 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$α$Surf: Implicit Surface Reconstruction for Semi-Transparent and Thin Objects with Decoupled Geometry and Opacity
Mar 17, 2023Implicit surface representations such as the signed distance function (SDF) have emerged as a promising approach for image-based surface reconstruction. However, existing optimization methods assume solid surfaces and are therefore unable to properly reconstruct semi-transparent surfaces and thin structures, which also exhibit low opacity due to the blending effect with the background. While neural radiance field (NeRF) based methods can model semi-transparency and achieve photo-realistic quality in synthesized novel views, their volumetric geometry representation tightly couples geometry and opacity, and therefore cannot be easily converted into surfaces without introducing artifacts. We present $\alpha$Surf, a novel surface representation with decoupled geometry and opacity for the reconstruction of semi-transparent and thin surfaces where the colors mix. Ray-surface intersections on our representation can be found in closed-form via analytical solutions of cubic polynomials, avoiding Monte-Carlo sampling and is fully differentiable by construction. Our qualitative and quantitative evaluations show that our approach can accurately reconstruct surfaces with semi-transparent and thin parts with fewer artifacts, achieving better reconstruction quality than state-of-the-art SDF and NeRF methods. Website: https://alphasurf.netlify.app/
Stable View Synthesis
Nov 14, 2020

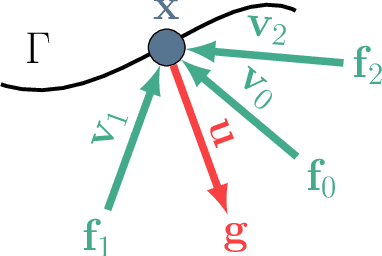
We present Stable View Synthesis (SVS). Given a set of source images depicting a scene from freely distributed viewpoints, SVS synthesizes new views of the scene. The method operates on a geometric scaffold computed via structure-from-motion and multi-view stereo. Each point on this 3D scaffold is associated with view rays and corresponding feature vectors that encode the appearance of this point in the input images. The core of SVS is view-dependent on-surface feature aggregation, in which directional feature vectors at each 3D point are processed to produce a new feature vector for a ray that maps this point into the new target view. The target view is then rendered by a convolutional network from a tensor of features synthesized in this way for all pixels. The method is composed of differentiable modules and is trained end-to-end. It supports spatially-varying view-dependent importance weighting and feature transformation of source images at each point; spatial and temporal stability due to the smooth dependence of on-surface feature aggregation on the target view; and synthesis of view-dependent effects such as specular reflection. Experimental results demonstrate that SVS outperforms state-of-the-art view synthesis methods both quantitatively and qualitatively on three diverse real-world datasets, achieving unprecedented levels of realism in free-viewpoint video of challenging large-scale scenes.
NeRF++: Analyzing and Improving Neural Radiance Fields
Oct 21, 2020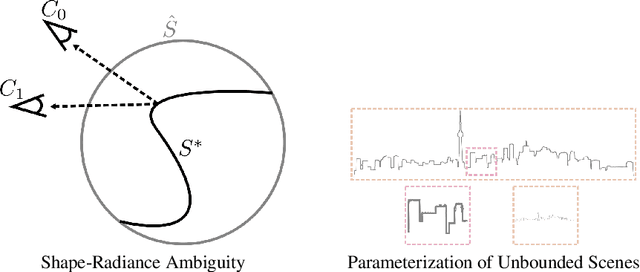


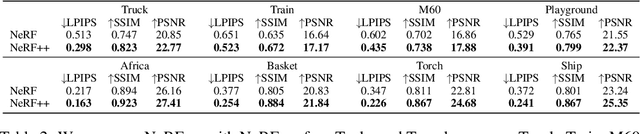
Neural Radiance Fields (NeRF) achieve impressive view synthesis results for a variety of capture settings, including 360 capture of bounded scenes and forward-facing capture of bounded and unbounded scenes. NeRF fits multi-layer perceptrons (MLPs) representing view-invariant opacity and view-dependent color volumes to a set of training images, and samples novel views based on volume rendering techniques. In this technical report, we first remark on radiance fields and their potential ambiguities, namely the shape-radiance ambiguity, and analyze NeRF's success in avoiding such ambiguities. Second, we address a parametrization issue involved in applying NeRF to 360 captures of objects within large-scale, unbounded 3D scenes. Our method improves view synthesis fidelity in this challenging scenario. Code is available at https://github.com/Kai-46/nerfplusplus.
Free View Synthesis
Aug 12, 2020
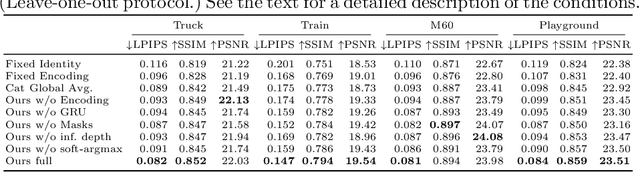


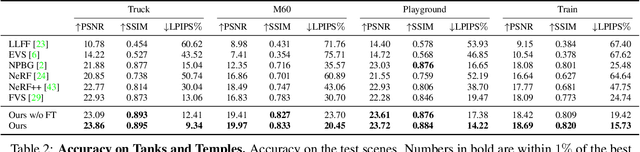
We present a method for novel view synthesis from input images that are freely distributed around a scene. Our method does not rely on a regular arrangement of input views, can synthesize images for free camera movement through the scene, and works for general scenes with unconstrained geometric layouts. We calibrate the input images via SfM and erect a coarse geometric scaffold via MVS. This scaffold is used to create a proxy depth map for a novel view of the scene. Based on this depth map, a recurrent encoder-decoder network processes reprojected features from nearby views and synthesizes the new view. Our network does not need to be optimized for a given scene. After training on a dataset, it works in previously unseen environments with no fine-tuning or per-scene optimization. We evaluate the presented approach on challenging real-world datasets, including Tanks and Temples, where we demonstrate successful view synthesis for the first time and substantially outperform prior and concurrent work.
OctNetFusion: Learning Depth Fusion from Data
Oct 31, 2017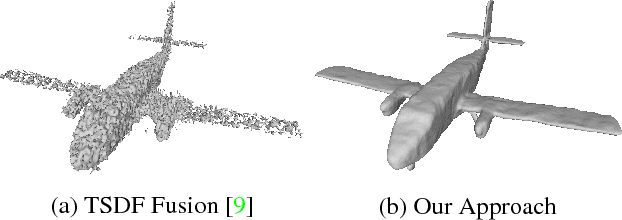
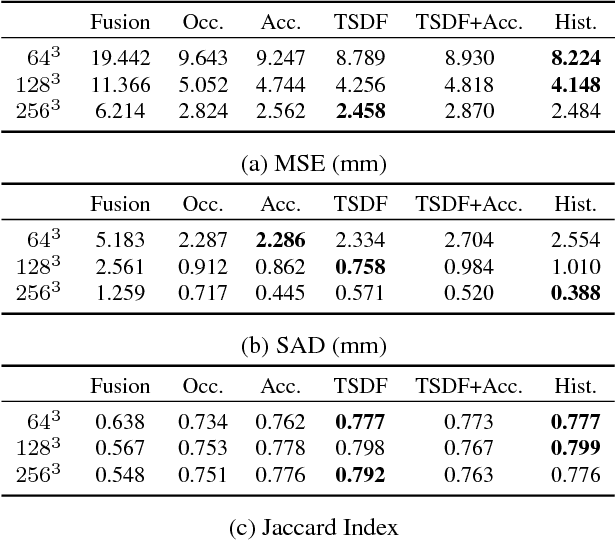
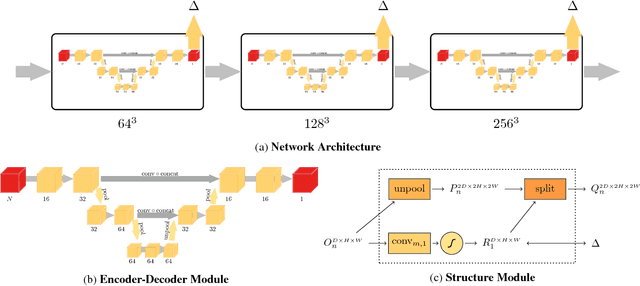

In this paper, we present a learning based approach to depth fusion, i.e., dense 3D reconstruction from multiple depth images. The most common approach to depth fusion is based on averaging truncated signed distance functions, which was originally proposed by Curless and Levoy in 1996. While this method is simple and provides great results, it is not able to reconstruct (partially) occluded surfaces and requires a large number frames to filter out sensor noise and outliers. Motivated by the availability of large 3D model repositories and recent advances in deep learning, we present a novel 3D CNN architecture that learns to predict an implicit surface representation from the input depth maps. Our learning based method significantly outperforms the traditional volumetric fusion approach in terms of noise reduction and outlier suppression. By learning the structure of real world 3D objects and scenes, our approach is further able to reconstruct occluded regions and to fill in gaps in the reconstruction. We demonstrate that our learning based approach outperforms both vanilla TSDF fusion as well as TV-L1 fusion on the task of volumetric fusion. Further, we demonstrate state-of-the-art 3D shape completion results.
OctNet: Learning Deep 3D Representations at High Resolutions
Apr 10, 2017



We present OctNet, a representation for deep learning with sparse 3D data. In contrast to existing models, our representation enables 3D convolutional networks which are both deep and high resolution. Towards this goal, we exploit the sparsity in the input data to hierarchically partition the space using a set of unbalanced octrees where each leaf node stores a pooled feature representation. This allows to focus memory allocation and computation to the relevant dense regions and enables deeper networks without compromising resolution. We demonstrate the utility of our OctNet representation by analyzing the impact of resolution on several 3D tasks including 3D object classification, orientation estimation and point cloud labeling.
Efficiently Creating 3D Training Data for Fine Hand Pose Estimation
Dec 02, 2016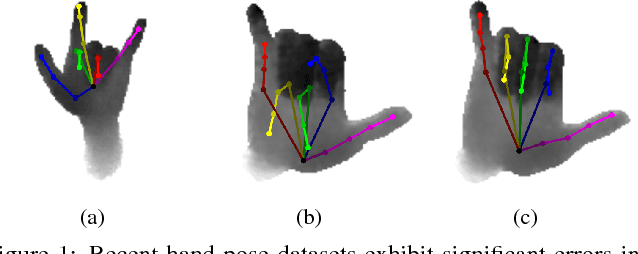
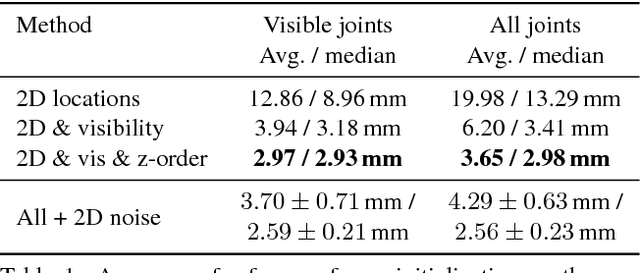
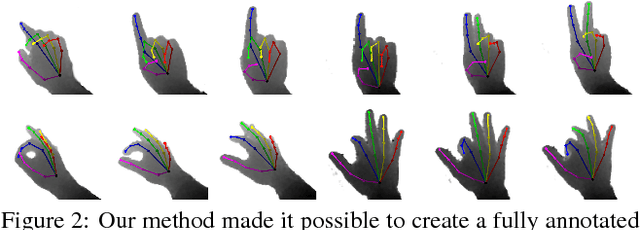
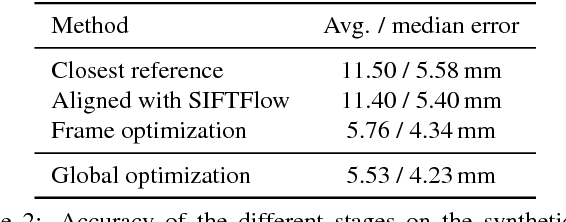
While many recent hand pose estimation methods critically rely on a training set of labelled frames, the creation of such a dataset is a challenging task that has been overlooked so far. As a result, existing datasets are limited to a few sequences and individuals, with limited accuracy, and this prevents these methods from delivering their full potential. We propose a semi-automated method for efficiently and accurately labeling each frame of a hand depth video with the corresponding 3D locations of the joints: The user is asked to provide only an estimate of the 2D reprojections of the visible joints in some reference frames, which are automatically selected to minimize the labeling work by efficiently optimizing a sub-modular loss function. We then exploit spatial, temporal, and appearance constraints to retrieve the full 3D poses of the hand over the complete sequence. We show that this data can be used to train a recent state-of-the-art hand pose estimation method, leading to increased accuracy. The code and dataset can be found on our website https://cvarlab.icg.tugraz.at/projects/hand_detection/
A Deep Primal-Dual Network for Guided Depth Super-Resolution
Jul 28, 2016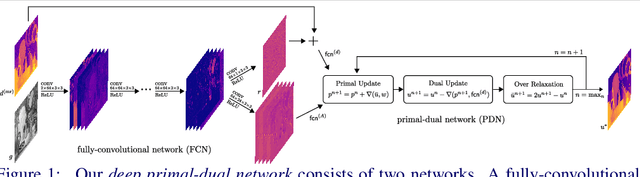
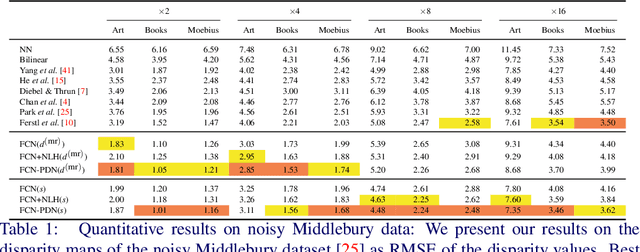
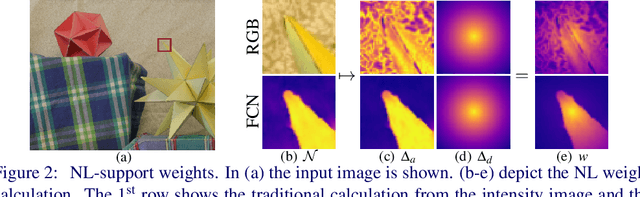

In this paper we present a novel method to increase the spatial resolution of depth images. We combine a deep fully convolutional network with a non-local variational method in a deep primal-dual network. The joint network computes a noise-free, high-resolution estimate from a noisy, low-resolution input depth map. Additionally, a high-resolution intensity image is used to guide the reconstruction in the network. By unrolling the optimization steps of a first-order primal-dual algorithm and formulating it as a network, we can train our joint method end-to-end. This not only enables us to learn the weights of the fully convolutional network, but also to optimize all parameters of the variational method and its optimization procedure. The training of such a deep network requires a large dataset for supervision. Therefore, we generate high-quality depth maps and corresponding color images with a physically based renderer. In an exhaustive evaluation we show that our method outperforms the state-of-the-art on multiple benchmarks.
ATGV-Net: Accurate Depth Super-Resolution
Jul 27, 2016



In this work we present a novel approach for single depth map super-resolution. Modern consumer depth sensors, especially Time-of-Flight sensors, produce dense depth measurements, but are affected by noise and have a low lateral resolution. We propose a method that combines the benefits of recent advances in machine learning based single image super-resolution, i.e. deep convolutional networks, with a variational method to recover accurate high-resolution depth maps. In particular, we integrate a variational method that models the piecewise affine structures apparent in depth data via an anisotropic total generalized variation regularization term on top of a deep network. We call our method ATGV-Net and train it end-to-end by unrolling the optimization procedure of the variational method. To train deep networks, a large corpus of training data with accurate ground-truth is required. We demonstrate that it is feasible to train our method solely on synthetic data that we generate in large quantities for this task. Our evaluations show that we achieve state-of-the-art results on three different benchmarks, as well as on a challenging Time-of-Flight dataset, all without utilizing an additional intensity image as guidance.
Filament and Flare Detection in Hα image sequences
Apr 26, 2013



Solar storms can have a major impact on the infrastructure of the earth. Some of the causing events are observable from ground in the H{\alpha} spectral line. In this paper we propose a new method for the simultaneous detection of flares and filaments in H{\alpha} image sequences. Therefore we perform several preprocessing steps to enhance and normalize the images. Based on the intensity values we segment the image by a variational approach. In a final postprecessing step we derive essential properties to classify the events and further demonstrate the performance by comparing our obtained results to the data annotated by an expert. The information produced by our method can be used for near real-time alerts and the statistical analysis of existing data by solar physicists.