layers. The deep networks employed are usually trained to extract rich knowledge from massive data used in object classification and so they are capable to represent generic objects very well. However, these networks are too complex to represent a specific moving object, leading to poor generalization as well as high computational and memory costs. This paper presents a novel and general framework termed channel distillation to facilitate deep trackers. To validate the effectiveness of channel distillation, we take discriminative correlation filter (DCF) and ECO for example. We demonstrate that an integrated formulation can turn feature compression, response map generation, and model update into a unified energy minimization problem to adaptively select informative feature channels that improve the efficacy of tracking moving objects on the fly. Channel distillation can accurately extract good channels, alleviating the influence of noisy channels and generally reducing the number of channels, as well as adaptively generalizing to different channels and networks. The resulting deep tracker is accurate, fast, and has low memory requirements. Extensive experimental evaluations on popular benchmarks clearly demonstrate the effectiveness and generalizability of our framework.
Look One and More: Distilling Hybrid Order Relational Knowledge for Cross-Resolution Image Recognition
Sep 09, 2024



In spite of great success in many image recognition tasks achieved by recent deep models, directly applying them to recognize low-resolution images may suffer from low accuracy due to the missing of informative details during resolution degradation. However, these images are still recognizable for subjects who are familiar with the corresponding high-resolution ones. Inspired by that, we propose a teacher-student learning approach to facilitate low-resolution image recognition via hybrid order relational knowledge distillation. The approach refers to three streams: the teacher stream is pretrained to recognize high-resolution images in high accuracy, the student stream is learned to identify low-resolution images by mimicking the teacher's behaviors, and the extra assistant stream is introduced as bridge to help knowledge transfer across the teacher to the student. To extract sufficient knowledge for reducing the loss in accuracy, the learning of student is supervised with multiple losses, which preserves the similarities in various order relational structures. In this way, the capability of recovering missing details of familiar low-resolution images can be effectively enhanced, leading to a better knowledge transfer. Extensive experiments on metric learning, low-resolution image classification and low-resolution face recognition tasks show the effectiveness of our approach, while taking reduced models.
Deepfake Video Detection with Spatiotemporal Dropout Transformer
Jul 14, 2022
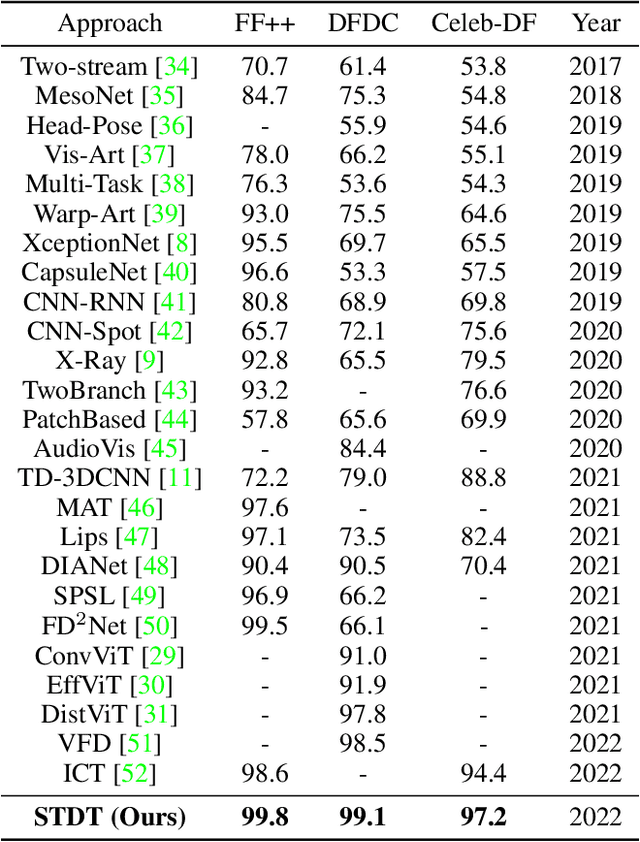
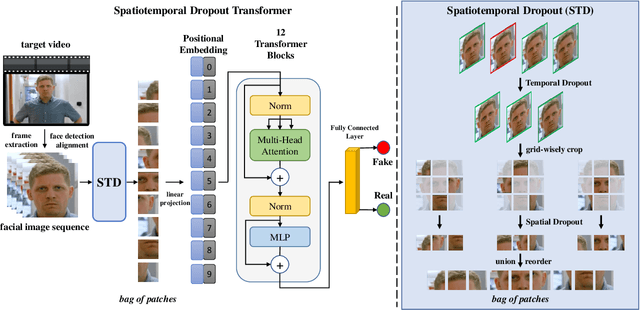
While the abuse of deepfake technology has caused serious concerns recently, how to detect deepfake videos is still a challenge due to the high photo-realistic synthesis of each frame. Existing image-level approaches often focus on single frame and ignore the spatiotemporal cues hidden in deepfake videos, resulting in poor generalization and robustness. The key of a video-level detector is to fully exploit the spatiotemporal inconsistency distributed in local facial regions across different frames in deepfake videos. Inspired by that, this paper proposes a simple yet effective patch-level approach to facilitate deepfake video detection via spatiotemporal dropout transformer. The approach reorganizes each input video into bag of patches that is then fed into a vision transformer to achieve robust representation. Specifically, a spatiotemporal dropout operation is proposed to fully explore patch-level spatiotemporal cues and serve as effective data augmentation to further enhance model's robustness and generalization ability. The operation is flexible and can be easily plugged into existing vision transformers. Extensive experiments demonstrate the effectiveness of our approach against 25 state-of-the-arts with impressive robustness, generalizability, and representation ability.
Interpretable Face Manipulation Detection via Feature Whitening
Jun 21, 2021
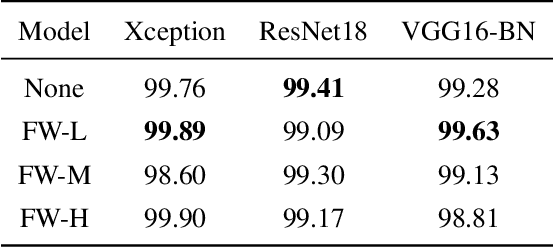
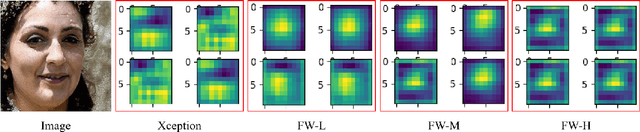
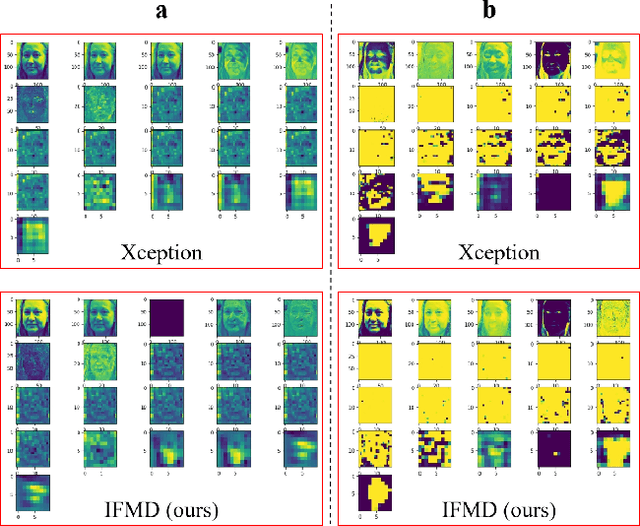
Why should we trust the detections of deep neural networks for manipulated faces? Understanding the reasons is important for users in improving the fairness, reliability, privacy and trust of the detection models. In this work, we propose an interpretable face manipulation detection approach to achieve the trustworthy and accurate inference. The approach could make the face manipulation detection process transparent by embedding the feature whitening module. This module aims to whiten the internal working mechanism of deep networks through feature decorrelation and feature constraint. The experimental results demonstrate that our proposed approach can strike a balance between the detection accuracy and the model interpretability.