 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOLDMARK: Governed Outcome-Linked Diagnostic Model Assessment Reference Kit
Mar 21, 2026Computational biomarkers (CBs) are histopathology-derived patterns extracted from hematoxylin-eosin (H&E) whole-slide images (WSIs) using artificial intelligence (AI) to predict therapeutic response or prognosis. Recently, slide-level multiple-instance learning (MIL) with pathology foundation models (PFMs) has become the standard baseline for CB development. While these methods have improved predictive performance, computational pathology lacks standardized intermediate data formats, provenance tracking, checkpointing conventions, and reproducible evaluation metrics required for clinical-grade deployment. We introduce GOLDMARK (https://artificialintelligencepathology.org), a standardized benchmarking framework built on a curated TCGA cohort with clinically actionable OncoKB level 1-3 biomarker labels. GOLDMARK releases structured intermediate representations, including tile coordinate maps, per-slide feature embeddings from canonical PFMs, quality-control metadata, predefined patient-level splits, trained slide-level models, and evaluation outputs. Models are trained on TCGA and evaluated on an independent MSKCC cohort with reciprocal testing. Across 33 tumor-biomarker tasks, mean AUROC was 0.689 (TCGA) and 0.630 (MSKCC). Restricting to the eight highest-performing tasks yielded mean AUROCs of 0.831 and 0.801, respectively. These tasks correspond to established morphologic-genomic associations (e.g., LGG IDH1, COAD MSI/BRAF, THCA BRAF/NRAS, BLCA FGFR3, UCEC PTEN) and showed the most stable cross-site performance. Differences between canonical encoders were modest relative to task-specific variability. GOLDMARK establishes a shared experimental substrate for computational pathology, enabling reproducible benchmarking and direct comparison of methods across datasets and models.
PhysGraph: Physically-Grounded Graph-Transformer Policies for Bimanual Dexterous Hand-Tool-Object Manipulation
Mar 02, 2026Bimanual dexterous manipulation for tool use remains a formidable challenge in robotics due to the high-dimensional state space and complicated contact dynamics. Existing methods naively represent the entire system state as a single configuration vector, disregarding the rich structural and topological information inherent to articulated hands. We present PhysGraph, a physically-grounded graph transformer policy designed explicitly for challenging bimanual hand-tool-object manipulation. Unlike prior works, we represent the bimanual system as a kinematic graph and introduce per-link tokenization to preserve fine-grained local state information. We propose a physically-grounded bias generator that injects structural priors directly into the attention mechanism, including kinematic spatial distance, dynamic contact states, geometric proximity, and anatomical properties. This allows the policy to explicitly reason about physical interactions rather than learning them implicitly from sparse rewards. Extensive experiments show that PhysGraph significantly outperforms baseline - ManipTrans in manipulation precision and task success rates while using only 51% of the parameters of ManipTrans. Furthermore, the inherent topological flexibility of our architecture shows qualitative zero-shot transfer to unseen tool/object geometries, and is sufficiently general to be trained on three robotic hands (Shadow, Allegro, Inspire).
Single GPU Task Adaptation of Pathology Foundation Models for Whole Slide Image Analysis
Jun 05, 2025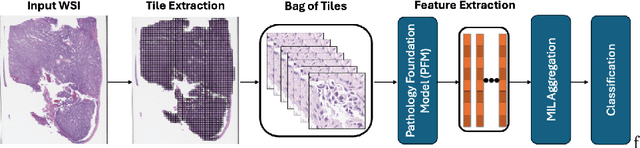
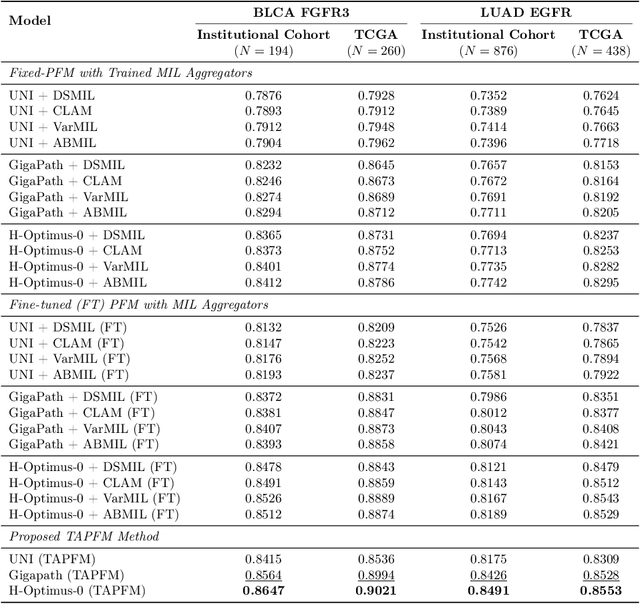
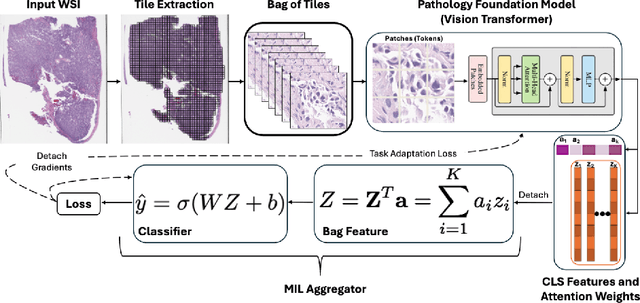
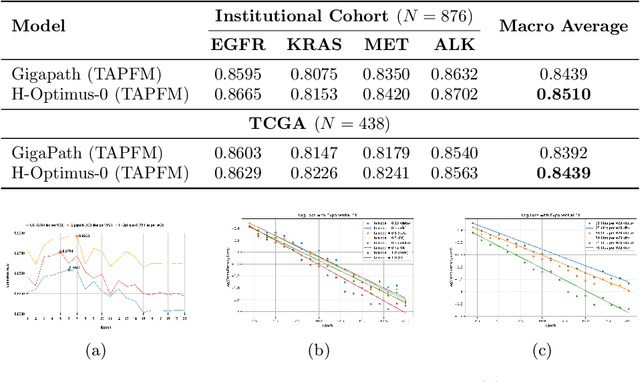
Pathology foundation models (PFMs) have emerged as powerful tools for analyzing whole slide images (WSIs). However, adapting these pretrained PFMs for specific clinical tasks presents considerable challenges, primarily due to the availability of only weak (WSI-level) labels for gigapixel images, necessitating multiple instance learning (MIL) paradigm for effective WSI analysis. This paper proposes a novel approach for single-GPU \textbf{T}ask \textbf{A}daptation of \textbf{PFM}s (TAPFM) that uses vision transformer (\vit) attention for MIL aggregation while optimizing both for feature representations and attention weights. The proposed approach maintains separate computational graphs for MIL aggregator and the PFM to create stable training dynamics that align with downstream task objectives during end-to-end adaptation. Evaluated on mutation prediction tasks for bladder cancer and lung adenocarcinoma across institutional and TCGA cohorts, TAPFM consistently outperforms conventional approaches, with H-Optimus-0 (TAPFM) outperforming the benchmarks. TAPFM effectively handles multi-label classification of actionable mutations as well. Thus, TAPFM makes adaptation of powerful pre-trained PFMs practical on standard hardware for various clinical applications.
Krysalis Hand: A Lightweight, High-Payload, 18-DoF Anthropomorphic End-Effector for Robotic Learning and Dexterous Manipulation
Apr 17, 2025



This paper presents the Krysalis Hand, a five-finger robotic end-effector that combines a lightweight design, high payload capacity, and a high number of degrees of freedom (DoF) to enable dexterous manipulation in both industrial and research settings. This design integrates the actuators within the hand while maintaining an anthropomorphic form. Each finger joint features a self-locking mechanism that allows the hand to sustain large external forces without active motor engagement. This approach shifts the payload limitation from the motor strength to the mechanical strength of the hand, allowing the use of smaller, more cost-effective motors. With 18 DoF and weighing only 790 grams, the Krysalis Hand delivers an active squeezing force of 10 N per finger and supports a passive payload capacity exceeding 10 lbs. These characteristics make Krysalis Hand one of the lightest, strongest, and most dexterous robotic end-effectors of its kind. Experimental evaluations validate its ability to perform intricate manipulation tasks and handle heavy payloads, underscoring its potential for industrial applications as well as academic research. All code related to the Krysalis Hand, including control and teleoperation, is available on the project GitHub repository: https://github.com/Soltanilara/Krysalis_Hand
Thing2Reality: Transforming 2D Content into Conditioned Multiviews and 3D Gaussian Objects for XR Communication
Oct 09, 2024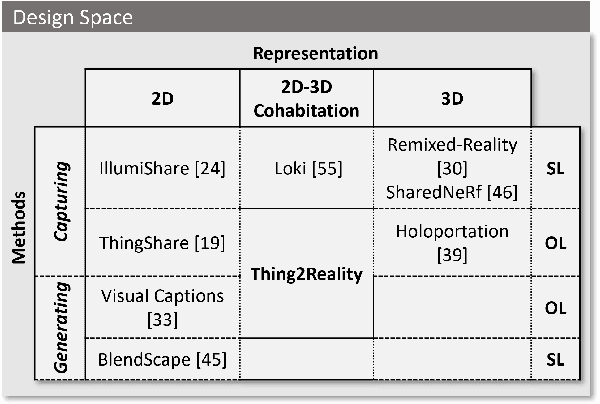
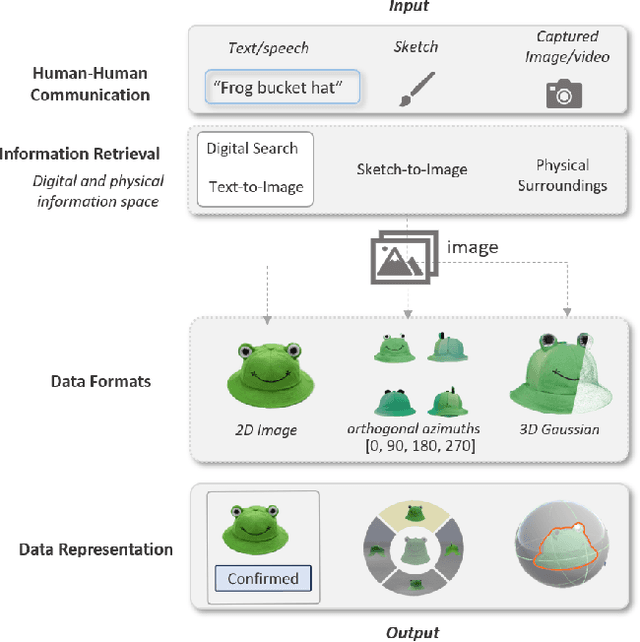
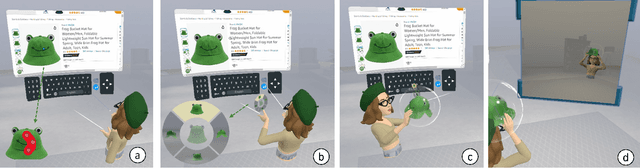
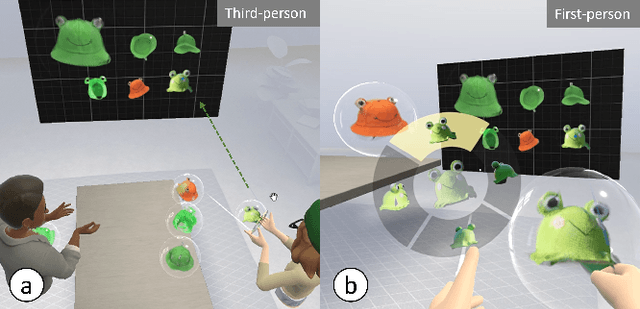
During remote communication, participants often share both digital and physical content, such as product designs, digital assets, and environments, to enhance mutual understanding. Recent advances in augmented communication have facilitated users to swiftly create and share digital 2D copies of physical objects from video feeds into a shared space. However, conventional 2D representations of digital objects restricts users' ability to spatially reference items in a shared immersive environment. To address this, we propose Thing2Reality, an Extended Reality (XR) communication platform that enhances spontaneous discussions of both digital and physical items during remote sessions. With Thing2Reality, users can quickly materialize ideas or physical objects in immersive environments and share them as conditioned multiview renderings or 3D Gaussians. Thing2Reality enables users to interact with remote objects or discuss concepts in a collaborative manner. Our user study revealed that the ability to interact with and manipulate 3D representations of objects significantly enhances the efficiency of discussions, with the potential to augment discussion of 2D artifacts.
XCAT-2.0: A Comprehensive Library of Personalized Digital Twins Derived from CT Scans
May 18, 2024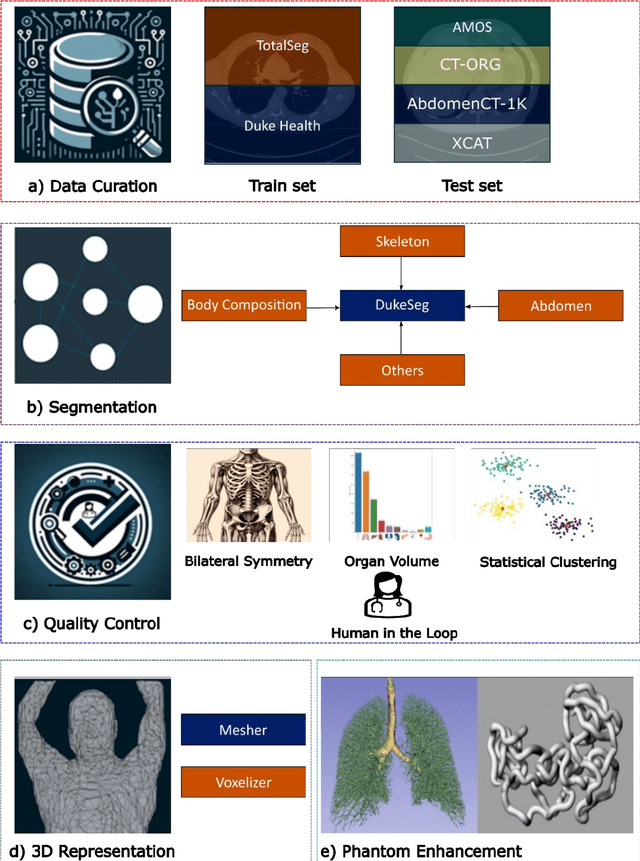
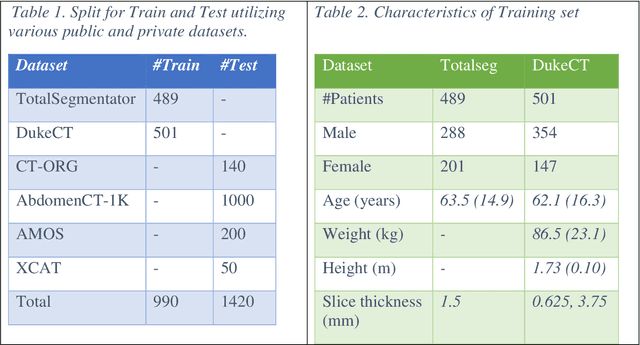
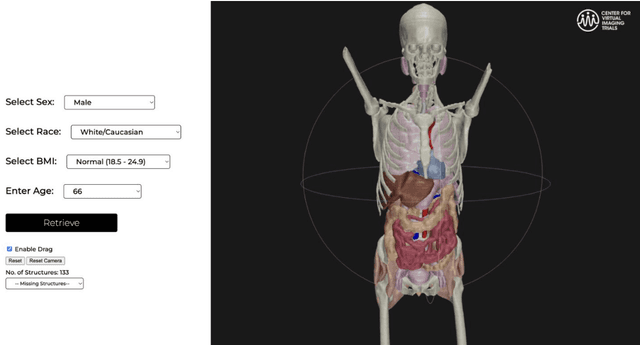
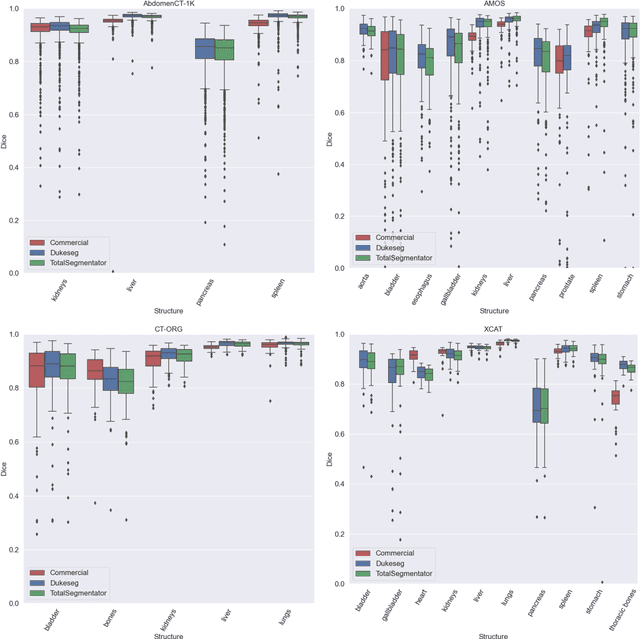
Virtual Imaging Trials (VIT) offer a cost-effective and scalable approach for evaluating medical imaging technologies. Computational phantoms, which mimic real patient anatomy and physiology, play a central role in VIT. However, the current libraries of computational phantoms face limitations, particularly in terms of sample size and diversity. Insufficient representation of the population hampers accurate assessment of imaging technologies across different patient groups. Traditionally, phantoms were created by manual segmentation, which is a laborious and time-consuming task, impeding the expansion of phantom libraries. This study presents a framework for realistic computational phantom modeling using a suite of four deep learning segmentation models, followed by three forms of automated organ segmentation quality control. Over 2500 computational phantoms with up to 140 structures illustrating a sophisticated approach to detailed anatomical modeling are released. Phantoms are available in both voxelized and surface mesh formats. The framework is aggregated with an in-house CT scanner simulator to produce realistic CT images. The framework can potentially advance virtual imaging trials, facilitating comprehensive and reliable evaluations of medical imaging technologies. Phantoms may be requested at https://cvit.duke.edu/resources/, code, model weights, and sample CT images are available at https://xcat-2.github.io.
Augmented Object Intelligence: Making the Analog World Interactable with XR-Objects
Apr 23, 2024



Seamless integration of physical objects as interactive digital entities remains a challenge for spatial computing. This paper introduces Augmented Object Intelligence (AOI), a novel XR interaction paradigm designed to blur the lines between digital and physical by equipping real-world objects with the ability to interact as if they were digital, where every object has the potential to serve as a portal to vast digital functionalities. Our approach utilizes object segmentation and classification, combined with the power of Multimodal Large Language Models (MLLMs), to facilitate these interactions. We implement the AOI concept in the form of XR-Objects, an open-source prototype system that provides a platform for users to engage with their physical environment in rich and contextually relevant ways. This system enables analog objects to not only convey information but also to initiate digital actions, such as querying for details or executing tasks. Our contributions are threefold: (1) we define the AOI concept and detail its advantages over traditional AI assistants, (2) detail the XR-Objects system's open-source design and implementation, and (3) show its versatility through a variety of use cases and a user study.
RABBIT: A Robot-Assisted Bed Bathing System with Multimodal Perception and Integrated Compliance
Jan 26, 2024This paper introduces RABBIT, a novel robot-assisted bed bathing system designed to address the growing need for assistive technologies in personal hygiene tasks. It combines multimodal perception and dual (software and hardware) compliance to perform safe and comfortable physical human-robot interaction. Using RGB and thermal imaging to segment dry, soapy, and wet skin regions accurately, RABBIT can effectively execute washing, rinsing, and drying tasks in line with expert caregiving practices. Our system includes custom-designed motion primitives inspired by human caregiving techniques, and a novel compliant end-effector called Scrubby, optimized for gentle and effective interactions. We conducted a user study with 12 participants, including one participant with severe mobility limitations, demonstrating the system's effectiveness and perceived comfort. Supplementary material and videos can be found on our website https://emprise.cs.cornell.edu/rabbit.
InstructPipe: Building Visual Programming Pipelines with Human Instructions
Dec 15, 2023



Visual programming provides beginner-level programmers with a coding-free experience to build their customized pipelines. Existing systems require users to build a pipeline entirely from scratch, implying that novice users need to set up and link appropriate nodes all by themselves, starting from a blank workspace. We present InstructPipe, an AI assistant that enables users to start prototyping machine learning (ML) pipelines with text instructions. We designed two LLM modules and a code interpreter to execute our solution. LLM modules generate pseudocode of a target pipeline, and the interpreter renders a pipeline in the node-graph editor for further human-AI collaboration. Technical evaluations reveal that InstructPipe reduces user interactions by 81.1% compared to traditional methods. Our user study (N=16) showed that InstructPipe empowers novice users to streamline their workflow in creating desired ML pipelines, reduce their learning curve, and spark innovative ideas with open-ended commands.
Multiscale Vision Transformer With Deep Clustering-Guided Refinement for Weakly Supervised Object Localization
Dec 15, 2023



This work addresses the task of weakly-supervised object localization. The goal is to learn object localization using only image-level class labels, which are much easier to obtain compared to bounding box annotations. This task is important because it reduces the need for labor-intensive ground-truth annotations. However, methods for object localization trained using weak supervision often suffer from limited accuracy in localization. To address this challenge and enhance localization accuracy, we propose a multiscale object localization transformer (MOLT). It comprises multiple object localization transformers that extract patch embeddings across various scales. Moreover, we introduce a deep clustering-guided refinement method that further enhances localization accuracy by utilizing separately extracted image segments. These segments are obtained by clustering pixels using convolutional neural networks. Finally, we demonstrate the effectiveness of our proposed method by conducting experiments on the publicly available ILSVRC-2012 dataset.
* 5 pages