 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing Existing Deep Networks for Caption and Aesthetic-Guided Image Cropping
Jan 07, 2022
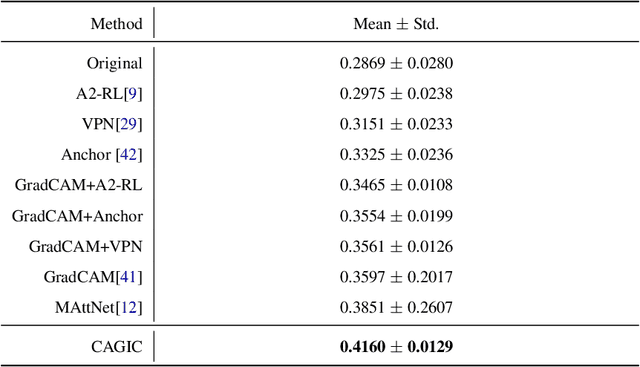
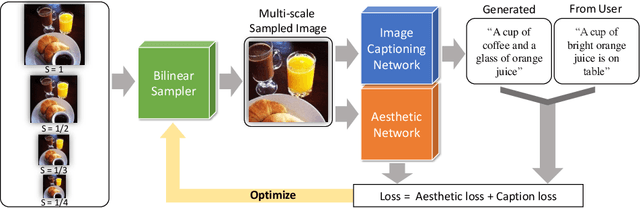
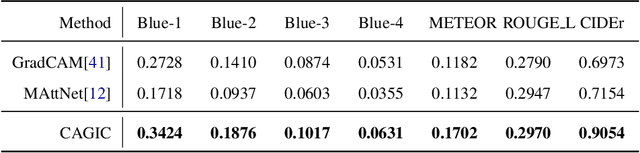
We propose a novel optimization framework that crops a given image based on user description and aesthetics. Unlike existing image cropping methods, where one typically trains a deep network to regress to crop parameters or cropping actions, we propose to directly optimize for the cropping parameters by repurposing pre-trained networks on image captioning and aesthetic tasks, without any fine-tuning, thereby avoiding training a separate network. Specifically, we search for the best crop parameters that minimize a combined loss of the initial objectives of these networks. To make the optimization table, we propose three strategies: (i) multi-scale bilinear sampling, (ii) annealing the scale of the crop region, therefore effectively reducing the parameter space, (iii) aggregation of multiple optimization results. Through various quantitative and qualitative evaluations, we show that our framework can produce crops that are well-aligned to intended user descriptions and aesthetically pleasing.
HandSeg: An Automatically Labeled Dataset for Hand Segmentation from Depth Images
Aug 02, 2018
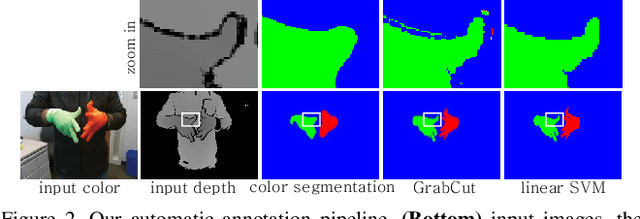
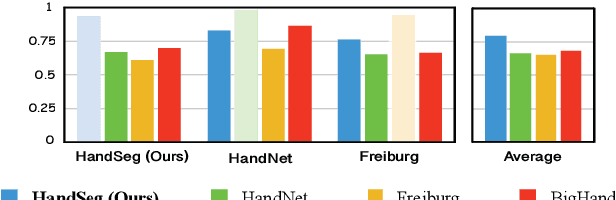
We propose an automatic method for generating high-quality annotations for depth-based hand segmentation, and introduce a large-scale hand segmentation dataset. Existing datasets are typically limited to a single hand. By exploiting the visual cues given by an RGBD sensor and a pair of colored gloves, we automatically generate dense annotations for two hand segmentation. This lowers the cost/complexity of creating high quality datasets, and makes it easy to expand the dataset in the future. We further show that existing datasets, even with data augmentation, are not sufficient to train a hand segmentation algorithm that can distinguish two hands. Source and datasets will be made publicly available.