 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Videos to Conversations: Egocentric Instructions for Task Assistance
Feb 01, 2026Many everyday tasks, ranging from appliance repair and cooking to car maintenance, require expert knowledge, particularly for complex, multi-step procedures. Despite growing interest in AI agents for augmented reality (AR) assistance, progress remains limited by the scarcity of large-scale multimodal conversational datasets grounded in real-world task execution, in part due to the cost and logistical complexity of human-assisted data collection. In this paper, we present a framework to automatically transform single person instructional videos into two-person multimodal task-guidance conversations. Our fully automatic pipeline, based on large language models, provides a scalable and cost efficient alternative to traditional data collection approaches. Using this framework, we introduce HowToDIV, a multimodal dataset comprising 507 conversations, 6,636 question answer pairs, and 24 hours of video spanning multiple domains. Each session consists of a multi-turn expert-novice interaction. Finally, we report baseline results using Gemma 3 and Qwen 2.5 on HowToDIV, providing an initial benchmark for multimodal procedural task assistance.
YETI (YET to Intervene) Proactive Interventions by Multimodal AI Agents in Augmented Reality Tasks
Jan 16, 2025



Multimodal AI Agents are AI models that have the capability of interactively and cooperatively assisting human users to solve day-to-day tasks. Augmented Reality (AR) head worn devices can uniquely improve the user experience of solving procedural day-to-day tasks by providing egocentric multimodal (audio and video) observational capabilities to AI Agents. Such AR capabilities can help AI Agents see and listen to actions that users take which can relate to multimodal capabilities of human users. Existing AI Agents, either Large Language Models (LLMs) or Multimodal Vision-Language Models (VLMs) are reactive in nature, which means that models cannot take an action without reading or listening to the human user's prompts. Proactivity of AI Agents on the other hand can help the human user detect and correct any mistakes in agent observed tasks, encourage users when they do tasks correctly or simply engage in conversation with the user - akin to a human teaching or assisting a user. Our proposed YET to Intervene (YETI) multimodal agent focuses on the research question of identifying circumstances that may require the agent to intervene proactively. This allows the agent to understand when it can intervene in a conversation with human users that can help the user correct mistakes on tasks, like cooking, using AR. Our YETI Agent learns scene understanding signals based on interpretable notions of Structural Similarity (SSIM) on consecutive video frames. We also define the alignment signal which the AI Agent can learn to identify if the video frames corresponding to the user's actions on the task are consistent with expected actions. These signals are used by our AI Agent to determine when it should proactively intervene. We compare our results on the instances of proactive intervention in the HoloAssist multimodal benchmark for an expert agent guiding a user to complete procedural tasks.
Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
Aug 23, 2023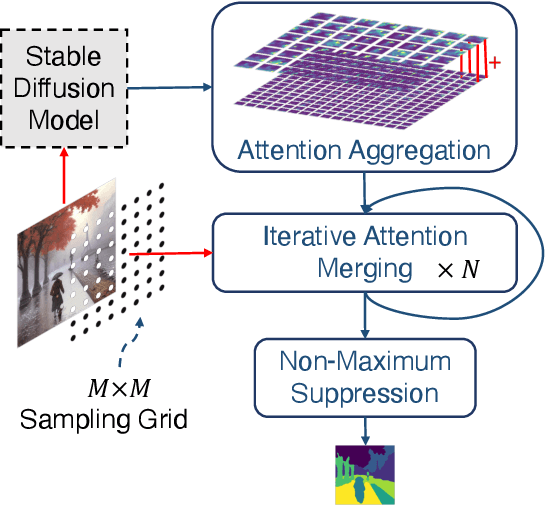
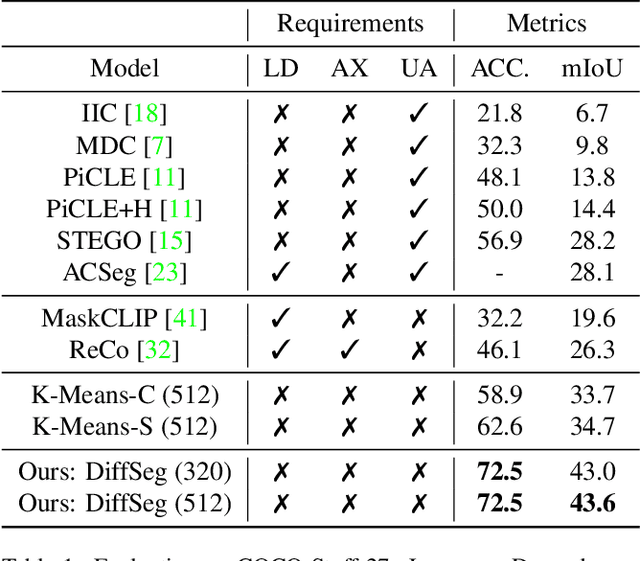
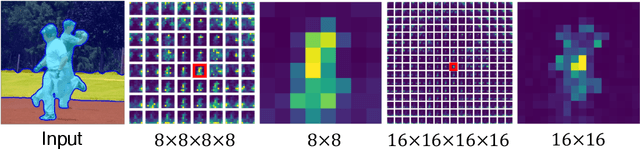
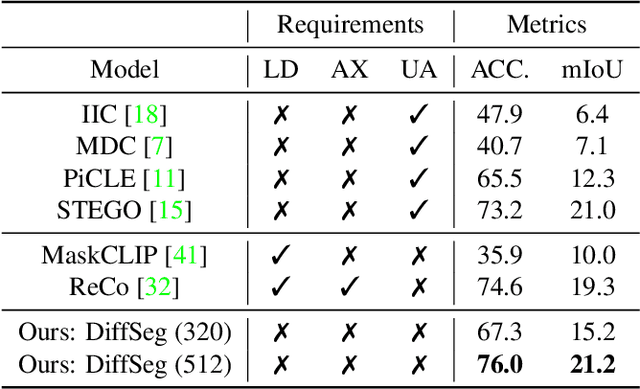
Producing quality segmentation masks for images is a fundamental problem in computer vision. Recent research has explored large-scale supervised training to enable zero-shot segmentation on virtually any image style and unsupervised training to enable segmentation without dense annotations. However, constructing a model capable of segmenting anything in a zero-shot manner without any annotations is still challenging. In this paper, we propose to utilize the self-attention layers in stable diffusion models to achieve this goal because the pre-trained stable diffusion model has learned inherent concepts of objects within its attention layers. Specifically, we introduce a simple yet effective iterative merging process based on measuring KL divergence among attention maps to merge them into valid segmentation masks. The proposed method does not require any training or language dependency to extract quality segmentation for any images. On COCO-Stuff-27, our method surpasses the prior unsupervised zero-shot SOTA method by an absolute 26% in pixel accuracy and 17% in mean IoU.
Fairness in AI Systems: Mitigating gender bias from language-vision models
May 03, 2023

Our society is plagued by several biases, including racial biases, caste biases, and gender bias. As a matter of fact, several years ago, most of these notions were unheard of. These biases passed through generations along with amplification have lead to scenarios where these have taken the role of expected norms by certain groups in the society. One notable example is of gender bias. Whether we talk about the political world, lifestyle or corporate world, some generic differences are observed regarding the involvement of both the groups. This differential distribution, being a part of the society at large, exhibits its presence in the recorded data as well. Machine learning is almost entirely dependent on the availability of data; and the idea of learning from data and making predictions assumes that data defines the expected behavior at large. Hence, with biased data the resulting models are corrupted with those inherent biases too; and with the current popularity of ML in products, this can result in a huge obstacle in the path of equality and justice. This work studies and attempts to alleviate gender bias issues from language vision models particularly the task of image captioning. We study the extent of the impact of gender bias in existing datasets and propose a methodology to mitigate its impact in caption based language vision models.
Identity Preserving Loss for Learned Image Compression
Apr 27, 2022

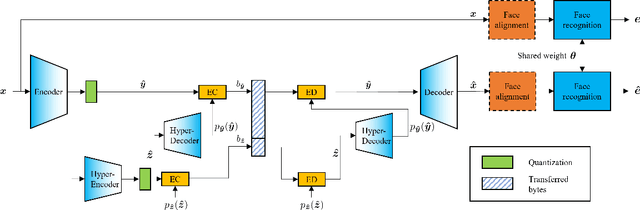

Deep learning model inference on embedded devices is challenging due to the limited availability of computation resources. A popular alternative is to perform model inference on the cloud, which requires transmitting images from the embedded device to the cloud. Image compression techniques are commonly employed in such cloud-based architectures to reduce transmission latency over low bandwidth networks. This work proposes an end-to-end image compression framework that learns domain-specific features to achieve higher compression ratios than standard HEVC/JPEG compression techniques while maintaining accuracy on downstream tasks (e.g., recognition). Our framework does not require fine-tuning of the downstream task, which allows us to drop-in any off-the-shelf downstream task model without retraining. We choose faces as an application domain due to the ready availability of datasets and off-the-shelf recognition models as representative downstream tasks. We present a novel Identity Preserving Reconstruction (IPR) loss function which achieves Bits-Per-Pixel (BPP) values that are ~38% and ~42% of CRF-23 HEVC compression for LFW (low-resolution) and CelebA-HQ (high-resolution) datasets, respectively, while maintaining parity in recognition accuracy. The superior compression ratio is achieved as the model learns to retain the domain-specific features (e.g., facial features) while sacrificing details in the background. Furthermore, images reconstructed by our proposed compression model are robust to changes in downstream model architectures. We show at-par recognition performance on the LFW dataset with an unseen recognition model while retaining a lower BPP value of ~38% of CRF-23 HEVC compression.