 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Image Representation with Decoupled Classical Visual Descriptors
Oct 16, 2025Exploring and understanding efficient image representations is a long-standing challenge in computer vision. While deep learning has achieved remarkable progress across image understanding tasks, its internal representations are often opaque, making it difficult to interpret how visual information is processed. In contrast, classical visual descriptors (e.g. edge, colour, and intensity distribution) have long been fundamental to image analysis and remain intuitively understandable to humans. Motivated by this gap, we ask a central question: Can modern learning benefit from these classical cues? In this paper, we answer it with VisualSplit, a framework that explicitly decomposes images into decoupled classical descriptors, treating each as an independent but complementary component of visual knowledge. Through a reconstruction-driven pre-training scheme, VisualSplit learns to capture the essence of each visual descriptor while preserving their interpretability. By explicitly decomposing visual attributes, our method inherently facilitates effective attribute control in various advanced visual tasks, including image generation and editing, extending beyond conventional classification and segmentation, suggesting the effectiveness of this new learning approach for visual understanding. Project page: https://chenyuanqu.com/VisualSplit/.
Diffusion Features to Bridge Domain Gap for Semantic Segmentation
Jun 02, 2024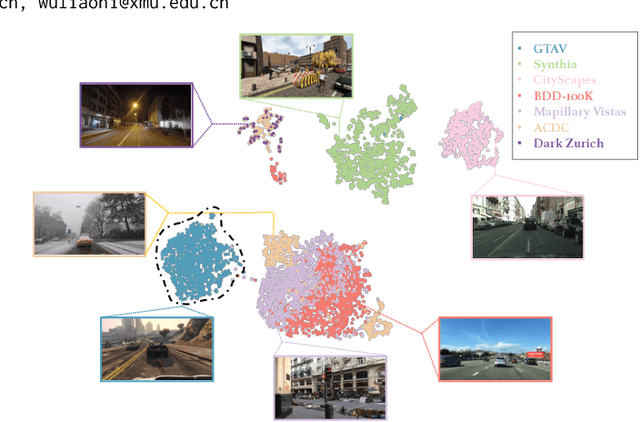
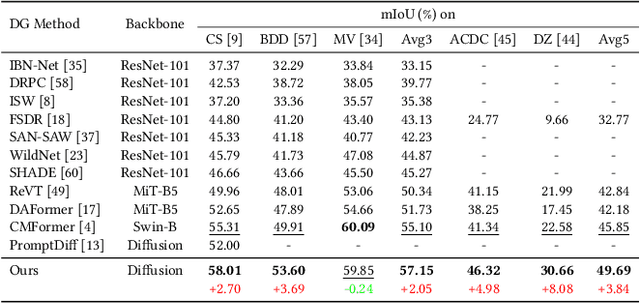


Pre-trained diffusion models have demonstrated remarkable proficiency in synthesizing images across a wide range of scenarios with customizable prompts, indicating their effective capacity to capture universal features. Motivated by this, our study delves into the utilization of the implicit knowledge embedded within diffusion models to address challenges in cross-domain semantic segmentation. This paper investigates the approach that leverages the sampling and fusion techniques to harness the features of diffusion models efficiently. Contrary to the simplistic migration applications characterized by prior research, our finding reveals that the multi-step diffusion process inherent in the diffusion model manifests more robust semantic features. We propose DIffusion Feature Fusion (DIFF) as a backbone use for extracting and integrating effective semantic representations through the diffusion process. By leveraging the strength of text-to-image generation capability, we introduce a new training framework designed to implicitly learn posterior knowledge from it. Through rigorous evaluation in the contexts of domain generalization semantic segmentation, we establish that our methodology surpasses preceding approaches in mitigating discrepancies across distinct domains and attains the state-of-the-art (SOTA) benchmark. Within the synthetic-to-real (syn-to-real) context, our method significantly outperforms ResNet-based and transformer-based backbone methods, achieving an average improvement of $3.84\%$ mIoU across various datasets. The implementation code will be released soon.
360+x: A Panoptic Multi-modal Scene Understanding Dataset
Apr 08, 2024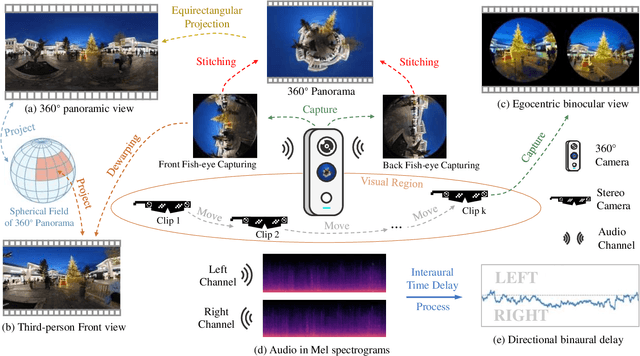
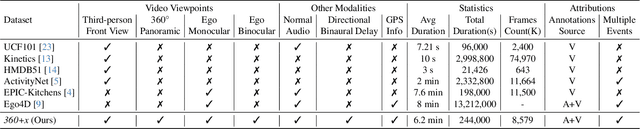
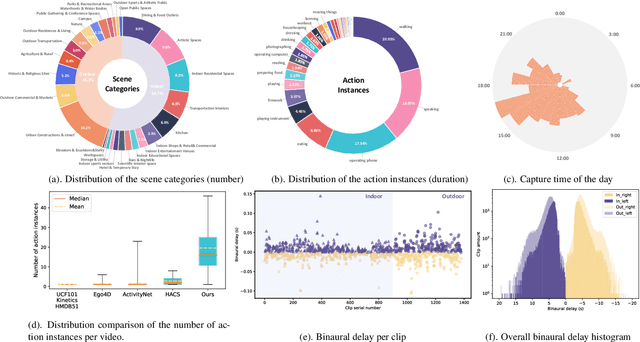
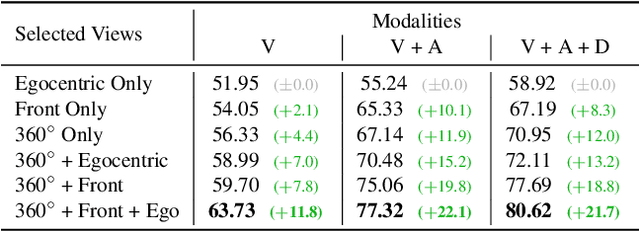
Human perception of the world is shaped by a multitude of viewpoints and modalities. While many existing datasets focus on scene understanding from a certain perspective (e.g. egocentric or third-person views), our dataset offers a panoptic perspective (i.e. multiple viewpoints with multiple data modalities). Specifically, we encapsulate third-person panoramic and front views, as well as egocentric monocular/binocular views with rich modalities including video, multi-channel audio, directional binaural delay, location data and textual scene descriptions within each scene captured, presenting comprehensive observation of the world. Figure 1 offers a glimpse of all 28 scene categories of our 360+x dataset. To the best of our knowledge, this is the first database that covers multiple viewpoints with multiple data modalities to mimic how daily information is accessed in the real world. Through our benchmark analysis, we presented 5 different scene understanding tasks on the proposed 360+x dataset to evaluate the impact and benefit of each data modality and perspective in panoptic scene understanding. We hope this unique dataset could broaden the scope of comprehensive scene understanding and encourage the community to approach these problems from more diverse perspectives.
* CVPR 2024 (Oral Presentation), Project page: https://x360dataset.github.io/
Multi-view Self-supervised Disentanglement for General Image Denoising
Sep 10, 2023



With its significant performance improvements, the deep learning paradigm has become a standard tool for modern image denoisers. While promising performance has been shown on seen noise distributions, existing approaches often suffer from generalisation to unseen noise types or general and real noise. It is understandable as the model is designed to learn paired mapping (e.g. from a noisy image to its clean version). In this paper, we instead propose to learn to disentangle the noisy image, under the intuitive assumption that different corrupted versions of the same clean image share a common latent space. A self-supervised learning framework is proposed to achieve the goal, without looking at the latent clean image. By taking two different corrupted versions of the same image as input, the proposed Multi-view Self-supervised Disentanglement (MeD) approach learns to disentangle the latent clean features from the corruptions and recover the clean image consequently. Extensive experimental analysis on both synthetic and real noise shows the superiority of the proposed method over prior self-supervised approaches, especially on unseen novel noise types. On real noise, the proposed method even outperforms its supervised counterparts by over 3 dB.