 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHO-3D: A Multi-User, Multi-Object Dataset for Joint 3D Hand-Object Pose Estimation
Jul 02, 2019


We propose a new dataset for 3D hand+object pose estimation from color images, together with a method for efficiently annotating this dataset, and a 3D pose prediction method based on this dataset. The current lack of training data makes the 3D hand+object pose estimation very challenging. This lack is due to the complexity of labeling many real images with both 3D poses and of generating synthetic images with various realistic interaction. Moreover, even if synthetic images could be used for training, annotated real images are still needed for validation. To tackle this challenge, we capture sequences with a simple setup made of a single RGB-D camera. We also use a color camera imaging the sequences from a side view, but only for validation. We introduce a novel method based on global optimization that exploits depth, color, and temporal constraints for efficiently annotating the sequences, which we use to train another novel method that predicts both the 3D poses of the hand and the object from a single color image. Our hope is to encourage other researchers to develop better annotation methods for our dataset: One can then apply such method to capture and easily annotate sequences captured with a single RGB-D camera to easily create additional training data thus solving one of the main problems of 3D hand+object pose estimation.
Generalized Feedback Loop for Joint Hand-Object Pose Estimation
Mar 25, 2019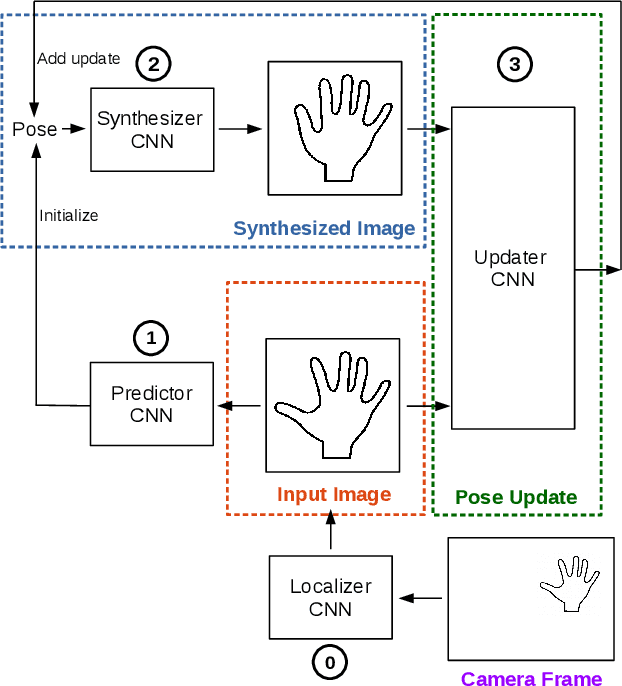
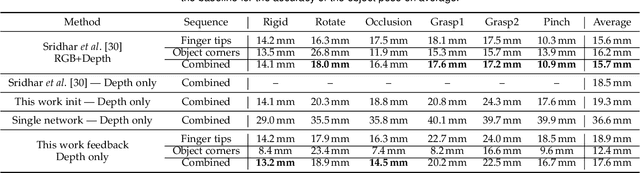
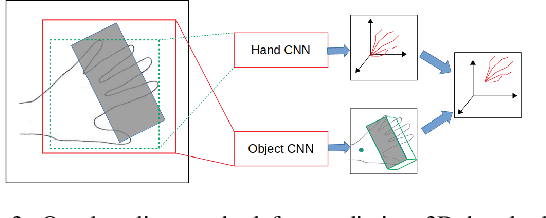
We propose an approach to estimating the 3D pose of a hand, possibly handling an object, given a depth image. We show that we can correct the mistakes made by a Convolutional Neural Network trained to predict an estimate of the 3D pose by using a feedback loop. The components of this feedback loop are also Deep Networks, optimized using training data. This approach can be generalized to a hand interacting with an object. Therefore, we jointly estimate the 3D pose of the hand and the 3D pose of the object. Our approach performs en-par with state-of-the-art methods for 3D hand pose estimation, and outperforms state-of-the-art methods for joint hand-object pose estimation when using depth images only. Also, our approach is efficient as our implementation runs in real-time on a single GPU.
* arXiv admin note: substantial text overlap with arXiv:1609.09698
Domain Transfer for 3D Pose Estimation from Color Images without Manual Annotations
Oct 08, 2018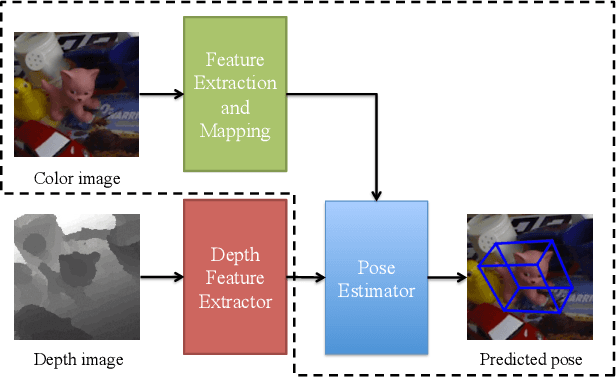

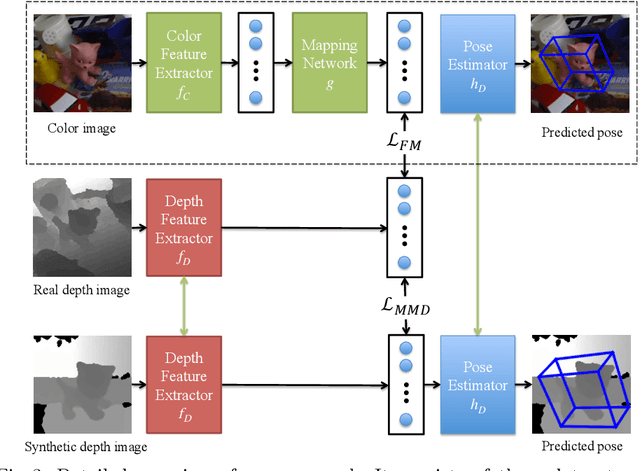
We introduce a novel learning method for 3D pose estimation from color images. While acquiring annotations for color images is a difficult task, our approach circumvents this problem by learning a mapping from paired color and depth images captured with an RGB-D camera. We jointly learn the pose from synthetic depth images that are easy to generate, and learn to align these synthetic depth images with the real depth images. We show our approach for the task of 3D hand pose estimation and 3D object pose estimation, both from color images only. Our method achieves performances comparable to state-of-the-art methods on popular benchmark datasets, without requiring any annotations for the color images.
HandSeg: An Automatically Labeled Dataset for Hand Segmentation from Depth Images
Aug 02, 2018
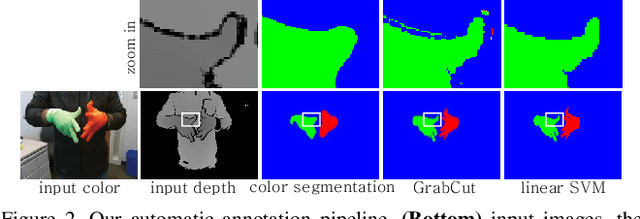
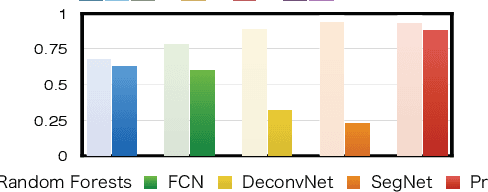
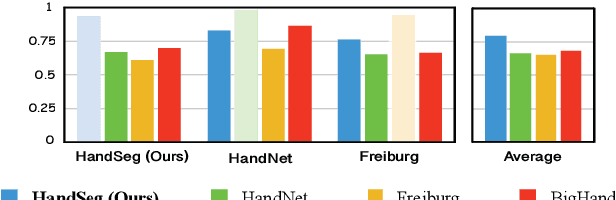
We propose an automatic method for generating high-quality annotations for depth-based hand segmentation, and introduce a large-scale hand segmentation dataset. Existing datasets are typically limited to a single hand. By exploiting the visual cues given by an RGBD sensor and a pair of colored gloves, we automatically generate dense annotations for two hand segmentation. This lowers the cost/complexity of creating high quality datasets, and makes it easy to expand the dataset in the future. We further show that existing datasets, even with data augmentation, are not sufficient to train a hand segmentation algorithm that can distinguish two hands. Source and datasets will be made publicly available.
Making Deep Heatmaps Robust to Partial Occlusions for 3D Object Pose Estimation
Jul 26, 2018

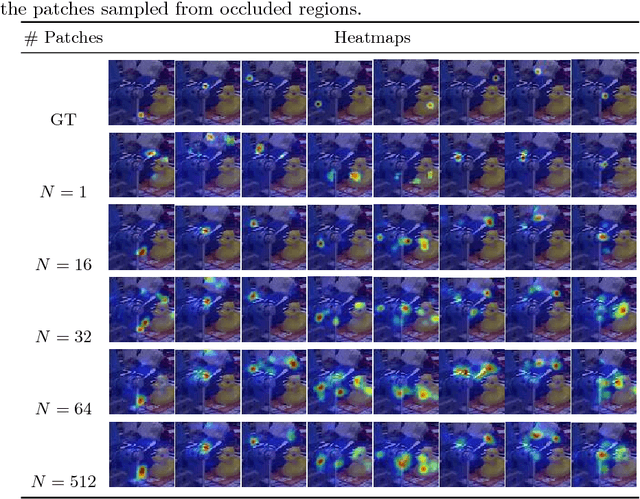

We introduce a novel method for robust and accurate 3D object pose estimation from a single color image under large occlusions. Following recent approaches, we first predict the 2D projections of 3D points related to the target object and then compute the 3D pose from these correspondences using a geometric method. Unfortunately, as the results of our experiments show, predicting these 2D projections using a regular CNN or a Convolutional Pose Machine is highly sensitive to partial occlusions, even when these methods are trained with partially occluded examples. Our solution is to predict heatmaps from multiple small patches independently and to accumulate the results to obtain accurate and robust predictions. Training subsequently becomes challenging because patches with similar appearances but different positions on the object correspond to different heatmaps. However, we provide a simple yet effective solution to deal with such ambiguities. We show that our approach outperforms existing methods on two challenging datasets: The Occluded LineMOD dataset and the YCB-Video dataset, both exhibiting cluttered scenes with highly occluded objects. Project website: https://www.tugraz.at/institute/icg/research/team-lepetit/research-projects/robust-object-pose-estimation/
Feature Mapping for Learning Fast and Accurate 3D Pose Inference from Synthetic Images
Mar 26, 2018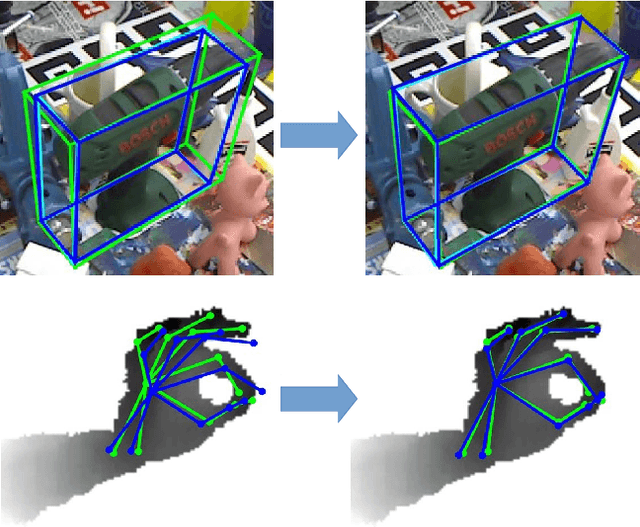



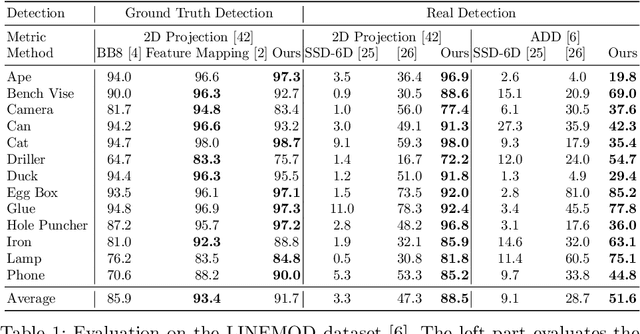
We propose a simple and efficient method for exploiting synthetic images when training a Deep Network to predict a 3D pose from an image. The ability of using synthetic images for training a Deep Network is extremely valuable as it is easy to create a virtually infinite training set made of such images, while capturing and annotating real images can be very cumbersome. However, synthetic images do not resemble real images exactly, and using them for training can result in suboptimal performance. It was recently shown that for exemplar-based approaches, it is possible to learn a mapping from the exemplar representations of real images to the exemplar representations of synthetic images. In this paper, we show that this approach is more general, and that a network can also be applied after the mapping to infer a 3D pose: At run time, given a real image of the target object, we first compute the features for the image, map them to the feature space of synthetic images, and finally use the resulting features as input to another network which predicts the 3D pose. Since this network can be trained very effectively by using synthetic images, it performs very well in practice, and inference is faster and more accurate than with an exemplar-based approach. We demonstrate our approach on the LINEMOD dataset for 3D object pose estimation from color images, and the NYU dataset for 3D hand pose estimation from depth maps. We show that it allows us to outperform the state-of-the-art on both datasets.
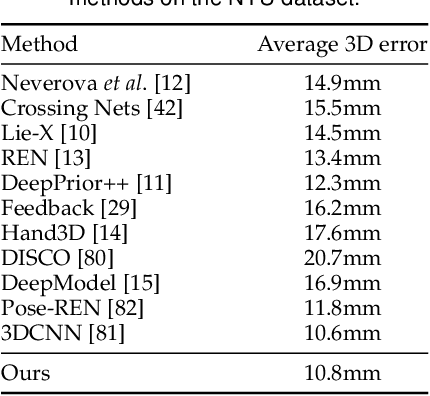
DeepPrior++: Improving Fast and Accurate 3D Hand Pose Estimation
Aug 28, 2017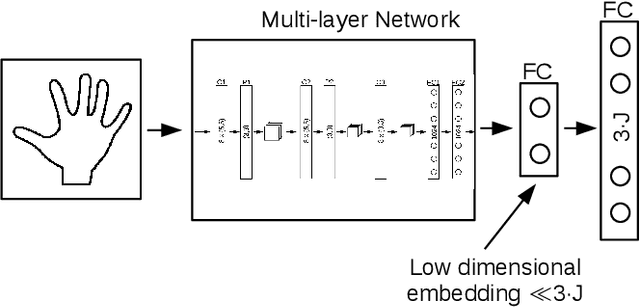
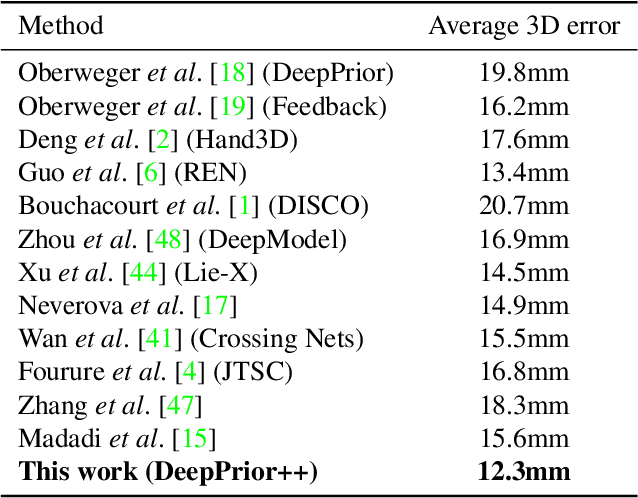
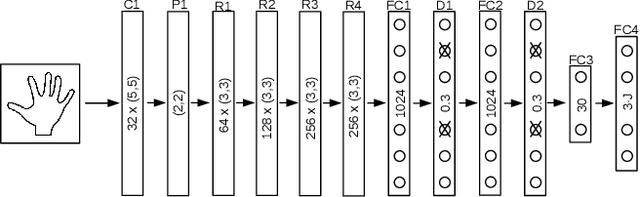
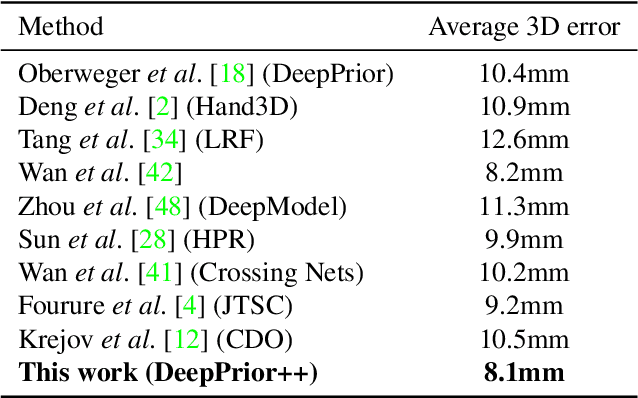
DeepPrior is a simple approach based on Deep Learning that predicts the joint 3D locations of a hand given a depth map. Since its publication early 2015, it has been outperformed by several impressive works. Here we show that with simple improvements: adding ResNet layers, data augmentation, and better initial hand localization, we achieve better or similar performance than more sophisticated recent methods on the three main benchmarks (NYU, ICVL, MSRA) while keeping the simplicity of the original method. Our new implementation is available at https://github.com/moberweger/deep-prior-pp .
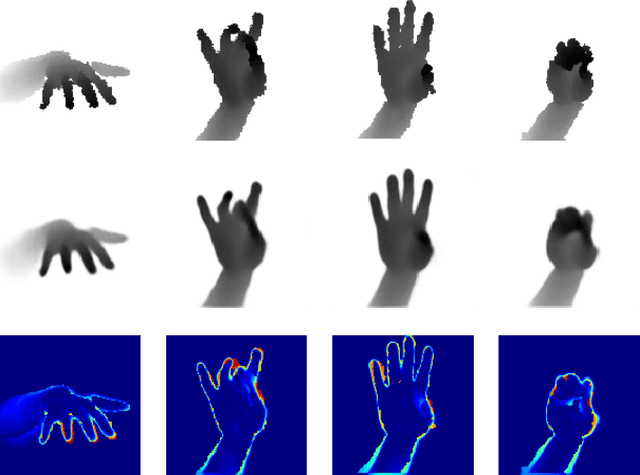
Efficiently Creating 3D Training Data for Fine Hand Pose Estimation
Dec 02, 2016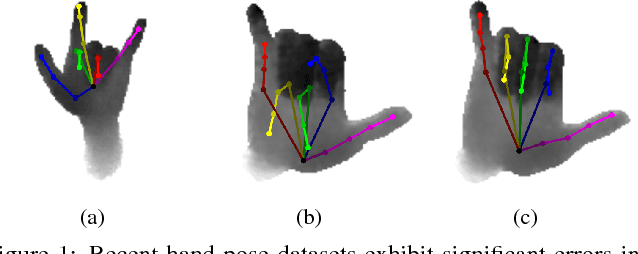
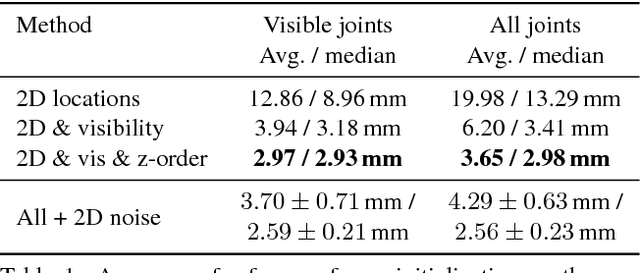
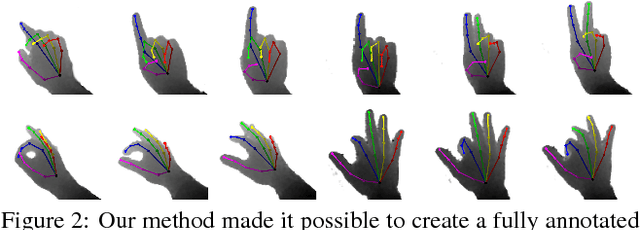
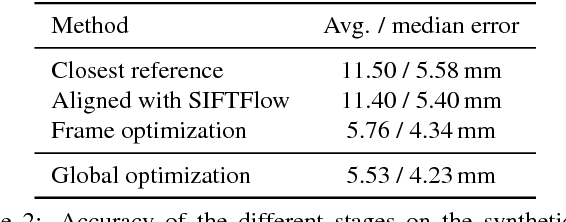
While many recent hand pose estimation methods critically rely on a training set of labelled frames, the creation of such a dataset is a challenging task that has been overlooked so far. As a result, existing datasets are limited to a few sequences and individuals, with limited accuracy, and this prevents these methods from delivering their full potential. We propose a semi-automated method for efficiently and accurately labeling each frame of a hand depth video with the corresponding 3D locations of the joints: The user is asked to provide only an estimate of the 2D reprojections of the visible joints in some reference frames, which are automatically selected to minimize the labeling work by efficiently optimizing a sub-modular loss function. We then exploit spatial, temporal, and appearance constraints to retrieve the full 3D poses of the hand over the complete sequence. We show that this data can be used to train a recent state-of-the-art hand pose estimation method, leading to increased accuracy. The code and dataset can be found on our website https://cvarlab.icg.tugraz.at/projects/hand_detection/
Hands Deep in Deep Learning for Hand Pose Estimation
Dec 02, 2016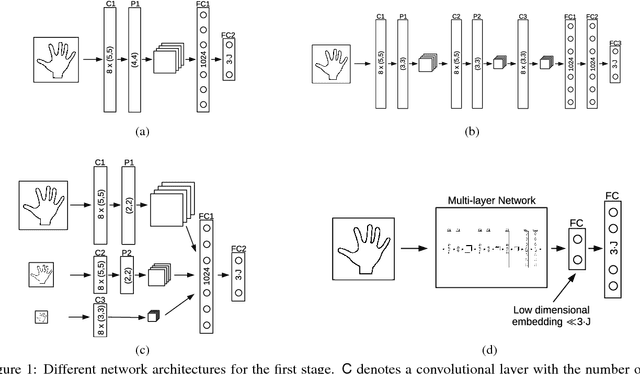

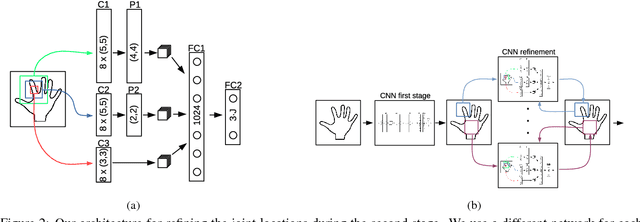
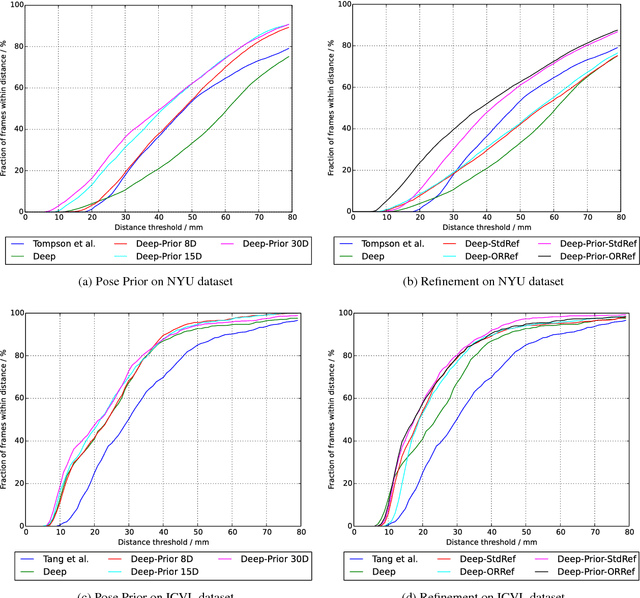
We introduce and evaluate several architectures for Convolutional Neural Networks to predict the 3D joint locations of a hand given a depth map. We first show that a prior on the 3D pose can be easily introduced and significantly improves the accuracy and reliability of the predictions. We also show how to use context efficiently to deal with ambiguities between fingers. These two contributions allow us to significantly outperform the state-of-the-art on several challenging benchmarks, both in terms of accuracy and computation times.
* added link to source https://github.com/moberweger/deep-prior
Training a Feedback Loop for Hand Pose Estimation
Sep 30, 2016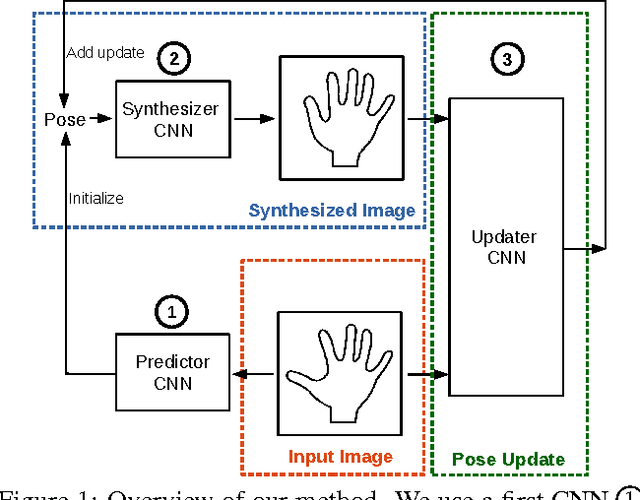
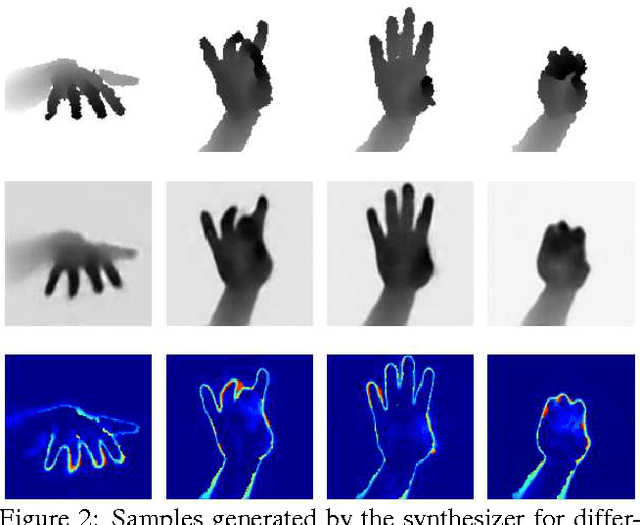
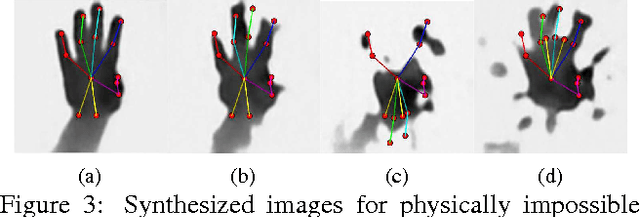
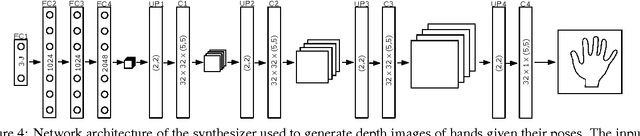
We propose an entirely data-driven approach to estimating the 3D pose of a hand given a depth image. We show that we can correct the mistakes made by a Convolutional Neural Network trained to predict an estimate of the 3D pose by using a feedback loop. The components of this feedback loop are also Deep Networks, optimized using training data. They remove the need for fitting a 3D model to the input data, which requires both a carefully designed fitting function and algorithm. We show that our approach outperforms state-of-the-art methods, and is efficient as our implementation runs at over 400 fps on a single GPU.