 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew Exemplar-Based General Medical Image Segmentation via Domain-Aware Selective Adaptation
Oct 11, 2024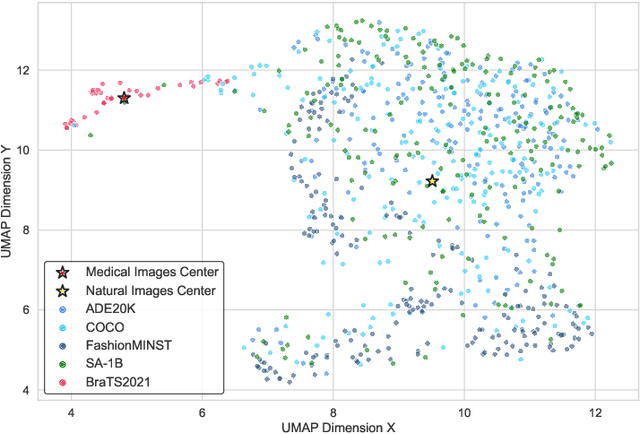
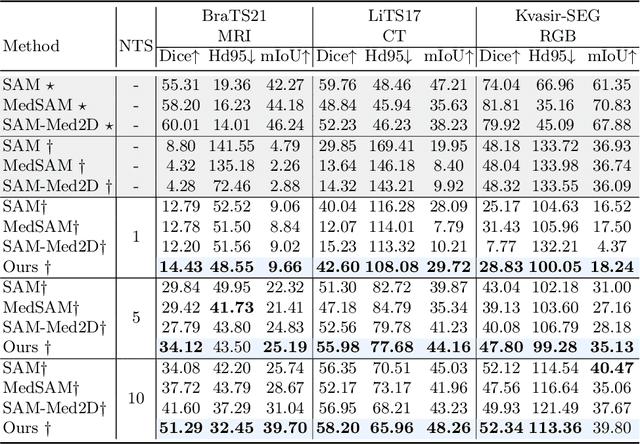
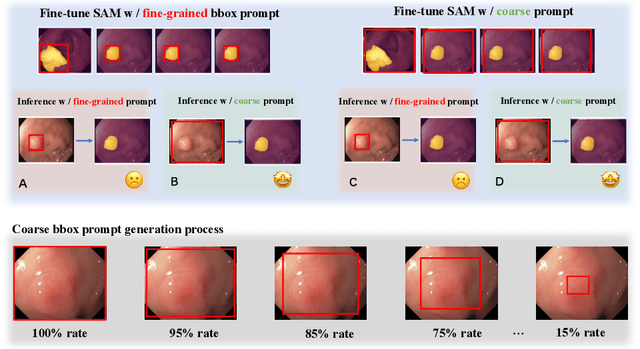
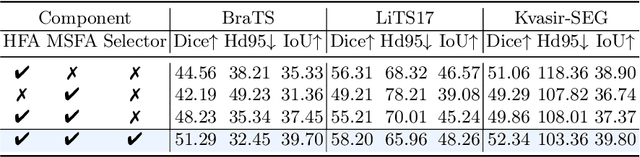
Medical image segmentation poses challenges due to domain gaps, data modality variations, and dependency on domain knowledge or experts, especially for low- and middle-income countries (LMICs). Whereas for humans, given a few exemplars (with corresponding labels), we are able to segment different medical images even without exten-sive domain-specific clinical training. In addition, current SAM-based medical segmentation models use fine-grained visual prompts, such as the bounding rectangle generated from manually annotated target segmentation mask, as the bounding box (bbox) prompt during the testing phase. However, in actual clinical scenarios, no such precise prior knowledge is available. Our experimental results also reveal that previous models nearly fail to predict when given coarser bbox prompts. Considering these issues, in this paper, we introduce a domain-aware selective adaptation approach to adapt the general knowledge learned from a large model trained with natural images to the corresponding medical domains/modalities, with access to only a few (e.g. less than 5) exemplars. Our method mitigates the aforementioned limitations, providing an efficient and LMICs-friendly solution. Extensive experimental analysis showcases the effectiveness of our approach, offering potential advancements in healthcare diagnostics and clinical applications in LMICs.
360+x: A Panoptic Multi-modal Scene Understanding Dataset
Apr 08, 2024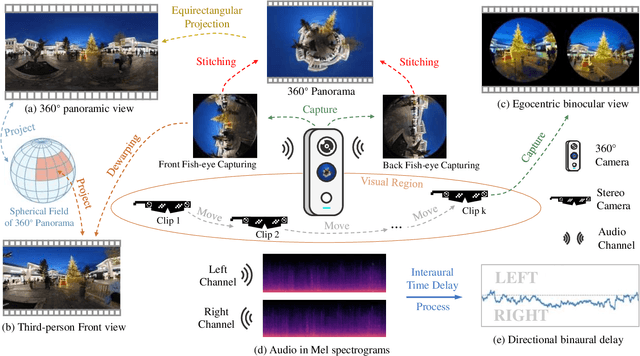
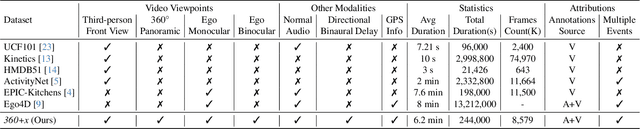
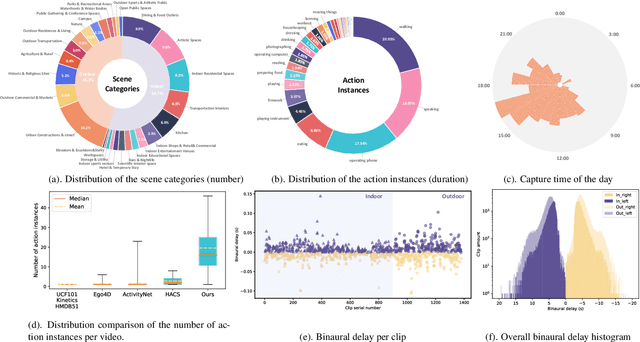
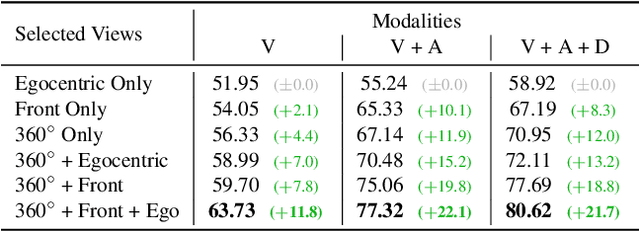
Human perception of the world is shaped by a multitude of viewpoints and modalities. While many existing datasets focus on scene understanding from a certain perspective (e.g. egocentric or third-person views), our dataset offers a panoptic perspective (i.e. multiple viewpoints with multiple data modalities). Specifically, we encapsulate third-person panoramic and front views, as well as egocentric monocular/binocular views with rich modalities including video, multi-channel audio, directional binaural delay, location data and textual scene descriptions within each scene captured, presenting comprehensive observation of the world. Figure 1 offers a glimpse of all 28 scene categories of our 360+x dataset. To the best of our knowledge, this is the first database that covers multiple viewpoints with multiple data modalities to mimic how daily information is accessed in the real world. Through our benchmark analysis, we presented 5 different scene understanding tasks on the proposed 360+x dataset to evaluate the impact and benefit of each data modality and perspective in panoptic scene understanding. We hope this unique dataset could broaden the scope of comprehensive scene understanding and encourage the community to approach these problems from more diverse perspectives.
* CVPR 2024 (Oral Presentation), Project page: https://x360dataset.github.io/
Multi-Modal Gaze Following in Conversational Scenarios
Nov 09, 2023Gaze following estimates gaze targets of in-scene person by understanding human behavior and scene information. Existing methods usually analyze scene images for gaze following. However, compared with visual images, audio also provides crucial cues for determining human behavior.This suggests that we can further improve gaze following considering audio cues. In this paper, we explore gaze following tasks in conversational scenarios. We propose a novel multi-modal gaze following framework based on our observation ``audiences tend to focus on the speaker''. We first leverage the correlation between audio and lips, and classify speakers and listeners in a scene. We then use the identity information to enhance scene images and propose a gaze candidate estimation network. The network estimates gaze candidates from enhanced scene images and we use MLP to match subjects with candidates as classification tasks. Existing gaze following datasets focus on visual images while ignore audios.To evaluate our method, we collect a conversational dataset, VideoGazeSpeech (VGS), which is the first gaze following dataset including images and audio. Our method significantly outperforms existing methods in VGS datasets. The visualization result also prove the advantage of audio cues in gaze following tasks. Our work will inspire more researches in multi-modal gaze following estimation.