 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitosis Detection in the Wild: Multi-Tumor and Context-Aware Generalization in the MIDOG 2025 Challenge
Jun 05, 2026Automated mitosis detection is a well-established task in computational pathology. While previous benchmarks focused on scanner-induced domain shift, clinical "real-world" application requires models to be robust across the vast variance to be expected in the histological landscape. The MItosis DOmain Generalization (MIDOG) 2025 challenge was designed to evaluate algorithmic performance across unprecedented biological and contextual diversity. We curated a test dataset of 365 cases, encompassing 12 distinct human, canine and feline tumor types, digitized across multiple scanning platforms. Moving beyond hand-selected hotspots, the challenge required detection also in random tissue areas (representative of the whole slide detection situation) and challenging areas (areas rich in hard negatives). In the second track, we introduced the classification of atypical mitotic figures (AMFs). There were 18 teams submitting to the detection track, with F1 scores ranging up to 0.740. In the AMF detection track, we had 21 submissions with balanced accuracy values up to 0.908. Our analysis reveals that while most models perform reliably in traditional hotspots, significant performance degradation occurs in challenging ROIs, where false positive rates tripled. Furthermore, performance varied significantly across the 12 tumor types, highlighting "blind spots" in current state-of-the-art architectures when encountering rare or highly pleomorphic malignancies. Moreover, we evaluated the effectiveness of ensembling and found a mean increases of 1.5 and 1.3 percentage points in F1 score and balanced accuracy, respectively. In contrast, TTA showed no relevant improvement. MIDOG 2025 demonstrates that "in the wild" mitosis detection remains a significant hurdle. The transition from hotspot-only evaluation to a multi-contextual framework provides a more realistic proxy for clinical reliability.
Semantic Class Distribution Learning for Debiasing Semi-Supervised Medical Image Segmentation
Mar 05, 2026Medical image segmentation is critical for computer-aided diagnosis. However, dense pixel-level annotation is time-consuming and expensive, and medical datasets often exhibit severe class imbalance. Such imbalance causes minority structures to be overwhelmed by dominant classes in feature representations, hindering the learning of discriminative features and making reliable segmentation particularly challenging. To address this, we propose the Semantic Class Distribution Learning (SCDL) framework, a plug-and-play module that mitigates supervision and representation biases by learning structured class-conditional feature distributions. SCDL integrates Class Distribution Bidirectional Alignment (CDBA) to align embeddings with learnable class proxies and leverages Semantic Anchor Constraints (SAC) to guide proxies using labeled data. Experiments on the Synapse and AMOS datasets demonstrate that SCDL significantly improves segmentation performance across both overall and class-level metrics, with particularly strong gains on minority classes, achieving state-of-the-art results. Our code is released at https://github.com/Zyh55555/SCDL.
CellMamba: Adaptive Mamba for Accurate and Efficient Cell Detection
Dec 25, 2025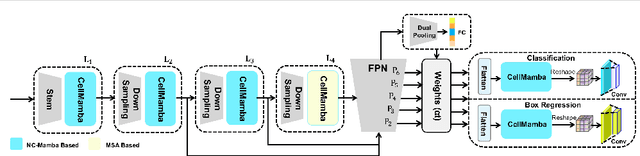
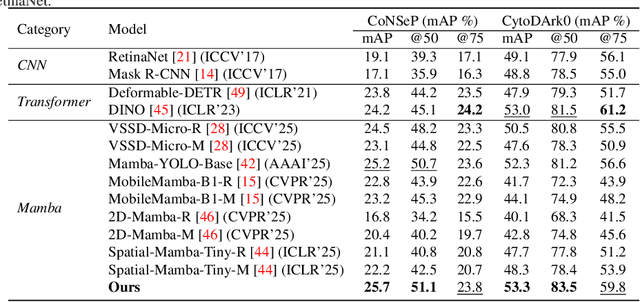
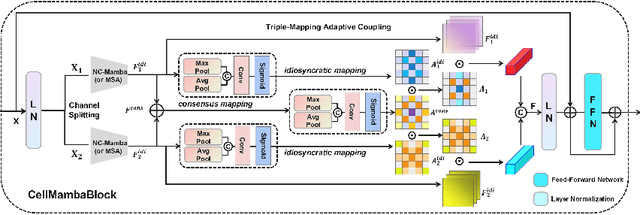
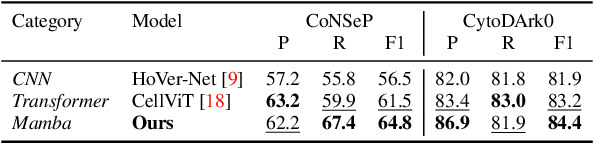
Cell detection in pathological images presents unique challenges due to densely packed objects, subtle inter-class differences, and severe background clutter. In this paper, we propose CellMamba, a lightweight and accurate one-stage detector tailored for fine-grained biomedical instance detection. Built upon a VSSD backbone, CellMamba integrates CellMamba Blocks, which couple either NC-Mamba or Multi-Head Self-Attention (MSA) with a novel Triple-Mapping Adaptive Coupling (TMAC) module. TMAC enhances spatial discriminability by splitting channels into two parallel branches, equipped with dual idiosyncratic and one consensus attention map, adaptively fused to preserve local sensitivity and global consistency. Furthermore, we design an Adaptive Mamba Head that fuses multi-scale features via learnable weights for robust detection under varying object sizes. Extensive experiments on two public datasets-CoNSeP and CytoDArk0-demonstrate that CellMamba outperforms both CNN-based, Transformer-based, and Mamba-based baselines in accuracy, while significantly reducing model size and inference latency. Our results validate CellMamba as an efficient and effective solution for high-resolution cell detection.
TADT-CSA: Temporal Advantage Decision Transformer with Contrastive State Abstraction for Generative Recommendation
Jul 27, 2025With the rapid advancement of Transformer-based Large Language Models (LLMs), generative recommendation has shown great potential in enhancing both the accuracy and semantic understanding of modern recommender systems. Compared to LLMs, the Decision Transformer (DT) is a lightweight generative model applied to sequential recommendation tasks. However, DT faces challenges in trajectory stitching, often producing suboptimal trajectories. Moreover, due to the high dimensionality of user states and the vast state space inherent in recommendation scenarios, DT can incur significant computational costs and struggle to learn effective state representations. To overcome these issues, we propose a novel Temporal Advantage Decision Transformer with Contrastive State Abstraction (TADT-CSA) model. Specifically, we combine the conventional Return-To-Go (RTG) signal with a novel temporal advantage (TA) signal that encourages the model to capture both long-term returns and their sequential trend. Furthermore, we integrate a contrastive state abstraction module into the DT framework to learn more effective and expressive state representations. Within this module, we introduce a TA-conditioned State Vector Quantization (TAC-SVQ) strategy, where the TA score guides the state codebooks to incorporate contextual token information. Additionally, a reward prediction network and a contrastive transition prediction (CTP) network are employed to ensure the state codebook preserves both the reward information of the current state and the transition information between adjacent states. Empirical results on both public datasets and an online recommendation system demonstrate the effectiveness of the TADT-CSA model and its superiority over baseline methods.
Dual Boost-Driven Graph-Level Clustering Network
Apr 08, 2025



Graph-level clustering remains a pivotal yet formidable challenge in graph learning. Recently, the integration of deep learning with representation learning has demonstrated notable advancements, yielding performance enhancements to a certain degree. However, existing methods suffer from at least one of the following issues: 1. the original graph structure has noise, and 2. during feature propagation and pooling processes, noise is gradually aggregated into the graph-level embeddings through information propagation. Consequently, these two limitations mask clustering-friendly information, leading to suboptimal graph-level clustering performance. To this end, we propose a novel Dual Boost-Driven Graph-Level Clustering Network (DBGCN) to alternately promote graph-level clustering and filtering out interference information in a unified framework. Specifically, in the pooling step, we evaluate the contribution of features at the global and optimize them using a learnable transformation matrix to obtain high-quality graph-level representation, such that the model's reasoning capability can be improved. Moreover, to enable reliable graph-level clustering, we first identify and suppress information detrimental to clustering by evaluating similarities between graph-level representations, providing more accurate guidance for multi-view fusion. Extensive experiments demonstrated that DBGCN outperforms the state-of-the-art graph-level clustering methods on six benchmark datasets.
Advancing Cross-Organ Domain Generalization with Test-Time Style Transfer and Diversity Enhancement
Mar 24, 2025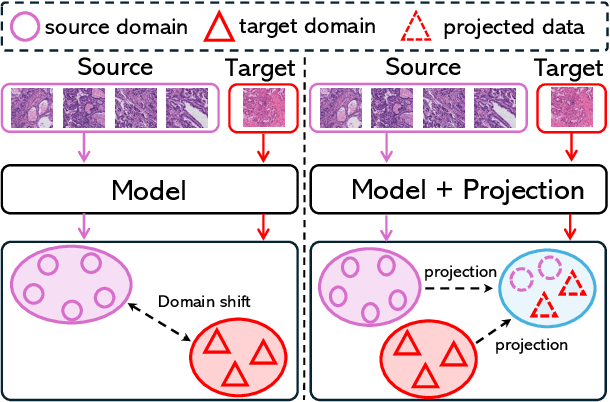



Deep learning has made significant progress in addressing challenges in various fields including computational pathology (CPath). However, due to the complexity of the domain shift problem, the performance of existing models will degrade, especially when it comes to multi-domain or cross-domain tasks. In this paper, we propose a Test-time style transfer (T3s) that uses a bidirectional mapping mechanism to project the features of the source and target domains into a unified feature space, enhancing the generalization ability of the model. To further increase the style expression space, we introduce a Cross-domain style diversification module (CSDM) to ensure the orthogonality between style bases. In addition, data augmentation and low-rank adaptation techniques are used to improve feature alignment and sensitivity, enabling the model to adapt to multi-domain inputs effectively. Our method has demonstrated effectiveness on three unseen datasets.
On the Federated Learning Framework for Cooperative Perception
Apr 26, 2024


Cooperative perception is essential to enhance the efficiency and safety of future transportation systems, requiring extensive data sharing among vehicles on the road, which raises significant privacy concerns. Federated learning offers a promising solution by enabling data privacy-preserving collaborative enhancements in perception, decision-making, and planning among connected and autonomous vehicles (CAVs). However, federated learning is impeded by significant challenges arising from data heterogeneity across diverse clients, potentially diminishing model accuracy and prolonging convergence periods. This study introduces a specialized federated learning framework for CP, termed the federated dynamic weighted aggregation (FedDWA) algorithm, facilitated by dynamic adjusting loss (DALoss) function. This framework employs dynamic client weighting to direct model convergence and integrates a novel loss function that utilizes Kullback-Leibler divergence (KLD) to counteract the detrimental effects of non-independently and identically distributed (Non-IID) and unbalanced data. Utilizing the BEV transformer as the primary model, our rigorous testing on the OpenV2V dataset, augmented with FedBEVT data, demonstrates significant improvements in the average intersection over union (IoU). These results highlight the substantial potential of our federated learning framework to address data heterogeneity challenges in CP, thereby enhancing the accuracy of environmental perception models and facilitating more robust and efficient collaborative learning solutions in the transportation sector.
A Dataset and Model for Realistic License Plate Deblurring
Apr 23, 2024
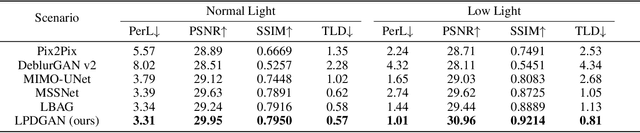
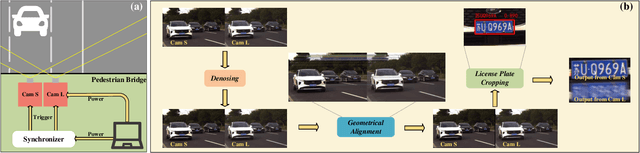
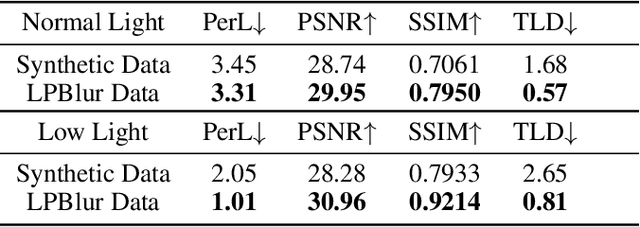
Vehicle license plate recognition is a crucial task in intelligent traffic management systems. However, the challenge of achieving accurate recognition persists due to motion blur from fast-moving vehicles. Despite the widespread use of image synthesis approaches in existing deblurring and recognition algorithms, their effectiveness in real-world scenarios remains unproven. To address this, we introduce the first large-scale license plate deblurring dataset named License Plate Blur (LPBlur), captured by a dual-camera system and processed through a post-processing pipeline to avoid misalignment issues. Then, we propose a License Plate Deblurring Generative Adversarial Network (LPDGAN) to tackle the license plate deblurring: 1) a Feature Fusion Module to integrate multi-scale latent codes; 2) a Text Reconstruction Module to restore structure through textual modality; 3) a Partition Discriminator Module to enhance the model's perception of details in each letter. Extensive experiments validate the reliability of the LPBlur dataset for both model training and testing, showcasing that our proposed model outperforms other state-of-the-art motion deblurring methods in realistic license plate deblurring scenarios. The dataset and code are available at https://github.com/haoyGONG/LPDGAN.
DuAT: Dual-Aggregation Transformer Network for Medical Image Segmentation
Dec 21, 2022



Transformer-based models have been widely demonstrated to be successful in computer vision tasks by modelling long-range dependencies and capturing global representations. However, they are often dominated by features of large patterns leading to the loss of local details (e.g., boundaries and small objects), which are critical in medical image segmentation. To alleviate this problem, we propose a Dual-Aggregation Transformer Network called DuAT, which is characterized by two innovative designs, namely, the Global-to-Local Spatial Aggregation (GLSA) and Selective Boundary Aggregation (SBA) modules. The GLSA has the ability to aggregate and represent both global and local spatial features, which are beneficial for locating large and small objects, respectively. The SBA module is used to aggregate the boundary characteristic from low-level features and semantic information from high-level features for better preserving boundary details and locating the re-calibration objects. Extensive experiments in six benchmark datasets demonstrate that our proposed model outperforms state-of-the-art methods in the segmentation of skin lesion images, and polyps in colonoscopy images. In addition, our approach is more robust than existing methods in various challenging situations such as small object segmentation and ambiguous object boundaries.
Geometry-aware Single-image Full-body Human Relighting
Jul 12, 2022
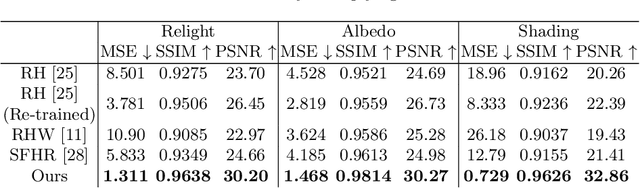
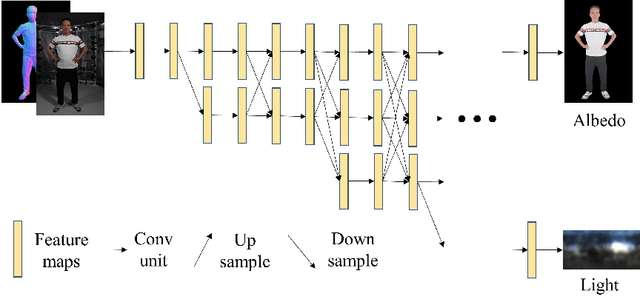
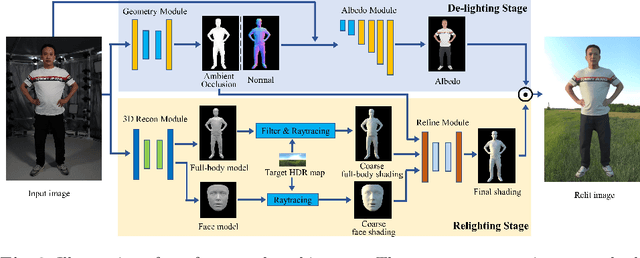
Single-image human relighting aims to relight a target human under new lighting conditions by decomposing the input image into albedo, shape and lighting. Although plausible relighting results can be achieved, previous methods suffer from both the entanglement between albedo and lighting and the lack of hard shadows, which significantly decrease the realism. To tackle these two problems, we propose a geometry-aware single-image human relighting framework that leverages single-image geometry reconstruction for joint deployment of traditional graphics rendering and neural rendering techniques. For the de-lighting, we explore the shortcomings of UNet architecture and propose a modified HRNet, achieving better disentanglement between albedo and lighting. For the relighting, we introduce a ray tracing-based per-pixel lighting representation that explicitly models high-frequency shadows and propose a learning-based shading refinement module to restore realistic shadows (including hard cast shadows) from the ray-traced shading maps. Our framework is able to generate photo-realistic high-frequency shadows such as cast shadows under challenging lighting conditions. Extensive experiments demonstrate that our proposed method outperforms previous methods on both synthetic and real images.