 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolGrad: Efficient Tool-use Dataset Generation with Textual "Gradients"
Aug 06, 2025Prior work synthesizes tool-use LLM datasets by first generating a user query, followed by complex tool-use annotations like DFS. This leads to inevitable annotation failures and low efficiency in data generation. We introduce ToolGrad, an agentic framework that inverts this paradigm. ToolGrad first constructs valid tool-use chains through an iterative process guided by textual "gradients", and then synthesizes corresponding user queries. This "answer-first" approach led to ToolGrad-5k, a dataset generated with more complex tool use, lower cost, and 100% pass rate. Experiments show that models trained on ToolGrad-5k outperform those on expensive baseline datasets and proprietary LLMs, even on OOD benchmarks.
Controlling Avatar Diffusion with Learnable Gaussian Embedding
Mar 20, 2025Recent advances in diffusion models have made significant progress in digital human generation. However, most existing models still struggle to maintain 3D consistency, temporal coherence, and motion accuracy. A key reason for these shortcomings is the limited representation ability of commonly used control signals(e.g., landmarks, depth maps, etc.). In addition, the lack of diversity in identity and pose variations in public datasets further hinders progress in this area. In this paper, we analyze the shortcomings of current control signals and introduce a novel control signal representation that is optimizable, dense, expressive, and 3D consistent. Our method embeds a learnable neural Gaussian onto a parametric head surface, which greatly enhances the consistency and expressiveness of diffusion-based head models. Regarding the dataset, we synthesize a large-scale dataset with multiple poses and identities. In addition, we use real/synthetic labels to effectively distinguish real and synthetic data, minimizing the impact of imperfections in synthetic data on the generated head images. Extensive experiments show that our model outperforms existing methods in terms of realism, expressiveness, and 3D consistency. Our code, synthetic datasets, and pre-trained models will be released in our project page: https://ustc3dv.github.io/Learn2Control/
InstructPipe: Building Visual Programming Pipelines with Human Instructions
Dec 15, 2023



Visual programming provides beginner-level programmers with a coding-free experience to build their customized pipelines. Existing systems require users to build a pipeline entirely from scratch, implying that novice users need to set up and link appropriate nodes all by themselves, starting from a blank workspace. We present InstructPipe, an AI assistant that enables users to start prototyping machine learning (ML) pipelines with text instructions. We designed two LLM modules and a code interpreter to execute our solution. LLM modules generate pseudocode of a target pipeline, and the interpreter renders a pipeline in the node-graph editor for further human-AI collaboration. Technical evaluations reveal that InstructPipe reduces user interactions by 81.1% compared to traditional methods. Our user study (N=16) showed that InstructPipe empowers novice users to streamline their workflow in creating desired ML pipelines, reduce their learning curve, and spark innovative ideas with open-ended commands.
IntrinsicNGP: Intrinsic Coordinate based Hash Encoding for Human NeRF
Mar 09, 2023Recently, many works have been proposed to utilize the neural radiance field for novel view synthesis of human performers. However, most of these methods require hours of training, making them difficult for practical use. To address this challenging problem, we propose IntrinsicNGP, which can train from scratch and achieve high-fidelity results in few minutes with videos of a human performer. To achieve this target, we introduce a continuous and optimizable intrinsic coordinate rather than the original explicit Euclidean coordinate in the hash encoding module of instant-NGP. With this novel intrinsic coordinate, IntrinsicNGP can aggregate inter-frame information for dynamic objects with the help of proxy geometry shapes. Moreover, the results trained with the given rough geometry shapes can be further refined with an optimizable offset field based on the intrinsic coordinate.Extensive experimental results on several datasets demonstrate the effectiveness and efficiency of IntrinsicNGP. We also illustrate our approach's ability to edit the shape of reconstructed subjects.
SelfNeRF: Fast Training NeRF for Human from Monocular Self-rotating Video
Oct 04, 2022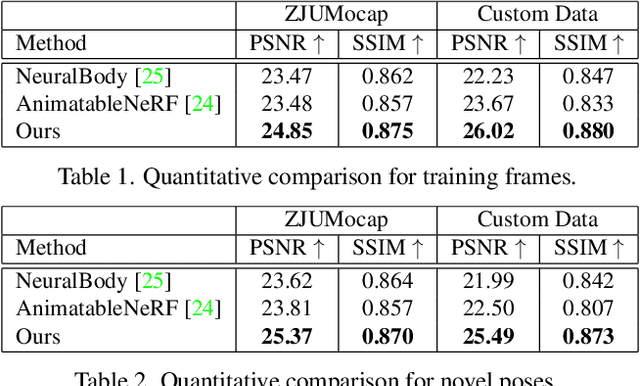



In this paper, we propose SelfNeRF, an efficient neural radiance field based novel view synthesis method for human performance. Given monocular self-rotating videos of human performers, SelfNeRF can train from scratch and achieve high-fidelity results in about twenty minutes. Some recent works have utilized the neural radiance field for dynamic human reconstruction. However, most of these methods need multi-view inputs and require hours of training, making it still difficult for practical use. To address this challenging problem, we introduce a surface-relative representation based on multi-resolution hash encoding that can greatly improve the training speed and aggregate inter-frame information. Extensive experimental results on several different datasets demonstrate the effectiveness and efficiency of SelfNeRF to challenging monocular videos.