 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReality Proxy: Fluid Interactions with Real-World Objects in MR via Abstract Representations
Jul 24, 2025Interacting with real-world objects in Mixed Reality (MR) often proves difficult when they are crowded, distant, or partially occluded, hindering straightforward selection and manipulation. We observe that these difficulties stem from performing interaction directly on physical objects, where input is tightly coupled to their physical constraints. Our key insight is to decouple interaction from these constraints by introducing proxies-abstract representations of real-world objects. We embody this concept in Reality Proxy, a system that seamlessly shifts interaction targets from physical objects to their proxies during selection. Beyond facilitating basic selection, Reality Proxy uses AI to enrich proxies with semantic attributes and hierarchical spatial relationships of their corresponding physical objects, enabling novel and previously cumbersome interactions in MR - such as skimming, attribute-based filtering, navigating nested groups, and complex multi object selections - all without requiring new gestures or menu systems. We demonstrate Reality Proxy's versatility across diverse scenarios, including office information retrieval, large-scale spatial navigation, and multi-drone control. An expert evaluation suggests the system's utility and usability, suggesting that proxy-based abstractions offer a powerful and generalizable interaction paradigm for future MR systems.
Everyday AR through AI-in-the-Loop
Dec 17, 2024
This workshop brings together experts and practitioners from augmented reality (AR) and artificial intelligence (AI) to shape the future of AI-in-the-loop everyday AR experiences. With recent advancements in both AR hardware and AI capabilities, we envision that everyday AR -- always-available and seamlessly integrated into users' daily environments -- is becoming increasingly feasible. This workshop will explore how AI can drive such everyday AR experiences. We discuss a range of topics, including adaptive and context-aware AR, generative AR content creation, always-on AI assistants, AI-driven accessible design, and real-world-oriented AI agents. Our goal is to identify the opportunities and challenges in AI-enabled AR, focusing on creating novel AR experiences that seamlessly blend the digital and physical worlds. Through the workshop, we aim to foster collaboration, inspire future research, and build a community to advance the research field of AI-enhanced AR.
Geometry Fidelity for Spherical Images
Jul 25, 2024



Spherical or omni-directional images offer an immersive visual format appealing to a wide range of computer vision applications. However, geometric properties of spherical images pose a major challenge for models and metrics designed for ordinary 2D images. Here, we show that direct application of Fr\'echet Inception Distance (FID) is insufficient for quantifying geometric fidelity in spherical images. We introduce two quantitative metrics accounting for geometric constraints, namely Omnidirectional FID (OmniFID) and Discontinuity Score (DS). OmniFID is an extension of FID tailored to additionally capture field-of-view requirements of the spherical format by leveraging cubemap projections. DS is a kernel-based seam alignment score of continuity across borders of 2D representations of spherical images. In experiments, OmniFID and DS quantify geometry fidelity issues that are undetected by FID.
Augmented Object Intelligence: Making the Analog World Interactable with XR-Objects
Apr 23, 2024



Seamless integration of physical objects as interactive digital entities remains a challenge for spatial computing. This paper introduces Augmented Object Intelligence (AOI), a novel XR interaction paradigm designed to blur the lines between digital and physical by equipping real-world objects with the ability to interact as if they were digital, where every object has the potential to serve as a portal to vast digital functionalities. Our approach utilizes object segmentation and classification, combined with the power of Multimodal Large Language Models (MLLMs), to facilitate these interactions. We implement the AOI concept in the form of XR-Objects, an open-source prototype system that provides a platform for users to engage with their physical environment in rich and contextually relevant ways. This system enables analog objects to not only convey information but also to initiate digital actions, such as querying for details or executing tasks. Our contributions are threefold: (1) we define the AOI concept and detail its advantages over traditional AI assistants, (2) detail the XR-Objects system's open-source design and implementation, and (3) show its versatility through a variety of use cases and a user study.
Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
Aug 23, 2023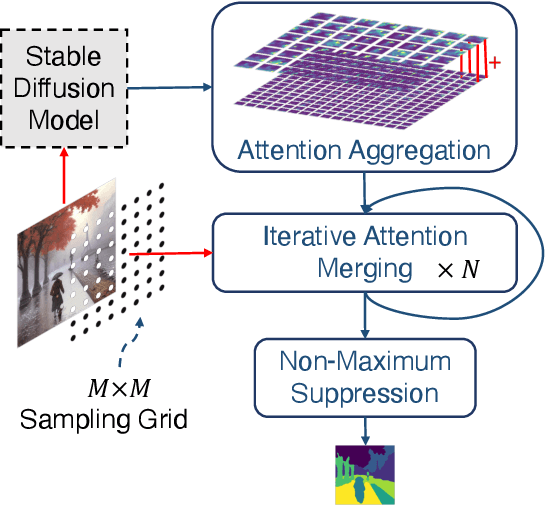
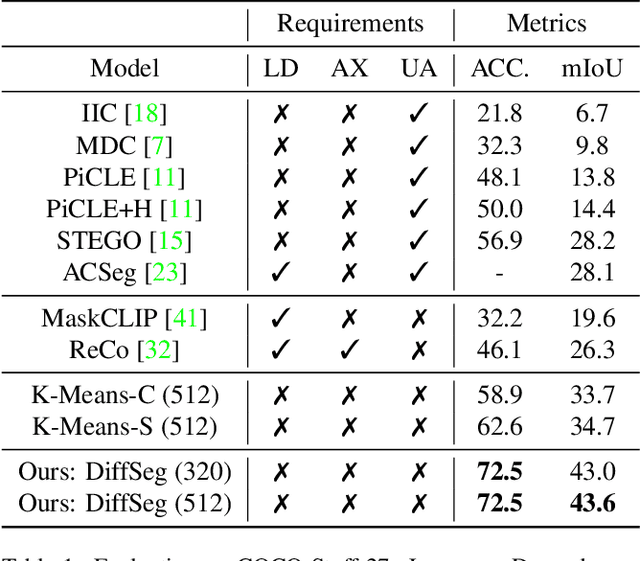
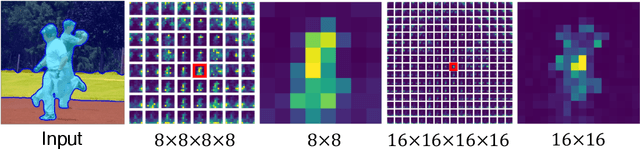
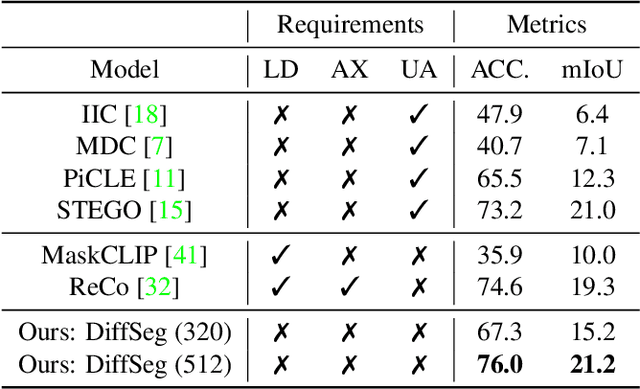
Producing quality segmentation masks for images is a fundamental problem in computer vision. Recent research has explored large-scale supervised training to enable zero-shot segmentation on virtually any image style and unsupervised training to enable segmentation without dense annotations. However, constructing a model capable of segmenting anything in a zero-shot manner without any annotations is still challenging. In this paper, we propose to utilize the self-attention layers in stable diffusion models to achieve this goal because the pre-trained stable diffusion model has learned inherent concepts of objects within its attention layers. Specifically, we introduce a simple yet effective iterative merging process based on measuring KL divergence among attention maps to merge them into valid segmentation masks. The proposed method does not require any training or language dependency to extract quality segmentation for any images. On COCO-Stuff-27, our method surpasses the prior unsupervised zero-shot SOTA method by an absolute 26% in pixel accuracy and 17% in mean IoU.
HapticBots: Distributed Encountered-type Haptics for VR with Multiple Shape-changing Mobile Robots
Aug 24, 2021

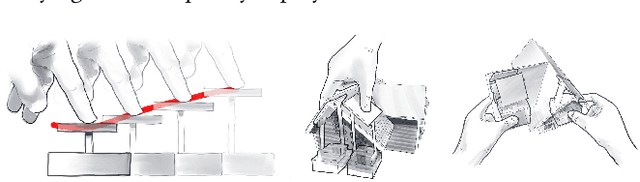
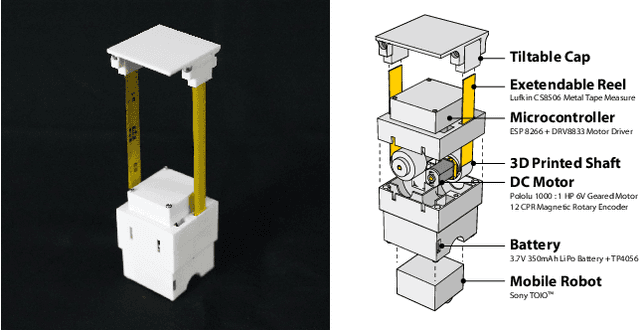
HapticBots introduces a novel encountered-type haptic approach for Virtual Reality (VR) based on multiple tabletop-size shape-changing robots. These robots move on a tabletop and change their height and orientation to haptically render various surfaces and objects on-demand. Compared to previous encountered-type haptic approaches like shape displays or robotic arms, our proposed approach has an advantage in deployability, scalability, and generalizability -- these robots can be easily deployed due to their compact form factor. They can support multiple concurrent touch points in a large area thanks to the distributed nature of the robots. We propose and evaluate a novel set of interactions enabled by these robots which include: 1) rendering haptics for VR objects by providing just-in-time touch-points on the user's hand, 2) simulating continuous surfaces with the concurrent height and position change, and 3) enabling the user to pick up and move VR objects through graspable proxy objects. Finally, we demonstrate HapticBots with various applications, including remote collaboration, education and training, design and 3D modeling, and gaming and entertainment.