 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Gaze Following in Conversational Scenarios
Nov 09, 2023Gaze following estimates gaze targets of in-scene person by understanding human behavior and scene information. Existing methods usually analyze scene images for gaze following. However, compared with visual images, audio also provides crucial cues for determining human behavior.This suggests that we can further improve gaze following considering audio cues. In this paper, we explore gaze following tasks in conversational scenarios. We propose a novel multi-modal gaze following framework based on our observation ``audiences tend to focus on the speaker''. We first leverage the correlation between audio and lips, and classify speakers and listeners in a scene. We then use the identity information to enhance scene images and propose a gaze candidate estimation network. The network estimates gaze candidates from enhanced scene images and we use MLP to match subjects with candidates as classification tasks. Existing gaze following datasets focus on visual images while ignore audios.To evaluate our method, we collect a conversational dataset, VideoGazeSpeech (VGS), which is the first gaze following dataset including images and audio. Our method significantly outperforms existing methods in VGS datasets. The visualization result also prove the advantage of audio cues in gaze following tasks. Our work will inspire more researches in multi-modal gaze following estimation.
Repurposing Existing Deep Networks for Caption and Aesthetic-Guided Image Cropping
Jan 07, 2022
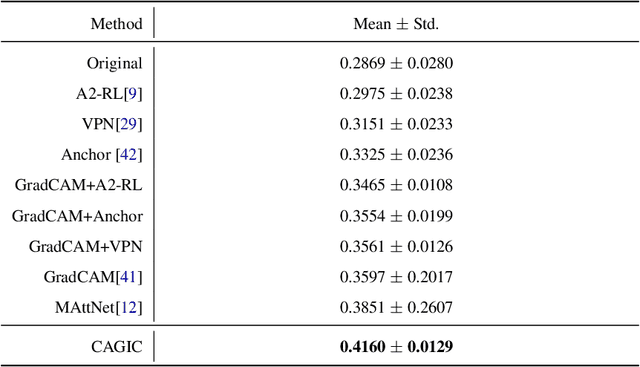
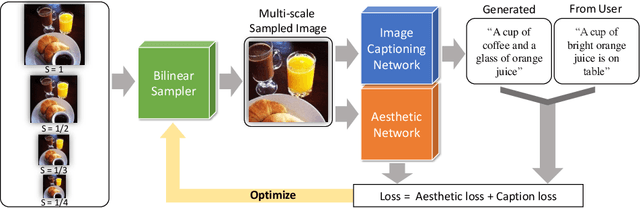
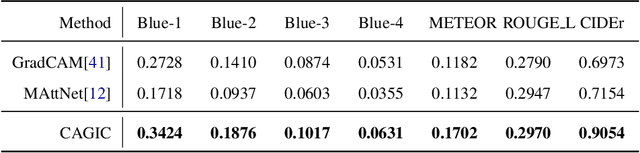
We propose a novel optimization framework that crops a given image based on user description and aesthetics. Unlike existing image cropping methods, where one typically trains a deep network to regress to crop parameters or cropping actions, we propose to directly optimize for the cropping parameters by repurposing pre-trained networks on image captioning and aesthetic tasks, without any fine-tuning, thereby avoiding training a separate network. Specifically, we search for the best crop parameters that minimize a combined loss of the initial objectives of these networks. To make the optimization table, we propose three strategies: (i) multi-scale bilinear sampling, (ii) annealing the scale of the crop region, therefore effectively reducing the parameter space, (iii) aggregation of multiple optimization results. Through various quantitative and qualitative evaluations, we show that our framework can produce crops that are well-aligned to intended user descriptions and aesthetically pleasing.