 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Domain Generalized and Adaptive Detection with Diffusion Models: Fitness, Generalization, and Transferability
Jun 26, 2025Detectors often suffer from performance drop due to domain gap between training and testing data. Recent methods explore diffusion models applied to domain generalization (DG) and adaptation (DA) tasks, but still struggle with large inference costs and have not yet fully leveraged the capabilities of diffusion models. We propose to tackle these problems by extracting intermediate features from a single-step diffusion process, improving feature collection and fusion to reduce inference time by 75% while enhancing performance on source domains (i.e., Fitness). Then, we construct an object-centered auxiliary branch by applying box-masked images with class prompts to extract robust and domain-invariant features that focus on object. We also apply consistency loss to align the auxiliary and ordinary branch, balancing fitness and generalization while preventing overfitting and improving performance on target domains (i.e., Generalization). Furthermore, within a unified framework, standard detectors are guided by diffusion detectors through feature-level and object-level alignment on source domains (for DG) and unlabeled target domains (for DA), thereby improving cross-domain detection performance (i.e., Transferability). Our method achieves competitive results on 3 DA benchmarks and 5 DG benchmarks. Additionally, experiments on COCO generalization benchmark demonstrate that our method maintains significant advantages and show remarkable efficiency in large domain shifts and low-data scenarios. Our work shows the superiority of applying diffusion models to domain generalized and adaptive detection tasks and offers valuable insights for visual perception tasks across diverse domains. The code is available at \href{https://github.com/heboyong/Fitness-Generalization-Transferability}{Fitness-Generalization-Transferability}.
VisLanding: Monocular 3D Perception for UAV Safe Landing via Depth-Normal Synergy
Jun 17, 2025This paper presents VisLanding, a monocular 3D perception-based framework for safe UAV (Unmanned Aerial Vehicle) landing. Addressing the core challenge of autonomous UAV landing in complex and unknown environments, this study innovatively leverages the depth-normal synergy prediction capabilities of the Metric3D V2 model to construct an end-to-end safe landing zones (SLZ) estimation framework. By introducing a safe zone segmentation branch, we transform the landing zone estimation task into a binary semantic segmentation problem. The model is fine-tuned and annotated using the WildUAV dataset from a UAV perspective, while a cross-domain evaluation dataset is constructed to validate the model's robustness. Experimental results demonstrate that VisLanding significantly enhances the accuracy of safe zone identification through a depth-normal joint optimization mechanism, while retaining the zero-shot generalization advantages of Metric3D V2. The proposed method exhibits superior generalization and robustness in cross-domain testing compared to other approaches. Furthermore, it enables the estimation of landing zone area by integrating predicted depth and normal information, providing critical decision-making support for practical applications.
Diffusion Domain Teacher: Diffusion Guided Domain Adaptive Object Detector
Jun 04, 2025Object detectors often suffer a decrease in performance due to the large domain gap between the training data (source domain) and real-world data (target domain). Diffusion-based generative models have shown remarkable abilities in generating high-quality and diverse images, suggesting their potential for extracting valuable feature from various domains. To effectively leverage the cross-domain feature representation of diffusion models, in this paper, we train a detector with frozen-weight diffusion model on the source domain, then employ it as a teacher model to generate pseudo labels on the unlabeled target domain, which are used to guide the supervised learning of the student model on the target domain. We refer to this approach as Diffusion Domain Teacher (DDT). By employing this straightforward yet potent framework, we significantly improve cross-domain object detection performance without compromising the inference speed. Our method achieves an average mAP improvement of 21.2% compared to the baseline on 6 datasets from three common cross-domain detection benchmarks (Cross-Camera, Syn2Real, Real2Artistic}, surpassing the current state-of-the-art (SOTA) methods by an average of 5.7% mAP. Furthermore, extensive experiments demonstrate that our method consistently brings improvements even in more powerful and complex models, highlighting broadly applicable and effective domain adaptation capability of our DDT. The code is available at https://github.com/heboyong/Diffusion-Domain-Teacher.
Generalized Diffusion Detector: Mining Robust Features from Diffusion Models for Domain-Generalized Detection
Mar 03, 2025



Domain generalization (DG) for object detection aims to enhance detectors' performance in unseen scenarios. This task remains challenging due to complex variations in real-world applications. Recently, diffusion models have demonstrated remarkable capabilities in diverse scene generation, which inspires us to explore their potential for improving DG tasks. Instead of generating images, our method extracts multi-step intermediate features during the diffusion process to obtain domain-invariant features for generalized detection. Furthermore, we propose an efficient knowledge transfer framework that enables detectors to inherit the generalization capabilities of diffusion models through feature and object-level alignment, without increasing inference time. We conduct extensive experiments on six challenging DG benchmarks. The results demonstrate that our method achieves substantial improvements of 14.0% mAP over existing DG approaches across different domains and corruption types. Notably, our method even outperforms most domain adaptation methods without accessing any target domain data. Moreover, the diffusion-guided detectors show consistent improvements of 15.9% mAP on average compared to the baseline. Our work aims to present an effective approach for domain-generalized detection and provide potential insights for robust visual recognition in real-world scenarios. The code is available at \href{https://github.com/heboyong/Generalized-Diffusion-Detector}{Generalized Diffusion Detector}
Game4Loc: A UAV Geo-Localization Benchmark from Game Data
Sep 25, 2024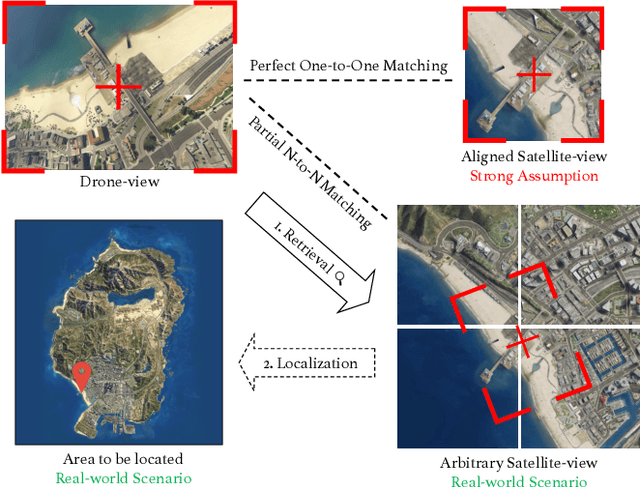


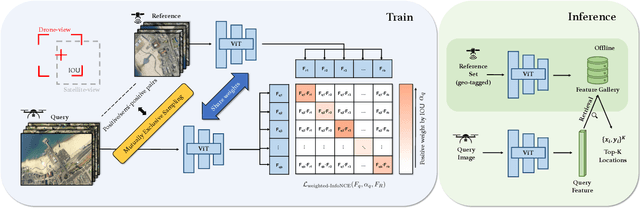
The vision-based geo-localization technology for UAV, serving as a secondary source of GPS information in addition to the global navigation satellite systems (GNSS), can still operate independently in the GPS-denied environment. Recent deep learning based methods attribute this as the task of image matching and retrieval. By retrieving drone-view images in geo-tagged satellite image database, approximate localization information can be obtained. However, due to high costs and privacy concerns, it is usually difficult to obtain large quantities of drone-view images from a continuous area. Existing drone-view datasets are mostly composed of small-scale aerial photography with a strong assumption that there exists a perfect one-to-one aligned reference image for any query, leaving a significant gap from the practical localization scenario. In this work, we construct a large-range contiguous area UAV geo-localization dataset named GTA-UAV, featuring multiple flight altitudes, attitudes, scenes, and targets using modern computer games. Based on this dataset, we introduce a more practical UAV geo-localization task including partial matches of cross-view paired data, and expand the image-level retrieval to the actual localization in terms of distance (meters). For the construction of drone-view and satellite-view pairs, we adopt a weight-based contrastive learning approach, which allows for effective learning while avoiding additional post-processing matching steps. Experiments demonstrate the effectiveness of our data and training method for UAV geo-localization, as well as the generalization capabilities to real-world scenarios.
Diffusion Features to Bridge Domain Gap for Semantic Segmentation
Jun 02, 2024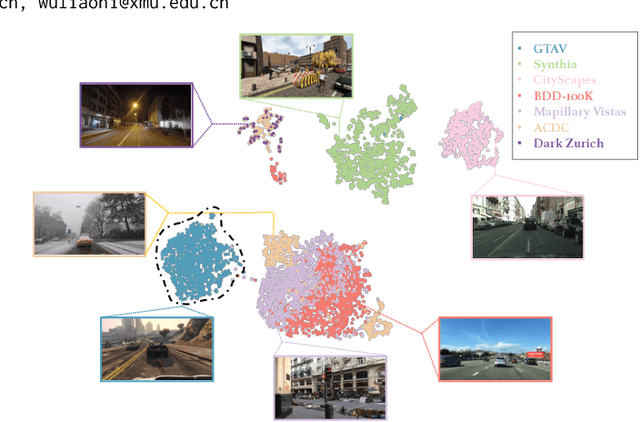
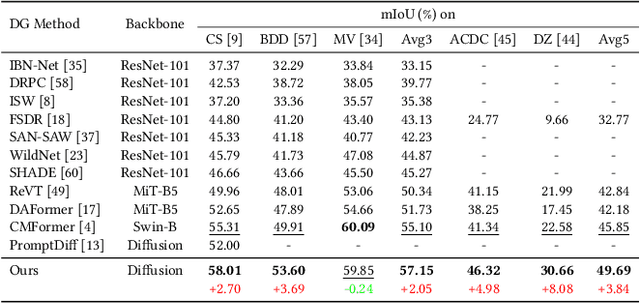


Pre-trained diffusion models have demonstrated remarkable proficiency in synthesizing images across a wide range of scenarios with customizable prompts, indicating their effective capacity to capture universal features. Motivated by this, our study delves into the utilization of the implicit knowledge embedded within diffusion models to address challenges in cross-domain semantic segmentation. This paper investigates the approach that leverages the sampling and fusion techniques to harness the features of diffusion models efficiently. Contrary to the simplistic migration applications characterized by prior research, our finding reveals that the multi-step diffusion process inherent in the diffusion model manifests more robust semantic features. We propose DIffusion Feature Fusion (DIFF) as a backbone use for extracting and integrating effective semantic representations through the diffusion process. By leveraging the strength of text-to-image generation capability, we introduce a new training framework designed to implicitly learn posterior knowledge from it. Through rigorous evaluation in the contexts of domain generalization semantic segmentation, we establish that our methodology surpasses preceding approaches in mitigating discrepancies across distinct domains and attains the state-of-the-art (SOTA) benchmark. Within the synthetic-to-real (syn-to-real) context, our method significantly outperforms ResNet-based and transformer-based backbone methods, achieving an average improvement of $3.84\%$ mIoU across various datasets. The implementation code will be released soon.