 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Feature Rectification with Region Adjacency Graphs for Training-Free Open-Vocabulary Semantic Segmentation
Dec 08, 2025


Benefiting from the inductive biases learned from large-scale datasets, open-vocabulary semantic segmentation (OVSS) leverages the power of vision-language models, such as CLIP, to achieve remarkable progress without requiring task-specific training. However, due to CLIP's pre-training nature on image-text pairs, it tends to focus on global semantic alignment, resulting in suboptimal performance when associating fine-grained visual regions with text. This leads to noisy and inconsistent predictions, particularly in local areas. We attribute this to a dispersed bias stemming from its contrastive training paradigm, which is difficult to alleviate using CLIP features alone. To address this, we propose a structure-aware feature rectification approach that incorporates instance-specific priors derived directly from the image. Specifically, we construct a region adjacency graph (RAG) based on low-level features (e.g., colour and texture) to capture local structural relationships and use it to refine CLIP features by enhancing local discrimination. Extensive experiments show that our method effectively suppresses segmentation noise, improves region-level consistency, and achieves strong performance on multiple open-vocabulary segmentation benchmarks.
What Can We Learn from Harry Potter? An Exploratory Study of Visual Representation Learning from Atypical Videos
Aug 29, 2025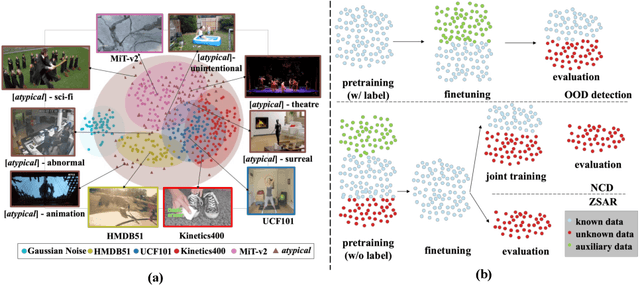
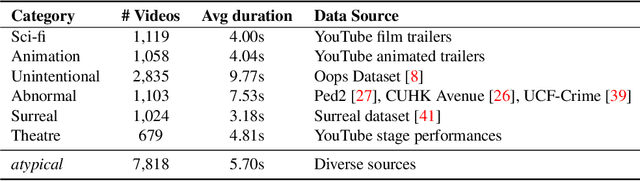

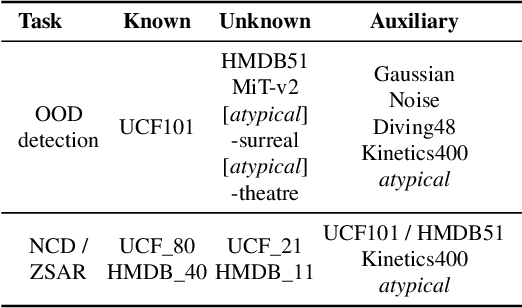
Humans usually show exceptional generalisation and discovery ability in the open world, when being shown uncommon new concepts. Whereas most existing studies in the literature focus on common typical data from closed sets, open-world novel discovery is under-explored in videos. In this paper, we are interested in asking: \textit{What if atypical unusual videos are exposed in the learning process?} To this end, we collect a new video dataset consisting of various types of unusual atypical data (\eg sci-fi, animation, \etc). To study how such atypical data may benefit open-world learning, we feed them into the model training process for representation learning. Focusing on three key tasks in open-world learning: out-of-distribution (OOD) detection, novel category discovery (NCD), and zero-shot action recognition (ZSAR), we found that even straightforward learning approaches with atypical data consistently improve performance across various settings. Furthermore, we found that increasing the categorical diversity of the atypical samples further boosts OOD detection performance. Additionally, in the NCD task, using a smaller yet more semantically diverse set of atypical samples leads to better performance compared to using a larger but more typical dataset. In the ZSAR setting, the semantic diversity of atypical videos helps the model generalise better to unseen action classes. These observations in our extensive experimental evaluations reveal the benefits of atypical videos for visual representation learning in the open world, together with the newly proposed dataset, encouraging further studies in this direction.
Few Exemplar-Based General Medical Image Segmentation via Domain-Aware Selective Adaptation
Oct 11, 2024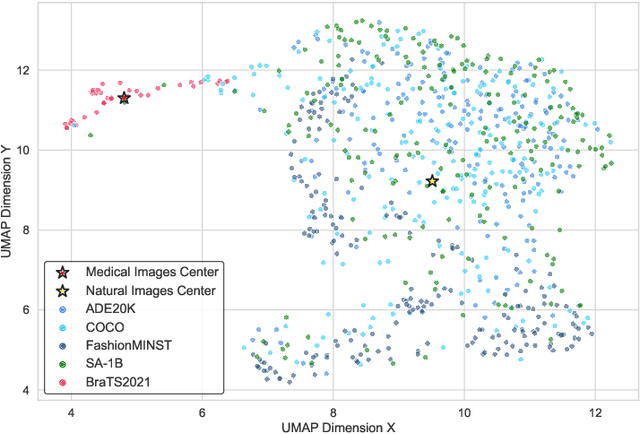
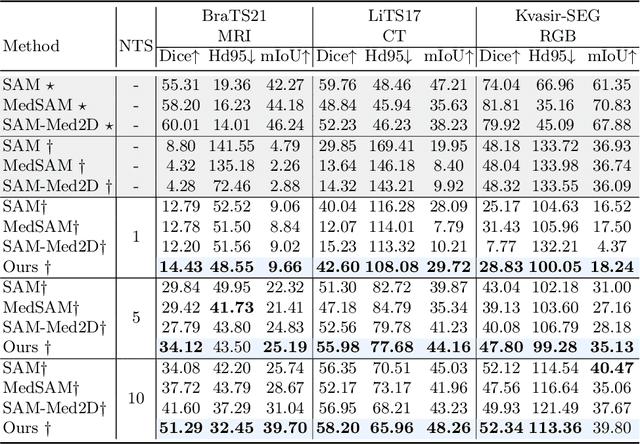
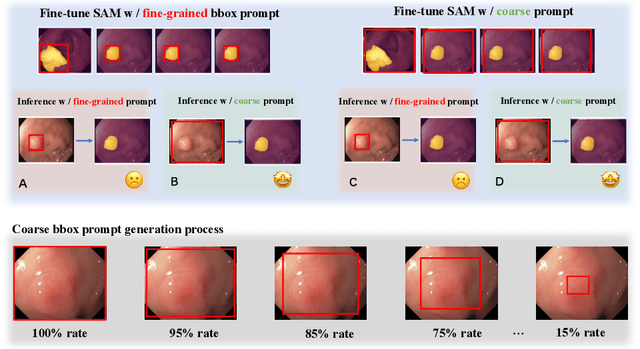
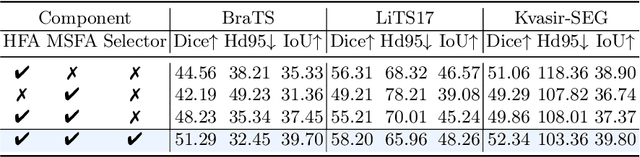
Medical image segmentation poses challenges due to domain gaps, data modality variations, and dependency on domain knowledge or experts, especially for low- and middle-income countries (LMICs). Whereas for humans, given a few exemplars (with corresponding labels), we are able to segment different medical images even without exten-sive domain-specific clinical training. In addition, current SAM-based medical segmentation models use fine-grained visual prompts, such as the bounding rectangle generated from manually annotated target segmentation mask, as the bounding box (bbox) prompt during the testing phase. However, in actual clinical scenarios, no such precise prior knowledge is available. Our experimental results also reveal that previous models nearly fail to predict when given coarser bbox prompts. Considering these issues, in this paper, we introduce a domain-aware selective adaptation approach to adapt the general knowledge learned from a large model trained with natural images to the corresponding medical domains/modalities, with access to only a few (e.g. less than 5) exemplars. Our method mitigates the aforementioned limitations, providing an efficient and LMICs-friendly solution. Extensive experimental analysis showcases the effectiveness of our approach, offering potential advancements in healthcare diagnostics and clinical applications in LMICs.
GAME: Generalized deep learning model towards multimodal data integration for early screening of adolescent mental disorders
Sep 18, 2023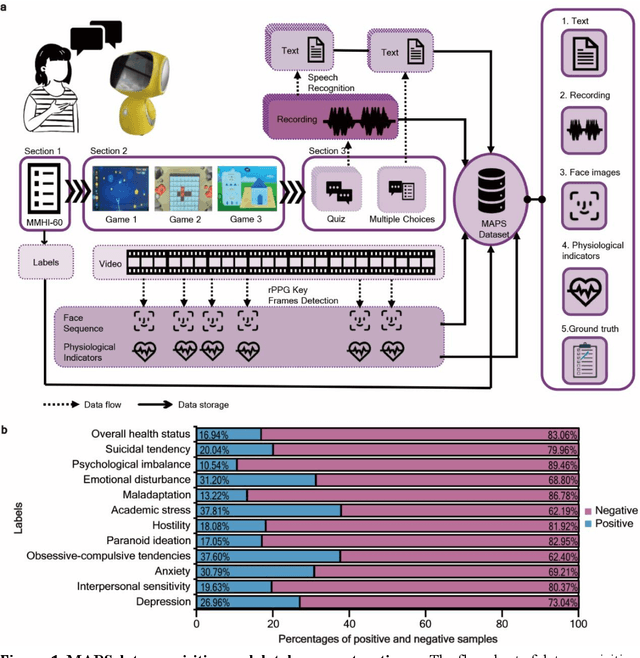


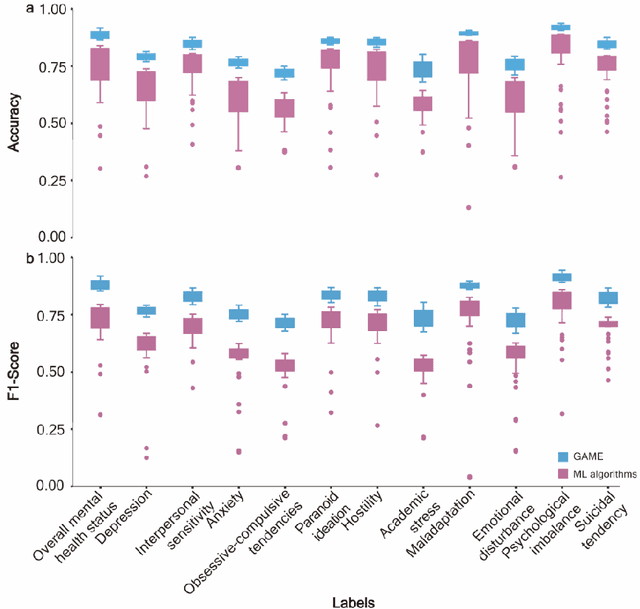
The timely identification of mental disorders in adolescents is a global public health challenge.Single factor is difficult to detect the abnormality due to its complex and subtle nature. Additionally, the generalized multimodal Computer-Aided Screening (CAS) systems with interactive robots for adolescent mental disorders are not available. Here, we design an android application with mini-games and chat recording deployed in a portable robot to screen 3,783 middle school students and construct the multimodal screening dataset, including facial images, physiological signs, voice recordings, and textual transcripts.We develop a model called GAME (Generalized Model with Attention and Multimodal EmbraceNet) with novel attention mechanism that integrates cross-modal features into the model. GAME evaluates adolescent mental conditions with high accuracy (73.34%-92.77%) and F1-Score (71.32%-91.06%).We find each modality contributes dynamically to the mental disorders screening and comorbidities among various mental disorders, indicating the feasibility of explainable model. This study provides a system capable of acquiring multimodal information and constructs a generalized multimodal integration algorithm with novel attention mechanisms for the early screening of adolescent mental disorders.
Prompt-enhanced Hierarchical Transformer Elevating Cardiopulmonary Resuscitation Instruction via Temporal Action Segmentation
Aug 31, 2023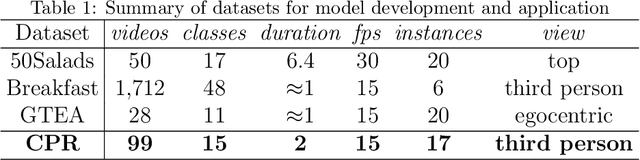
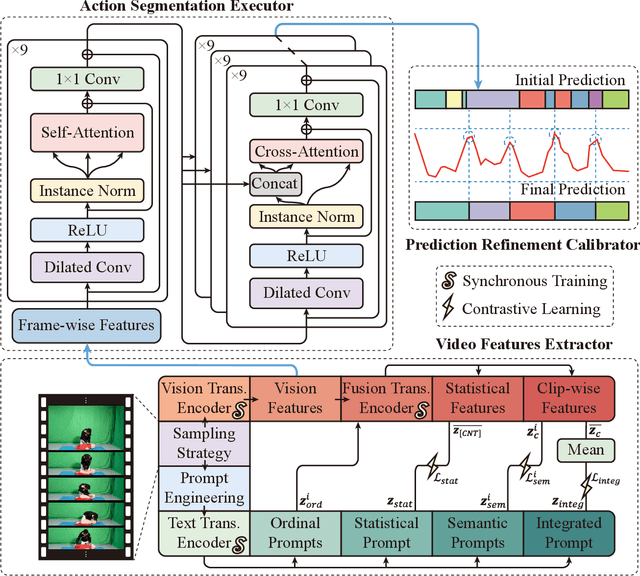
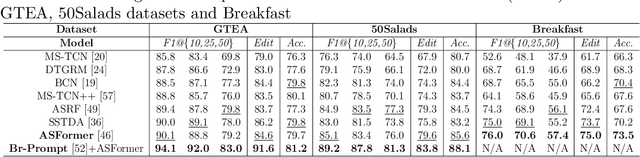

The vast majority of people who suffer unexpected cardiac arrest are performed cardiopulmonary resuscitation (CPR) by passersby in a desperate attempt to restore life, but endeavors turn out to be fruitless on account of disqualification. Fortunately, many pieces of research manifest that disciplined training will help to elevate the success rate of resuscitation, which constantly desires a seamless combination of novel techniques to yield further advancement. To this end, we collect a custom CPR video dataset in which trainees make efforts to behave resuscitation on mannequins independently in adherence to approved guidelines, thereby devising an auxiliary toolbox to assist supervision and rectification of intermediate potential issues via modern deep learning methodologies. Our research empirically views this problem as a temporal action segmentation (TAS) task in computer vision, which aims to segment an untrimmed video at a frame-wise level. Here, we propose a Prompt-enhanced hierarchical Transformer (PhiTrans) that integrates three indispensable modules, including a textual prompt-based Video Features Extractor (VFE), a transformer-based Action Segmentation Executor (ASE), and a regression-based Prediction Refinement Calibrator (PRC). The backbone of the model preferentially derives from applications in three approved public datasets (GTEA, 50Salads, and Breakfast) collected for TAS tasks, which accounts for the excavation of the segmentation pipeline on the CPR dataset. In general, we unprecedentedly probe into a feasible pipeline that genuinely elevates the CPR instruction qualification via action segmentation in conjunction with cutting-edge deep learning techniques. Associated experiments advocate our implementation with multiple metrics surpassing 91.0%.
Atrial Septal Defect Detection in Children Based on Ultrasound Video Using Multiple Instances Learning
Jun 06, 2023

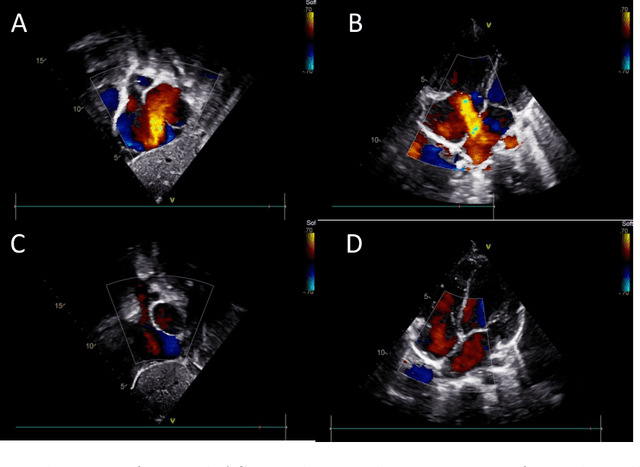
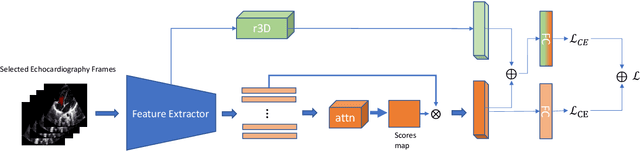
Purpose: Congenital heart defect (CHD) is the most common birth defect. Thoracic echocardiography (TTE) can provide sufficient cardiac structure information, evaluate hemodynamics and cardiac function, and is an effective method for atrial septal defect (ASD) examination. This paper aims to study a deep learning method based on cardiac ultrasound video to assist in ASD diagnosis. Materials and methods: We select two standard views of the atrial septum (subAS) and low parasternal four-compartment view (LPS4C) as the two views to identify ASD. We enlist data from 300 children patients as part of a double-blind experiment for five-fold cross-validation to verify the performance of our model. In addition, data from 30 children patients (15 positives and 15 negatives) are collected for clinician testing and compared to our model test results (these 30 samples do not participate in model training). We propose an echocardiography video-based atrial septal defect diagnosis system. In our model, we present a block random selection, maximal agreement decision and frame sampling strategy for training and testing respectively, resNet18 and r3D networks are used to extract the frame features and aggregate them to build a rich video-level representation. Results: We validate our model using our private dataset by five-cross validation. For ASD detection, we achieve 89.33 AUC, 84.95 accuracy, 85.70 sensitivity, 81.51 specificity and 81.99 F1 score. Conclusion: The proposed model is multiple instances learning-based deep learning model for video atrial septal defect detection which effectively improves ASD detection accuracy when compared to the performances of previous networks and clinical doctors.
Futuristic Variations and Analysis in Fundus Images Corresponding to Biological Traits
Feb 08, 2023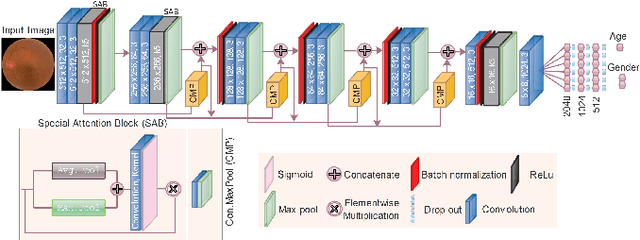
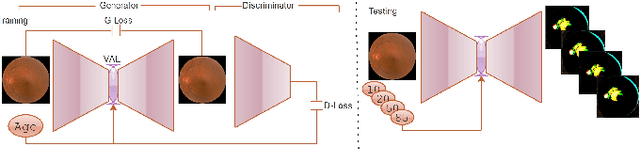
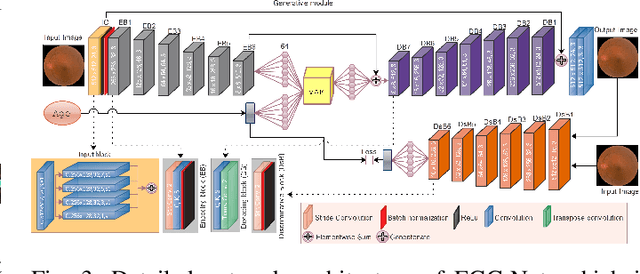

Fundus image captures rear of an eye, and which has been studied for the diseases identification, classification, segmentation, generation, and biological traits association using handcrafted, conventional, and deep learning methods. In biological traits estimation, most of the studies have been carried out for the age prediction and gender classification with convincing results. However, the current study utilizes the cutting-edge deep learning (DL) algorithms to estimate biological traits in terms of age and gender together with associating traits to retinal visuals. For the traits association, our study embeds aging as the label information into the proposed DL model to learn knowledge about the effected regions with aging. Our proposed DL models, named FAG-Net and FGC-Net, correspondingly estimate biological traits (age and gender) and generates fundus images. FAG-Net can generate multiple variants of an input fundus image given a list of ages as conditions. Our study analyzes fundus images and their corresponding association with biological traits, and predicts of possible spreading of ocular disease on fundus images given age as condition to the generative model. Our proposed models outperform the randomly selected state of-the-art DL models.
DuAT: Dual-Aggregation Transformer Network for Medical Image Segmentation
Dec 21, 2022



Transformer-based models have been widely demonstrated to be successful in computer vision tasks by modelling long-range dependencies and capturing global representations. However, they are often dominated by features of large patterns leading to the loss of local details (e.g., boundaries and small objects), which are critical in medical image segmentation. To alleviate this problem, we propose a Dual-Aggregation Transformer Network called DuAT, which is characterized by two innovative designs, namely, the Global-to-Local Spatial Aggregation (GLSA) and Selective Boundary Aggregation (SBA) modules. The GLSA has the ability to aggregate and represent both global and local spatial features, which are beneficial for locating large and small objects, respectively. The SBA module is used to aggregate the boundary characteristic from low-level features and semantic information from high-level features for better preserving boundary details and locating the re-calibration objects. Extensive experiments in six benchmark datasets demonstrate that our proposed model outperforms state-of-the-art methods in the segmentation of skin lesion images, and polyps in colonoscopy images. In addition, our approach is more robust than existing methods in various challenging situations such as small object segmentation and ambiguous object boundaries.
Neuro-Symbolic Learning: Principles and Applications in Ophthalmology
Jul 31, 2022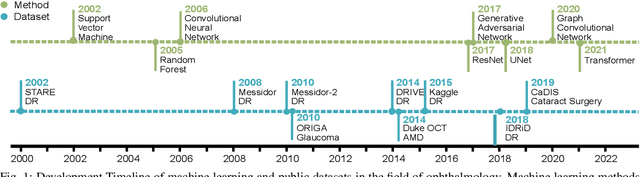
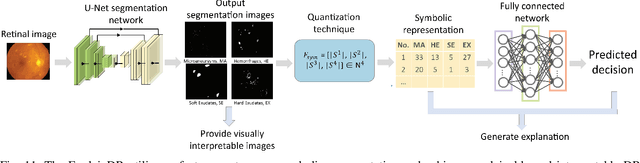
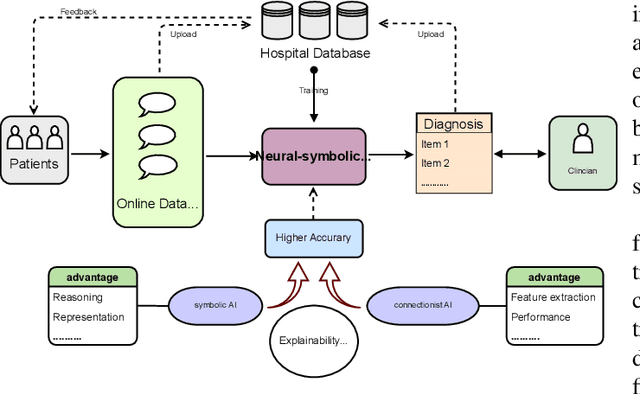
Neural networks have been rapidly expanding in recent years, with novel strategies and applications. However, challenges such as interpretability, explainability, robustness, safety, trust, and sensibility remain unsolved in neural network technologies, despite the fact that they will unavoidably be addressed for critical applications. Attempts have been made to overcome the challenges in neural network computing by representing and embedding domain knowledge in terms of symbolic representations. Thus, the neuro-symbolic learning (NeSyL) notion emerged, which incorporates aspects of symbolic representation and bringing common sense into neural networks (NeSyL). In domains where interpretability, reasoning, and explainability are crucial, such as video and image captioning, question-answering and reasoning, health informatics, and genomics, NeSyL has shown promising outcomes. This review presents a comprehensive survey on the state-of-the-art NeSyL approaches, their principles, advances in machine and deep learning algorithms, applications such as opthalmology, and most importantly, future perspectives of this emerging field.
Mixed-UNet: Refined Class Activation Mapping for Weakly-Supervised Semantic Segmentation with Multi-scale Inference
May 06, 2022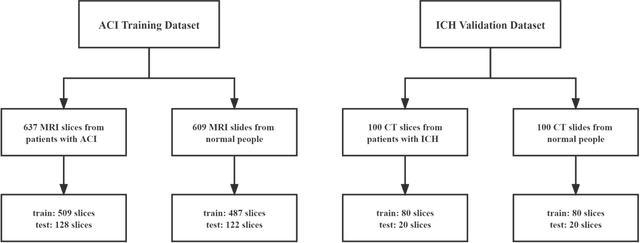
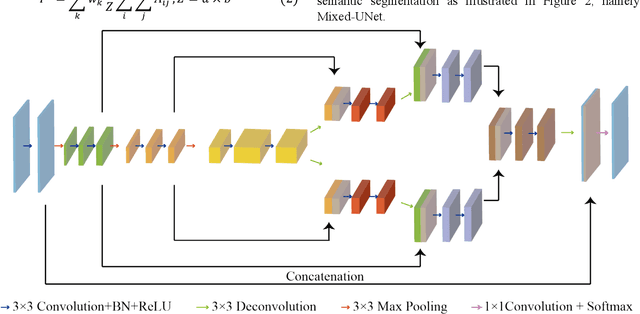
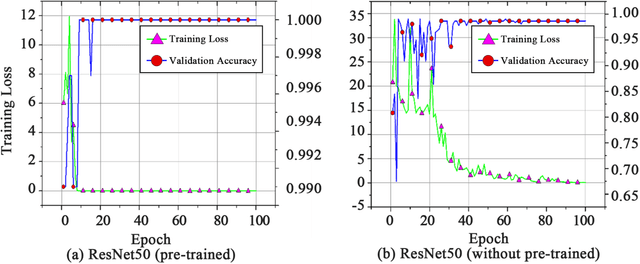
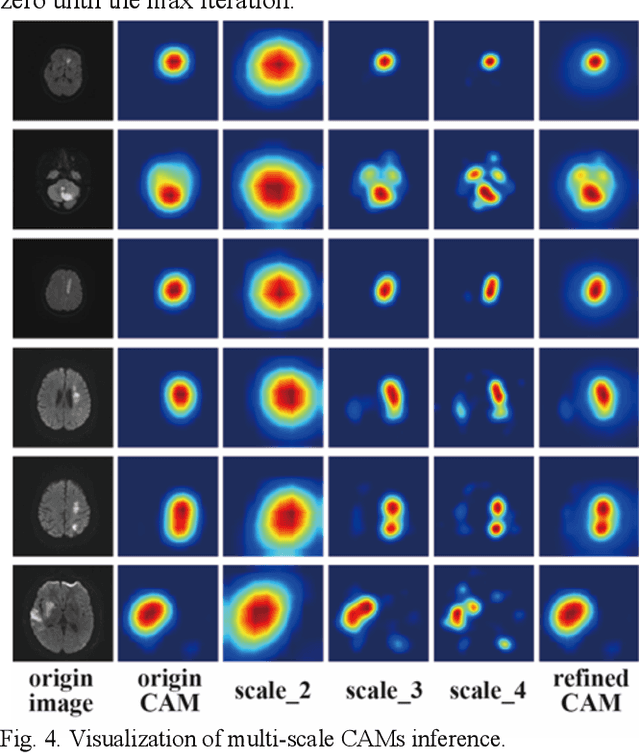
Deep learning techniques have shown great potential in medical image processing, particularly through accurate and reliable image segmentation on magnetic resonance imaging (MRI) scans or computed tomography (CT) scans, which allow the localization and diagnosis of lesions. However, training these segmentation models requires a large number of manually annotated pixel-level labels, which are time-consuming and labor-intensive, in contrast to image-level labels that are easier to obtain. It is imperative to resolve this problem through weakly-supervised semantic segmentation models using image-level labels as supervision since it can significantly reduce human annotation efforts. Most of the advanced solutions exploit class activation mapping (CAM). However, the original CAMs rarely capture the precise boundaries of lesions. In this study, we propose the strategy of multi-scale inference to refine CAMs by reducing the detail loss in single-scale reasoning. For segmentation, we develop a novel model named Mixed-UNet, which has two parallel branches in the decoding phase. The results can be obtained after fusing the extracted features from two branches. We evaluate the designed Mixed-UNet against several prevalent deep learning-based segmentation approaches on our dataset collected from the local hospital and public datasets. The validation results demonstrate that our model surpasses available methods under the same supervision level in the segmentation of various lesions from brain imaging.