 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARES-DEIM: Sparse Mixture-of-Experts Meets DETR for Robust SAR Ship Detection
Apr 05, 2026Ship detection in Synthetic Aperture Radar (SAR) imagery is fundamentally challenged by inherent coherent speckle noise, complex coastal clutter, and the prevalence of small-scale targets. Conventional detectors, primarily designed for optical imagery, often exhibit limited robustness against SAR-specific degradation and suffer from the loss of fine-grained ship signatures during spatial downsampling. To address these limitations, we propose SARES-DEIM, a domain-aware detection framework grounded in the DEtection TRansformer (DETR) paradigm. Central to our approach is SARESMoE (SAR-aware Expert Selection Mixture-of-Experts), a module leveraging a sparse gating mechanism to selectively route features toward specialized frequency and wavelet experts. This sparsely-activated architecture effectively filters speckle noise and semantic clutter while maintaining high computational efficiency. Furthermore, we introduce the Space-to-Depth Enhancement Pyramid (SDEP) neck to preserve high-resolution spatial cues from shallow stages, significantly improving the localization of small targets. Extensive experiments on two benchmark datasets demonstrate the superiority of SARES-DEIM. Notably, on the challenging HRSID dataset, our model achieves a mAP50:95 of 76.4% and a mAP50 of 93.8%, outperforming state-of-the-art YOLO-series and specialized SAR detectors.
From Words to Worlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation
Mar 18, 2026Culture-expressions, such as idioms, slang, and culture-specific items (CSIs), are pervasive in natural language and encode meanings that go beyond literal linguistic form. Accurately translating such expressions remains challenging for machine translation systems. Despite this, existing benchmarks remain fragmented and do not provide a systematic framework for evaluating translation performance on culture-loaded expressions. To address this gap, we introduce CulT-Eval, a benchmark designed to evaluate how models handle different types of culturally grounded expressions. CulT-Eval comprises over 7,959 carefully curated instances spanning multiple types of culturally grounded expressions, with a comprehensive error taxonomy covering culturally grounded expressions. Through extensive evaluation of large language models and detailed analysis, we identify recurring and systematic failure modes that are not adequately captured by existing automatic metrics. Accordingly, we propose a complementary evaluation metric that targets culturally induced meaning deviations overlooked by standard MT metrics. The results indicate that current models struggle to preserve culturally grounded meaning and to capture the cultural and contextual nuances essential for accurate translation. Our benchmark and code are available at https://anonymous.4open.science/r/CulT-Eval-E75D/.
RecBundle: A Next-Generation Geometric Paradigm for Explainable Recommender Systems
Mar 17, 2026Recommender systems are inherently dynamic feedback loops where prolonged local interactions accumulate into macroscopic structural degradation such as information cocoons. Existing representation learning paradigms are universally constrained by the assumption of a single flat space, forcing topologically grounded user associations and semantically driven historical interactions to be fitted within the same vector space. This excessive coupling of heterogeneous information renders it impossible for researchers to mechanistically distinguish and identify the sources of systemic bias. To overcome this theoretical bottleneck, we introduce Fiber Bundle from modern differential geometry and propose a novel geometric analysis paradigm for recommender systems. This theory naturally decouples the system space into two hierarchical layers: the base manifold formed by user interaction networks, and the fibers attached to individual user nodes that carry their dynamic preferences. Building upon this, we construct RecBundle, a framework oriented toward next-generation recommender systems that formalizes user collaboration as geometric connection and parallel transport on the base manifold, while mapping content evolution to holonomy transformations on fibers. From this foundation, we identify future application directions encompassing quantitative mechanisms for information cocoons and evolutionary bias, geometric meta-theory for adaptive recommendation, and novel inference architectures integrating large language models (LLMs). Empirical analysis on real-world MovieLens and Amazon Beauty datasets validates the effectiveness of this geometric framework.
A Cognitive Distribution and Behavior-Consistent Framework for Black-Box Attacks on Recommender Systems
Feb 12, 2026With the growing deployment of sequential recommender systems in e-commerce and other fields, their black-box interfaces raise security concerns: models are vulnerable to extraction and subsequent adversarial manipulation. Existing black-box extraction attacks primarily rely on hard labels or pairwise learning, often ignoring the importance of ranking positions, which results in incomplete knowledge transfer. Moreover, adversarial sequences generated via pure gradient methods lack semantic consistency with real user behavior, making them easily detectable. To overcome these limitations, this paper proposes a dual-enhanced attack framework. First, drawing on primacy effects and position bias, we introduce a cognitive distribution-driven extraction mechanism that maps discrete rankings into continuous value distributions with position-aware decay, thereby advancing from order alignment to cognitive distribution alignment. Second, we design a behavior-aware noisy item generation strategy that jointly optimizes collaborative signals and gradient signals. This ensures both semantic coherence and statistical stealth while effectively promoting target item rankings. Extensive experiments on multiple datasets demonstrate that our approach significantly outperforms existing methods in both attack success rate and evasion rate, validating the value of integrating cognitive modeling and behavioral consistency for secure recommender systems.
How Far are Modern Trackers from UAV-Anti-UAV? A Million-Scale Benchmark and New Baseline
Dec 08, 2025Unmanned Aerial Vehicles (UAVs) offer wide-ranging applications but also pose significant safety and privacy violation risks in areas like airport and infrastructure inspection, spurring the rapid development of Anti-UAV technologies in recent years. However, current Anti-UAV research primarily focuses on RGB, infrared (IR), or RGB-IR videos captured by fixed ground cameras, with little attention to tracking target UAVs from another moving UAV platform. To fill this gap, we propose a new multi-modal visual tracking task termed UAV-Anti-UAV, which involves a pursuer UAV tracking a target adversarial UAV in the video stream. Compared to existing Anti-UAV tasks, UAV-Anti-UAV is more challenging due to severe dual-dynamic disturbances caused by the rapid motion of both the capturing platform and the target. To advance research in this domain, we construct a million-scale dataset consisting of 1,810 videos, each manually annotated with bounding boxes, a language prompt, and 15 tracking attributes. Furthermore, we propose MambaSTS, a Mamba-based baseline method for UAV-Anti-UAV tracking, which enables integrated spatial-temporal-semantic learning. Specifically, we employ Mamba and Transformer models to learn global semantic and spatial features, respectively, and leverage the state space model's strength in long-sequence modeling to establish video-level long-term context via a temporal token propagation mechanism. We conduct experiments on the UAV-Anti-UAV dataset to validate the effectiveness of our method. A thorough experimental evaluation of 50 modern deep tracking algorithms demonstrates that there is still significant room for improvement in the UAV-Anti-UAV domain. The dataset and codes will be available at {\color{magenta}https://github.com/983632847/Awesome-Multimodal-Object-Tracking}.
COST: Contrastive One-Stage Transformer for Vision-Language Small Object Tracking
Apr 02, 2025Transformer has recently demonstrated great potential in improving vision-language (VL) tracking algorithms. However, most of the existing VL trackers rely on carefully designed mechanisms to perform the multi-stage multi-modal fusion. Additionally, direct multi-modal fusion without alignment ignores distribution discrepancy between modalities in feature space, potentially leading to suboptimal representations. In this work, we propose COST, a contrastive one-stage transformer fusion framework for VL tracking, aiming to learn semantically consistent and unified VL representations. Specifically, we introduce a contrastive alignment strategy that maximizes mutual information (MI) between a video and its corresponding language description. This enables effective cross-modal alignment, yielding semantically consistent features in the representation space. By leveraging a visual-linguistic transformer, we establish an efficient multi-modal fusion and reasoning mechanism, empirically demonstrating that a simple stack of transformer encoders effectively enables unified VL representations. Moreover, we contribute a newly collected VL tracking benchmark dataset for small object tracking, named VL-SOT500, with bounding boxes and language descriptions. Our dataset comprises two challenging subsets, VL-SOT230 and VL-SOT270, dedicated to evaluating generic and high-speed small object tracking, respectively. Small object tracking is notoriously challenging due to weak appearance and limited features, and this dataset is, to the best of our knowledge, the first to explore the usage of language cues to enhance visual representation for small object tracking. Extensive experiments demonstrate that COST achieves state-of-the-art performance on five existing VL tracking datasets, as well as on our proposed VL-SOT500 dataset. Source codes and dataset will be made publicly available.
MambaTrack: Exploiting Dual-Enhancement for Night UAV Tracking
Nov 24, 2024



Night unmanned aerial vehicle (UAV) tracking is impeded by the challenges of poor illumination, with previous daylight-optimized methods demonstrating suboptimal performance in low-light conditions, limiting the utility of UAV applications. To this end, we propose an efficient mamba-based tracker, leveraging dual enhancement techniques to boost night UAV tracking. The mamba-based low-light enhancer, equipped with an illumination estimator and a damage restorer, achieves global image enhancement while preserving the details and structure of low-light images. Additionally, we advance a cross-modal mamba network to achieve efficient interactive learning between vision and language modalities. Extensive experiments showcase that our method achieves advanced performance and exhibits significantly improved computation and memory efficiency. For instance, our method is 2.8$\times$ faster than CiteTracker and reduces 50.2$\%$ GPU memory. Codes will be made publicly available.
Towards Underwater Camouflaged Object Tracking: An Experimental Evaluation of SAM and SAM 2
Sep 25, 2024

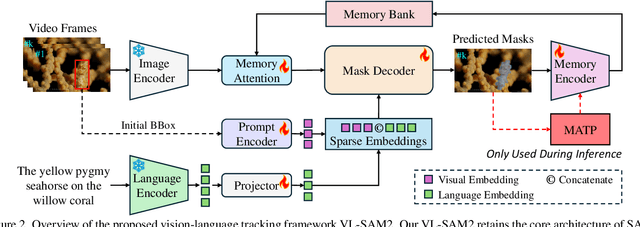
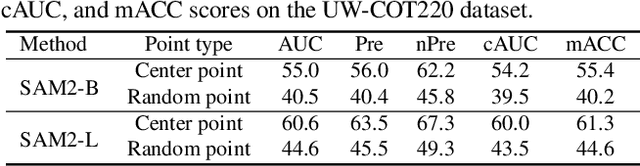
Over the past decade, significant progress has been made in visual object tracking, largely due to the availability of large-scale training datasets. However, existing tracking datasets are primarily focused on open-air scenarios, which greatly limits the development of object tracking in underwater environments. To address this issue, we take a step forward by proposing the first large-scale underwater camouflaged object tracking dataset, namely UW-COT. Based on the proposed dataset, this paper presents an experimental evaluation of several advanced visual object tracking methods and the latest advancements in image and video segmentation. Specifically, we compare the performance of the Segment Anything Model (SAM) and its updated version, SAM 2, in challenging underwater environments. Our findings highlight the improvements in SAM 2 over SAM, demonstrating its enhanced capability to handle the complexities of underwater camouflaged objects. Compared to current advanced visual object tracking methods, the latest video segmentation foundation model SAM 2 also exhibits significant advantages, providing valuable insights into the development of more effective tracking technologies for underwater scenarios. The dataset will be accessible at \color{magenta}{https://github.com/983632847/Awesome-Multimodal-Object-Tracking}.
WebUOT-1M: Advancing Deep Underwater Object Tracking with A Million-Scale Benchmark
May 30, 2024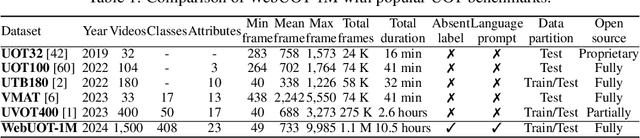

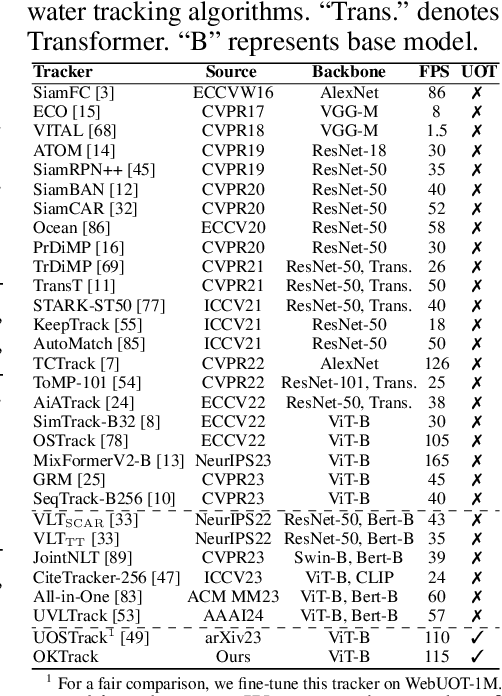

Underwater object tracking (UOT) is a foundational task for identifying and tracing submerged entities in underwater video sequences. However, current UOT datasets suffer from limitations in scale, diversity of target categories and scenarios covered, hindering the training and evaluation of modern tracking algorithms. To bridge this gap, we take the first step and introduce WebUOT-1M, \ie, the largest public UOT benchmark to date, sourced from complex and realistic underwater environments. It comprises 1.1 million frames across 1,500 video clips filtered from 408 target categories, largely surpassing previous UOT datasets, \eg, UVOT400. Through meticulous manual annotation and verification, we provide high-quality bounding boxes for underwater targets. Additionally, WebUOT-1M includes language prompts for video sequences, expanding its application areas, \eg, underwater vision-language tracking. Most existing trackers are tailored for open-air environments, leading to performance degradation when applied to UOT due to domain gaps. Retraining and fine-tuning these trackers are challenging due to sample imbalances and limited real-world underwater datasets. To tackle these challenges, we propose a novel omni-knowledge distillation framework based on WebUOT-1M, incorporating various strategies to guide the learning of the student Transformer. To the best of our knowledge, this framework is the first to effectively transfer open-air domain knowledge to the UOT model through knowledge distillation, as demonstrated by results on both existing UOT datasets and the newly proposed WebUOT-1M. Furthermore, we comprehensively evaluate WebUOT-1M using 30 deep trackers, showcasing its value as a benchmark for UOT research by presenting new challenges and opportunities for future studies. The complete dataset, codes and tracking results, will be made publicly available.
Awesome Multi-modal Object Tracking
May 23, 2024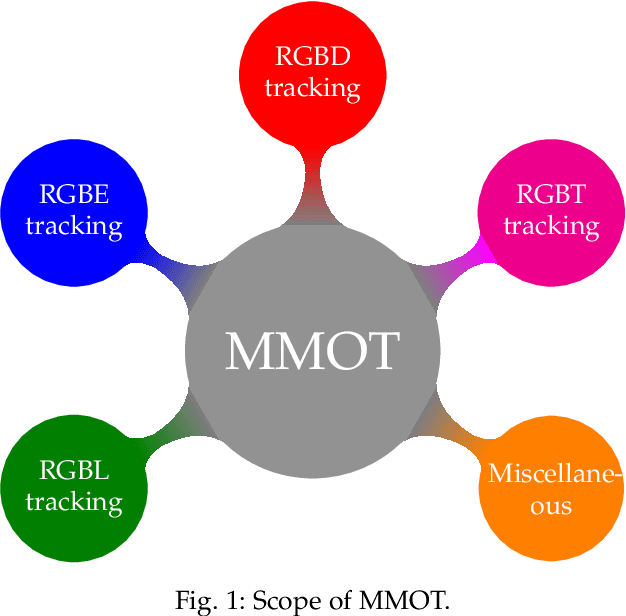
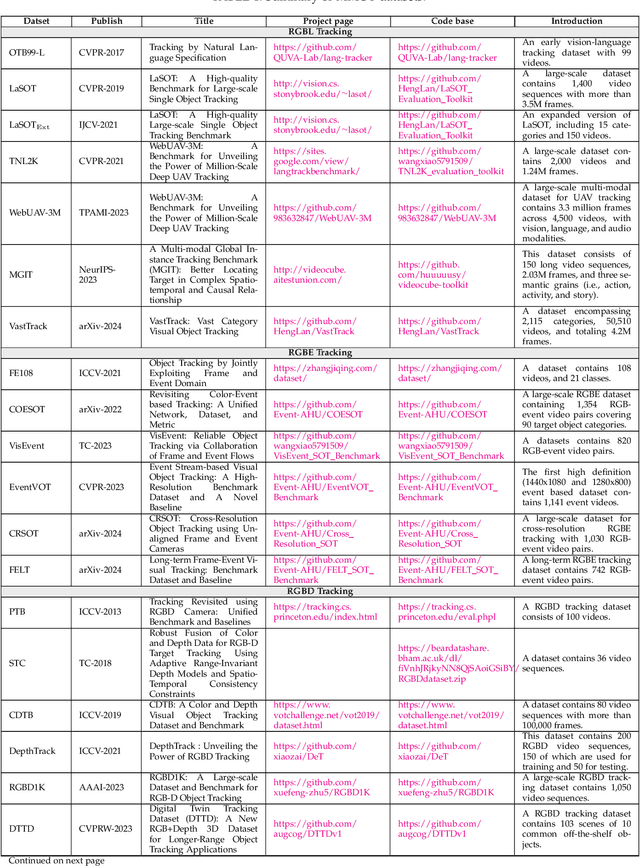

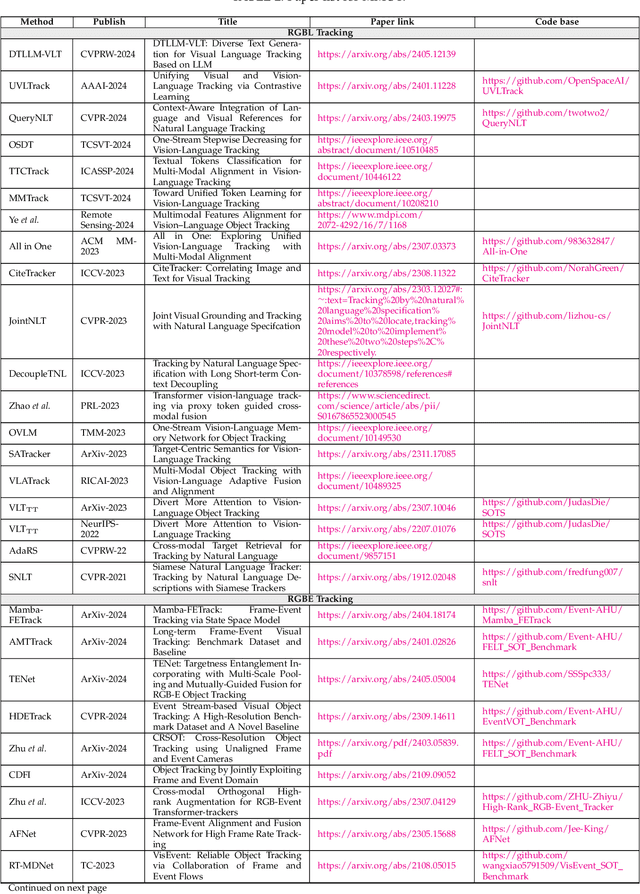
Multi-modal object tracking (MMOT) is an emerging field that combines data from various modalities, \eg vision (RGB), depth, thermal infrared, event, language and audio, to estimate the state of an arbitrary object in a video sequence. It is of great significance for many applications such as autonomous driving and intelligent surveillance. In recent years, MMOT has received more and more attention. However, existing MMOT algorithms mainly focus on two modalities (\eg RGB+depth, RGB+thermal infrared, and RGB+language). To leverage more modalities, some recent efforts have been made to learn a unified visual object tracking model for any modality. Additionally, some large-scale multi-modal tracking benchmarks have been established by simultaneously providing more than two modalities, such as vision-language-audio (\eg WebUAV-3M) and vision-depth-language (\eg UniMod1K). To track the latest progress in MMOT, we conduct a comprehensive investigation in this report. Specifically, we first divide existing MMOT tasks into five main categories, \ie RGBL tracking, RGBE tracking, RGBD tracking, RGBT tracking, and miscellaneous (RGB+X), where X can be any modality, such as language, depth, and event. Then, we analyze and summarize each MMOT task, focusing on widely used datasets and mainstream tracking algorithms based on their technical paradigms (\eg self-supervised learning, prompt learning, knowledge distillation, generative models, and state space models). Finally, we maintain a continuously updated paper list for MMOT at https://github.com/983632847/Awesome-Multimodal-Object-Tracking.