 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360+x: A Panoptic Multi-modal Scene Understanding Dataset
Apr 08, 2024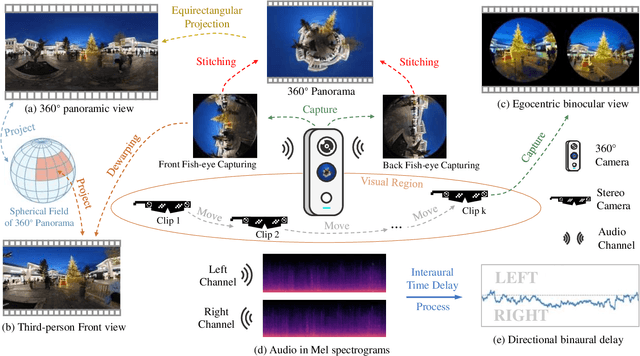
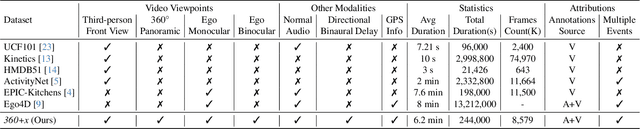
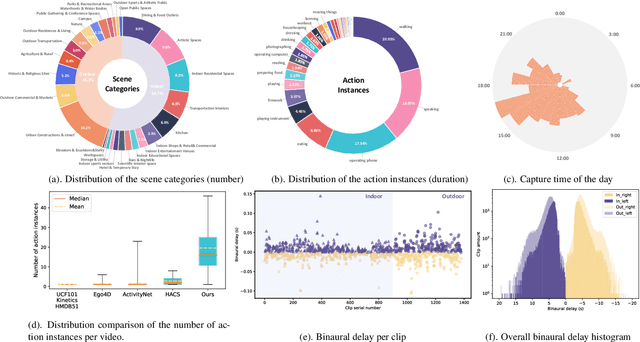
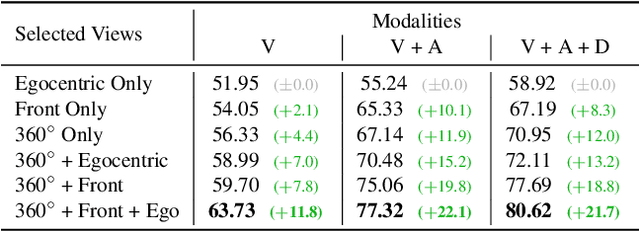
Human perception of the world is shaped by a multitude of viewpoints and modalities. While many existing datasets focus on scene understanding from a certain perspective (e.g. egocentric or third-person views), our dataset offers a panoptic perspective (i.e. multiple viewpoints with multiple data modalities). Specifically, we encapsulate third-person panoramic and front views, as well as egocentric monocular/binocular views with rich modalities including video, multi-channel audio, directional binaural delay, location data and textual scene descriptions within each scene captured, presenting comprehensive observation of the world. Figure 1 offers a glimpse of all 28 scene categories of our 360+x dataset. To the best of our knowledge, this is the first database that covers multiple viewpoints with multiple data modalities to mimic how daily information is accessed in the real world. Through our benchmark analysis, we presented 5 different scene understanding tasks on the proposed 360+x dataset to evaluate the impact and benefit of each data modality and perspective in panoptic scene understanding. We hope this unique dataset could broaden the scope of comprehensive scene understanding and encourage the community to approach these problems from more diverse perspectives.
* CVPR 2024 (Oral Presentation), Project page: https://x360dataset.github.io/
Marine Microalgae Detection in Microscopy Images: A New Dataset
Nov 14, 2022



Marine microalgae are widespread in the ocean and play a crucial role in the ecosystem. Automatic identification and location of marine microalgae in microscopy images would help establish marine ecological environment monitoring and water quality evaluation system. A new dataset for marine microalgae detection is proposed in this paper. Six classes of microalgae commonlyfound in the ocean (Bacillariophyta, Chlorella pyrenoidosa, Platymonas, Dunaliella salina, Chrysophyta, Symbiodiniaceae) are microscopically imaged in real-time. Images of Symbiodiniaceae in three physiological states known as normal, bleaching, and translating are also included. We annotated these images with bounding boxes using Labelme software and split them into the training and testing sets. The total number of images in the dataset is 937 and all the objects in these images were annotated. The total number of annotated objects is 4201. The training set contains 537 images and the testing set contains 430 images. Baselines of different object detection algorithms are trained, validated and tested on this dataset. This data set can be got accessed via tianchi.aliyun.com/competition/entrance/532036/information.