 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Guided Data-Efficient Training for Multimodal Reasoning Reward Models
Feb 02, 2026Multimodal reward models are crucial for aligning multimodal large language models with human preferences. Recent works have incorporated reasoning capabilities into these models, achieving promising results. However, training these models suffers from two critical challenges: (1) the inherent noise in preference datasets, which degrades model performance, and (2) the inefficiency of conventional training methods, which ignore the differences in sample difficulty. In this paper, we identify a strong correlation between response entropy and accuracy, indicating that entropy can serve as a reliable and unsupervised proxy for annotation noise and sample difficulty. Based on this insight, we propose a novel Entropy-Guided Training (EGT) approach for multimodal reasoning reward models, which combines two strategies: (1) entropy-guided data curation to mitigate the impact of unreliable samples, and (2) an entropy-guided training strategy that progressively introduces more complex examples. Extensive experiments across three benchmarks show that the EGT-trained model consistently outperforms state-of-the-art multimodal reward models.
Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation
Dec 30, 2025Multimodal Large Language Models (MLLMs) have made remarkable progress in video understanding. However, they suffer from a critical vulnerability: an over-reliance on language priors, which can lead to visual ungrounded hallucinations, especially when processing counterfactual videos that defy common sense. This limitation, stemming from the intrinsic data imbalance between text and video, is challenging to address due to the substantial cost of collecting and annotating counterfactual data. To address this, we introduce DualityForge, a novel counterfactual data synthesis framework that employs controllable, diffusion-based video editing to transform real-world videos into counterfactual scenarios. By embedding structured contextual information into the video editing and QA generation processes, the framework automatically produces high-quality QA pairs together with original-edited video pairs for contrastive training. Based on this, we build DualityVidQA, a large-scale video dataset designed to reduce MLLM hallucinations. In addition, to fully exploit the contrastive nature of our paired data, we propose Duality-Normalized Advantage Training (DNA-Train), a two-stage SFT-RL training regime where the RL phase applies pair-wise $\ell_1$ advantage normalization, thereby enabling a more stable and efficient policy optimization. Experiments on DualityVidQA-Test demonstrate that our method substantially reduces model hallucinations on counterfactual videos, yielding a relative improvement of 24.0% over the Qwen2.5-VL-7B baseline. Moreover, our approach achieves significant gains across both hallucination and general-purpose benchmarks, indicating strong generalization capability. We will open-source our dataset and code.
From Context to EDUs: Faithful and Structured Context Compression via Elementary Discourse Unit Decomposition
Dec 18, 2025Managing extensive context remains a critical bottleneck for Large Language Models (LLMs), particularly in applications like long-document question answering and autonomous agents where lengthy inputs incur high computational costs and introduce noise. Existing compression techniques often disrupt local coherence through discrete token removal or rely on implicit latent encoding that suffers from positional bias and incompatibility with closed-source APIs. To address these limitations, we introduce the EDU-based Context Compressor, a novel explicit compression framework designed to preserve both global structure and fine-grained details. Our approach reformulates context compression as a structure-then-select process. First, our LingoEDU transforms linear text into a structural relation tree of Elementary Discourse Units (EDUs) which are anchored strictly to source indices to eliminate hallucination. Second, a lightweight ranking module selects query-relevant sub-trees for linearization. To rigorously evaluate structural understanding, we release StructBench, a manually annotated dataset of 248 diverse documents. Empirical results demonstrate that our method achieves state-of-the-art structural prediction accuracy and significantly outperforms frontier LLMs while reducing costs. Furthermore, our structure-aware compression substantially enhances performance across downstream tasks ranging from long-context tasks to complex Deep Search scenarios.
AgentProg: Empowering Long-Horizon GUI Agents with Program-Guided Context Management
Dec 11, 2025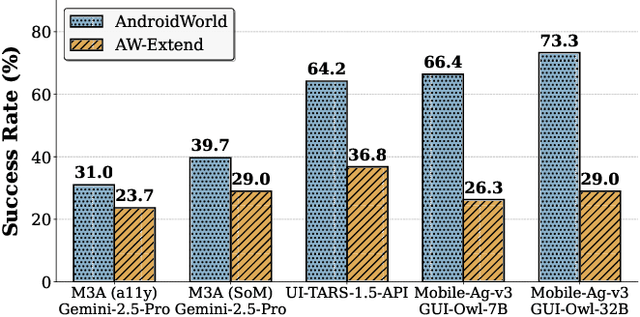

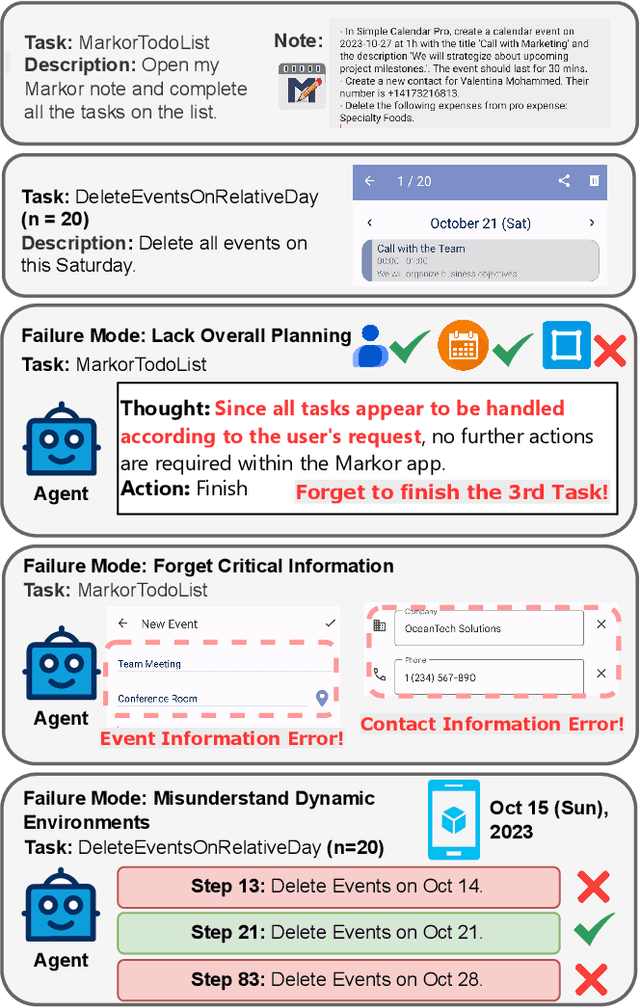

The rapid development of mobile GUI agents has stimulated growing research interest in long-horizon task automation. However, building agents for these tasks faces a critical bottleneck: the reliance on ever-expanding interaction history incurs substantial context overhead. Existing context management and compression techniques often fail to preserve vital semantic information, leading to degraded task performance. We propose AgentProg, a program-guided approach for agent context management that reframes the interaction history as a program with variables and control flow. By organizing information according to the structure of program, this structure provides a principled mechanism to determine which information should be retained and which can be discarded. We further integrate a global belief state mechanism inspired by Belief MDP framework to handle partial observability and adapt to unexpected environmental changes. Experiments on AndroidWorld and our extended long-horizon task suite demonstrate that AgentProg has achieved the state-of-the-art success rates on these benchmarks. More importantly, it maintains robust performance on long-horizon tasks while baseline methods experience catastrophic degradation. Our system is open-sourced at https://github.com/MobileLLM/AgentProg.
How Far are Modern Trackers from UAV-Anti-UAV? A Million-Scale Benchmark and New Baseline
Dec 08, 2025Unmanned Aerial Vehicles (UAVs) offer wide-ranging applications but also pose significant safety and privacy violation risks in areas like airport and infrastructure inspection, spurring the rapid development of Anti-UAV technologies in recent years. However, current Anti-UAV research primarily focuses on RGB, infrared (IR), or RGB-IR videos captured by fixed ground cameras, with little attention to tracking target UAVs from another moving UAV platform. To fill this gap, we propose a new multi-modal visual tracking task termed UAV-Anti-UAV, which involves a pursuer UAV tracking a target adversarial UAV in the video stream. Compared to existing Anti-UAV tasks, UAV-Anti-UAV is more challenging due to severe dual-dynamic disturbances caused by the rapid motion of both the capturing platform and the target. To advance research in this domain, we construct a million-scale dataset consisting of 1,810 videos, each manually annotated with bounding boxes, a language prompt, and 15 tracking attributes. Furthermore, we propose MambaSTS, a Mamba-based baseline method for UAV-Anti-UAV tracking, which enables integrated spatial-temporal-semantic learning. Specifically, we employ Mamba and Transformer models to learn global semantic and spatial features, respectively, and leverage the state space model's strength in long-sequence modeling to establish video-level long-term context via a temporal token propagation mechanism. We conduct experiments on the UAV-Anti-UAV dataset to validate the effectiveness of our method. A thorough experimental evaluation of 50 modern deep tracking algorithms demonstrates that there is still significant room for improvement in the UAV-Anti-UAV domain. The dataset and codes will be available at {\color{magenta}https://github.com/983632847/Awesome-Multimodal-Object-Tracking}.
BudgetThinker: Empowering Budget-aware LLM Reasoning with Control Tokens
Aug 24, 2025Recent advancements in Large Language Models (LLMs) have leveraged increased test-time computation to enhance reasoning capabilities, a strategy that, while effective, incurs significant latency and resource costs, limiting their applicability in real-world time-constrained or cost-sensitive scenarios. This paper introduces BudgetThinker, a novel framework designed to empower LLMs with budget-aware reasoning, enabling precise control over the length of their thought processes. We propose a methodology that periodically inserts special control tokens during inference to continuously inform the model of its remaining token budget. This approach is coupled with a comprehensive two-stage training pipeline, beginning with Supervised Fine-Tuning (SFT) to familiarize the model with budget constraints, followed by a curriculum-based Reinforcement Learning (RL) phase that utilizes a length-aware reward function to optimize for both accuracy and budget adherence. We demonstrate that BudgetThinker significantly surpasses strong baselines in maintaining performance across a variety of reasoning budgets on challenging mathematical benchmarks. Our method provides a scalable and effective solution for developing efficient and controllable LLM reasoning, making advanced models more practical for deployment in resource-constrained and real-time environments.
DyCrowd: Towards Dynamic Crowd Reconstruction from a Large-scene Video
Aug 18, 20253D reconstruction of dynamic crowds in large scenes has become increasingly important for applications such as city surveillance and crowd analysis. However, current works attempt to reconstruct 3D crowds from a static image, causing a lack of temporal consistency and inability to alleviate the typical impact caused by occlusions. In this paper, we propose DyCrowd, the first framework for spatio-temporally consistent 3D reconstruction of hundreds of individuals' poses, positions and shapes from a large-scene video. We design a coarse-to-fine group-guided motion optimization strategy for occlusion-robust crowd reconstruction in large scenes. To address temporal instability and severe occlusions, we further incorporate a VAE (Variational Autoencoder)-based human motion prior along with a segment-level group-guided optimization. The core of our strategy leverages collective crowd behavior to address long-term dynamic occlusions. By jointly optimizing the motion sequences of individuals with similar motion segments and combining this with the proposed Asynchronous Motion Consistency (AMC) loss, we enable high-quality unoccluded motion segments to guide the motion recovery of occluded ones, ensuring robust and plausible motion recovery even in the presence of temporal desynchronization and rhythmic inconsistencies. Additionally, in order to fill the gap of no existing well-annotated large-scene video dataset, we contribute a virtual benchmark dataset, VirtualCrowd, for evaluating dynamic crowd reconstruction from large-scene videos. Experimental results demonstrate that the proposed method achieves state-of-the-art performance in the large-scene dynamic crowd reconstruction task. The code and dataset will be available for research purposes.
LLM-Explorer: Towards Efficient and Affordable LLM-based Exploration for Mobile Apps
May 15, 2025Large language models (LLMs) have opened new opportunities for automated mobile app exploration, an important and challenging problem that used to suffer from the difficulty of generating meaningful UI interactions. However, existing LLM-based exploration approaches rely heavily on LLMs to generate actions in almost every step, leading to a huge cost of token fees and computational resources. We argue that such extensive usage of LLMs is neither necessary nor effective, since many actions during exploration do not require, or may even be biased by the abilities of LLMs. Further, based on the insight that a precise and compact knowledge plays the central role for effective exploration, we introduce LLM-Explorer, a new exploration agent designed for efficiency and affordability. LLM-Explorer uses LLMs primarily for maintaining the knowledge instead of generating actions, and knowledge is used to guide action generation in a LLM-less manner. Based on a comparison with 5 strong baselines on 20 typical apps, LLM-Explorer was able to achieve the fastest and highest coverage among all automated app explorers, with over 148x lower cost than the state-of-the-art LLM-based approach.
Time's Up! An Empirical Study of LLM Reasoning Ability Under Output Length Constraint
Apr 22, 2025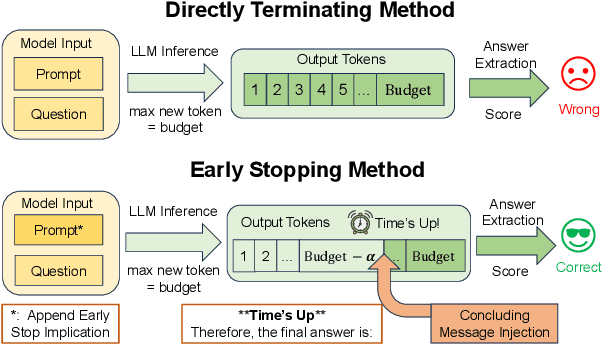
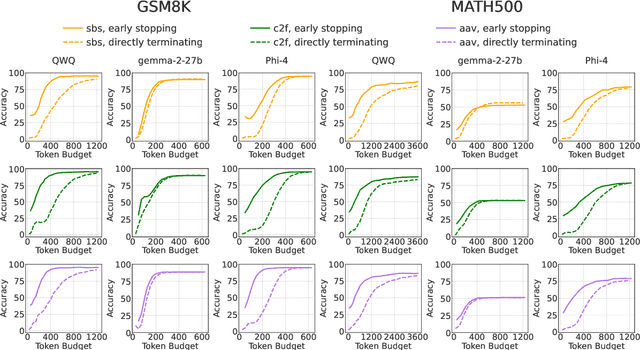
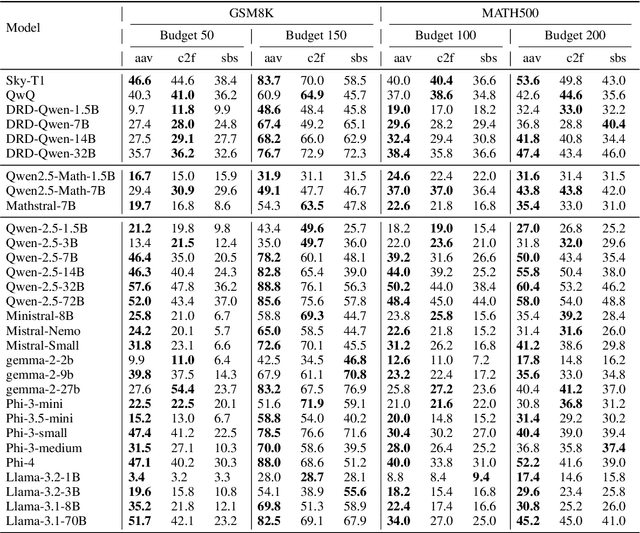
Recent work has demonstrated the remarkable potential of Large Language Models (LLMs) in test-time scaling. By making the models think before answering, they are able to achieve much higher accuracy with extra inference computation. However, in many real-world scenarios, models are used under time constraints, where an answer should be given to the user within a certain output length. It is unclear whether and how the reasoning abilities of LLMs remain effective under such constraints. We take a first look at this problem by conducting an in-depth empirical study. Specifically, we test more than 25 LLMs on common reasoning datasets under a wide range of output length budgets, and we analyze the correlation between the inference accuracy and various properties including model type, model size, prompt style, etc. We also consider the mappings between the token budgets and the actual on-device latency budgets. The results have demonstrated several interesting findings regarding the budget-aware LLM reasoning that differ from the unconstrained situation, e.g. the optimal choices of model sizes and prompts change under different budgets. These findings offer practical guidance for users to deploy LLMs under real-world latency constraints.
COST: Contrastive One-Stage Transformer for Vision-Language Small Object Tracking
Apr 02, 2025Transformer has recently demonstrated great potential in improving vision-language (VL) tracking algorithms. However, most of the existing VL trackers rely on carefully designed mechanisms to perform the multi-stage multi-modal fusion. Additionally, direct multi-modal fusion without alignment ignores distribution discrepancy between modalities in feature space, potentially leading to suboptimal representations. In this work, we propose COST, a contrastive one-stage transformer fusion framework for VL tracking, aiming to learn semantically consistent and unified VL representations. Specifically, we introduce a contrastive alignment strategy that maximizes mutual information (MI) between a video and its corresponding language description. This enables effective cross-modal alignment, yielding semantically consistent features in the representation space. By leveraging a visual-linguistic transformer, we establish an efficient multi-modal fusion and reasoning mechanism, empirically demonstrating that a simple stack of transformer encoders effectively enables unified VL representations. Moreover, we contribute a newly collected VL tracking benchmark dataset for small object tracking, named VL-SOT500, with bounding boxes and language descriptions. Our dataset comprises two challenging subsets, VL-SOT230 and VL-SOT270, dedicated to evaluating generic and high-speed small object tracking, respectively. Small object tracking is notoriously challenging due to weak appearance and limited features, and this dataset is, to the best of our knowledge, the first to explore the usage of language cues to enhance visual representation for small object tracking. Extensive experiments demonstrate that COST achieves state-of-the-art performance on five existing VL tracking datasets, as well as on our proposed VL-SOT500 dataset. Source codes and dataset will be made publicly available.