 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos
Nov 28, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground-truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. In our experiments, we demonstrate the effectiveness of multi-view egocentric data for three popular tasks: 3D hand tracking, 6DoF object pose estimation, and 3D lifting of unknown in-hand objects. The evaluated multi-view methods, whose benchmarking is uniquely enabled by HOT3D, significantly outperform their single-view counterparts.
Introducing HOT3D: An Egocentric Dataset for 3D Hand and Object Tracking
Jun 13, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. We aim to accelerate research on egocentric hand-object interaction by making the HOT3D dataset publicly available and by co-organizing public challenges on the dataset at ECCV 2024. The dataset can be downloaded from the project website: https://facebookresearch.github.io/hot3d/.
Identity Preserving Loss for Learned Image Compression
Apr 27, 2022

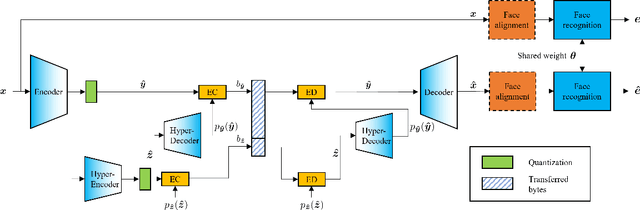

Deep learning model inference on embedded devices is challenging due to the limited availability of computation resources. A popular alternative is to perform model inference on the cloud, which requires transmitting images from the embedded device to the cloud. Image compression techniques are commonly employed in such cloud-based architectures to reduce transmission latency over low bandwidth networks. This work proposes an end-to-end image compression framework that learns domain-specific features to achieve higher compression ratios than standard HEVC/JPEG compression techniques while maintaining accuracy on downstream tasks (e.g., recognition). Our framework does not require fine-tuning of the downstream task, which allows us to drop-in any off-the-shelf downstream task model without retraining. We choose faces as an application domain due to the ready availability of datasets and off-the-shelf recognition models as representative downstream tasks. We present a novel Identity Preserving Reconstruction (IPR) loss function which achieves Bits-Per-Pixel (BPP) values that are ~38% and ~42% of CRF-23 HEVC compression for LFW (low-resolution) and CelebA-HQ (high-resolution) datasets, respectively, while maintaining parity in recognition accuracy. The superior compression ratio is achieved as the model learns to retain the domain-specific features (e.g., facial features) while sacrificing details in the background. Furthermore, images reconstructed by our proposed compression model are robust to changes in downstream model architectures. We show at-par recognition performance on the LFW dataset with an unseen recognition model while retaining a lower BPP value of ~38% of CRF-23 HEVC compression.