 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALM: A Dataset and Baseline for Learning Multi-subject Hand Prior
Nov 07, 2025

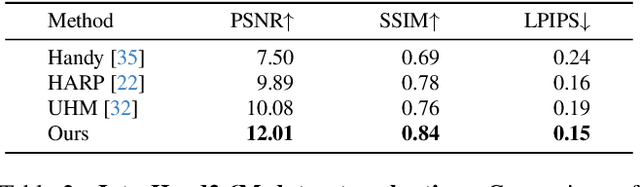
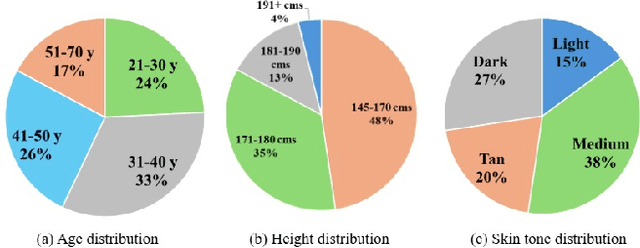
The ability to grasp objects, signal with gestures, and share emotion through touch all stem from the unique capabilities of human hands. Yet creating high-quality personalized hand avatars from images remains challenging due to complex geometry, appearance, and articulation, particularly under unconstrained lighting and limited views. Progress has also been limited by the lack of datasets that jointly provide accurate 3D geometry, high-resolution multiview imagery, and a diverse population of subjects. To address this, we present PALM, a large-scale dataset comprising 13k high-quality hand scans from 263 subjects and 90k multi-view images, capturing rich variation in skin tone, age, and geometry. To show its utility, we present a baseline PALM-Net, a multi-subject prior over hand geometry and material properties learned via physically based inverse rendering, enabling realistic, relightable single-image hand avatar personalization. PALM's scale and diversity make it a valuable real-world resource for hand modeling and related research.
FoundHand: Large-Scale Domain-Specific Learning for Controllable Hand Image Generation
Dec 03, 2024



Despite remarkable progress in image generation models, generating realistic hands remains a persistent challenge due to their complex articulation, varying viewpoints, and frequent occlusions. We present FoundHand, a large-scale domain-specific diffusion model for synthesizing single and dual hand images. To train our model, we introduce FoundHand-10M, a large-scale hand dataset with 2D keypoints and segmentation mask annotations. Our insight is to use 2D hand keypoints as a universal representation that encodes both hand articulation and camera viewpoint. FoundHand learns from image pairs to capture physically plausible hand articulations, natively enables precise control through 2D keypoints, and supports appearance control. Our model exhibits core capabilities that include the ability to repose hands, transfer hand appearance, and even synthesize novel views. This leads to zero-shot capabilities for fixing malformed hands in previously generated images, or synthesizing hand video sequences. We present extensive experiments and evaluations that demonstrate state-of-the-art performance of our method.
HOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos
Nov 28, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground-truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. In our experiments, we demonstrate the effectiveness of multi-view egocentric data for three popular tasks: 3D hand tracking, 6DoF object pose estimation, and 3D lifting of unknown in-hand objects. The evaluated multi-view methods, whose benchmarking is uniquely enabled by HOT3D, significantly outperform their single-view counterparts.
Introducing HOT3D: An Egocentric Dataset for 3D Hand and Object Tracking
Jun 13, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. We aim to accelerate research on egocentric hand-object interaction by making the HOT3D dataset publicly available and by co-organizing public challenges on the dataset at ECCV 2024. The dataset can be downloaded from the project website: https://facebookresearch.github.io/hot3d/.
EgoPoseFormer: A Simple Baseline for Egocentric 3D Human Pose Estimation
Mar 26, 2024



We present EgoPoseFormer, a simple yet effective transformer-based model for stereo egocentric human pose estimation. The main challenge in egocentric pose estimation is overcoming joint invisibility, which is caused by self-occlusion or a limited field of view (FOV) of head-mounted cameras. Our approach overcomes this challenge by incorporating a two-stage pose estimation paradigm: in the first stage, our model leverages the global information to estimate each joint's coarse location, then in the second stage, it employs a DETR style transformer to refine the coarse locations by exploiting fine-grained stereo visual features. In addition, we present a deformable stereo operation to enable our transformer to effectively process multi-view features, which enables it to accurately localize each joint in the 3D world. We evaluate our method on the stereo UnrealEgo dataset and show it significantly outperforms previous approaches while being computationally efficient: it improves MPJPE by 27.4mm (45% improvement) with only 7.9% model parameters and 13.1% FLOPs compared to the state-of-the-art. Surprisingly, with proper training techniques, we find that even our first-stage pose proposal network can achieve superior performance compared to previous arts. We also show that our method can be seamlessly extended to monocular settings, which achieves state-of-the-art performance on the SceneEgo dataset, improving MPJPE by 25.5mm (21% improvement) compared to the best existing method with only 60.7% model parameters and 36.4% FLOPs.
DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions
Mar 26, 2024



Generating natural hand-object interactions in 3D is challenging as the resulting hand and object motions are expected to be physically plausible and semantically meaningful. Furthermore, generalization to unseen objects is hindered by the limited scale of available hand-object interaction datasets. We propose DiffH2O, a novel method to synthesize realistic, one or two-handed object interactions from provided text prompts and geometry of the object. The method introduces three techniques that enable effective learning from limited data. First, we decompose the task into a grasping stage and a text-based interaction stage and use separate diffusion models for each. In the grasping stage, the model only generates hand motions, whereas in the interaction phase both hand and object poses are synthesized. Second, we propose a compact representation that tightly couples hand and object poses. Third, we propose two different guidance schemes to allow more control of the generated motions: grasp guidance and detailed textual guidance. Grasp guidance takes a single target grasping pose and guides the diffusion model to reach this grasp at the end of the grasping stage, which provides control over the grasping pose. Given a grasping motion from this stage, multiple different actions can be prompted in the interaction phase. For textual guidance, we contribute comprehensive text descriptions to the GRAB dataset and show that they enable our method to have more fine-grained control over hand-object interactions. Our quantitative and qualitative evaluation demonstrates that the proposed method outperforms baseline methods and leads to natural hand-object motions. Moreover, we demonstrate the practicality of our framework by utilizing a hand pose estimate from an off-the-shelf pose estimator for guidance, and then sampling multiple different actions in the interaction stage.
In-Hand 3D Object Scanning from an RGB Sequence
Nov 28, 2022
We propose a method for in-hand 3D scanning of an unknown object from a sequence of color images. We cast the problem as reconstructing the object surface from un-posed multi-view images and rely on a neural implicit surface representation that captures both the geometry and the appearance of the object. By contrast with most NeRF-based methods, we do not assume that the camera-object relative poses are known and instead simultaneously optimize both the object shape and the pose trajectory. As global optimization over all the shape and pose parameters is prone to fail without coarse-level initialization of the poses, we propose an incremental approach which starts by splitting the sequence into carefully selected overlapping segments within which the optimization is likely to succeed. We incrementally reconstruct the object shape and track the object poses independently within each segment, and later merge all the segments by aligning poses estimated at the overlapping frames. Finally, we perform a global optimization over all the aligned segments to achieve full reconstruction. We experimentally show that the proposed method is able to reconstruct the shape and color of both textured and challenging texture-less objects, outperforms classical methods that rely only on appearance features, and its performance is close to recent methods that assume known camera poses.
HO-3D_v3: Improving the Accuracy of Hand-Object Annotations of the HO-3D Dataset
Jul 02, 2021
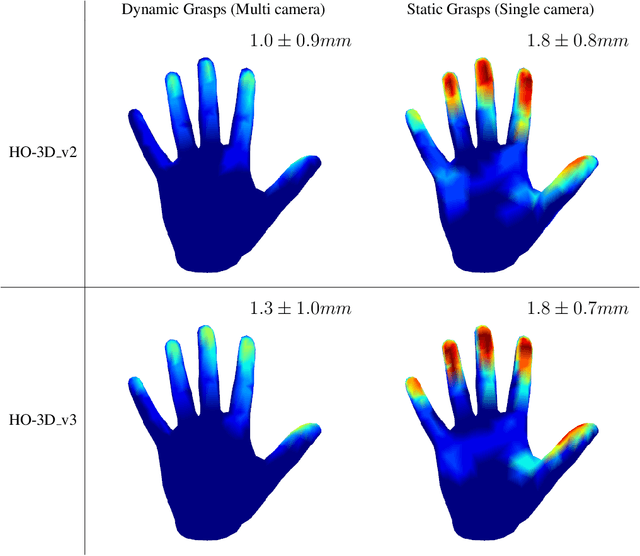
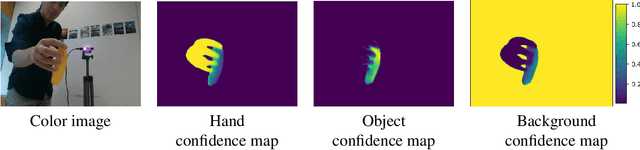
HO-3D is a dataset providing image sequences of various hand-object interaction scenarios annotated with the 3D pose of the hand and the object and was originally introduced as HO-3D_v2. The annotations were obtained automatically using an optimization method, 'HOnnotate', introduced in the original paper. HO-3D_v3 provides more accurate annotations for both the hand and object poses thus resulting in better estimates of contact regions between the hand and the object. In this report, we elaborate on the improvements to the HOnnotate method and provide evaluations to compare the accuracy of HO-3D_v2 and HO-3D_v3. HO-3D_v3 results in 4mm higher accuracy compared to HO-3D_v2 for hand poses while exhibiting higher contact regions with the object surface.
HandsFormer: Keypoint Transformer for Monocular 3D Pose Estimation ofHands and Object in Interaction
Apr 29, 2021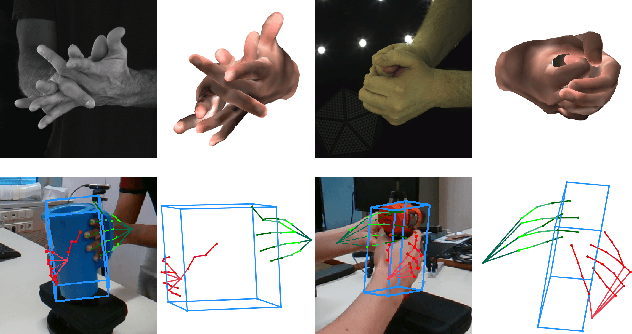
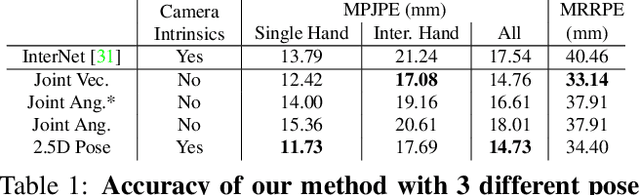
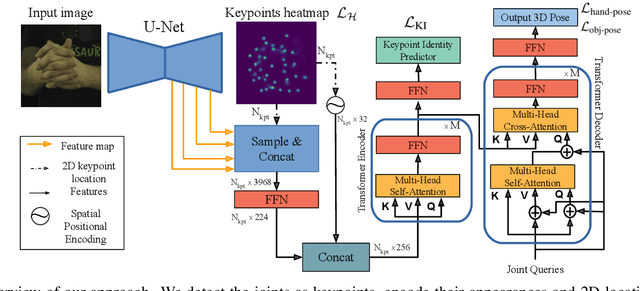

We propose a robust and accurate method for estimating the 3D poses of two hands in close interaction from a single color image. This is a very challenging problem, as large occlusions and many confusions between the joints may happen. Our method starts by extracting a set of potential 2D locations for the joints of both hands as extrema of a heatmap. We do not require that all locations correctly correspond to a joint, not that all the joints are detected. We use appearance and spatial encodings of these locations as input to a transformer, and leverage the attention mechanisms to sort out the correct configuration of the joints and output the 3D poses of both hands. Our approach thus allies the recognition power of a Transformer to the accuracy of heatmap-based methods. We also show it can be extended to estimate the 3D pose of an object manipulated by one or two hands. We evaluate our approach on the recent and challenging InterHand2.6M and HO-3D datasets. We obtain 17% improvement over the baseline. Moreover, we introduce the first dataset made of action sequences of two hands manipulating an object fully annotated in 3D and will make it publicly available.
Monte Carlo Scene Search for 3D Scene Understanding
Mar 30, 2021

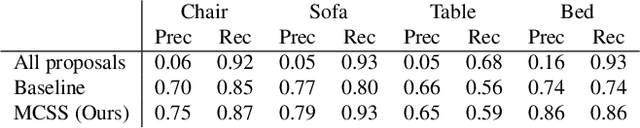
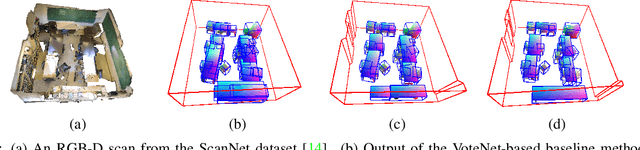
We explore how a general AI algorithm can be used for 3D scene understanding to reduce the need for training data. More exactly, we propose a modification of the Monte Carlo Tree Search (MCTS) algorithm to retrieve objects and room layouts from noisy RGB-D scans. While MCTS was developed as a game-playing algorithm, we show it can also be used for complex perception problems. Our adapted MCTS algorithm has few easy-to-tune hyperparameters and can optimise general losses. We use it to optimise the posterior probability of objects and room layout hypotheses given the RGB-D data. This results in an analysis-by-synthesis approach that explores the solution space by rendering the current solution and comparing it to the RGB-D observations. To perform this exploration even more efficiently, we propose simple changes to the standard MCTS' tree construction and exploration policy. We demonstrate our approach on the ScanNet dataset. Our method often retrieves configurations that are better than some manual annotations, especially on layouts.