 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedWorldEval: Scalable Robotic Policy Evaluation via Discrete Diffusion World Model
Apr 24, 2026Evaluating robotics policies across thousands of environments and thousands of tasks is infeasible with existing approaches. This motivates the need for a new methodology for scalable robotics policy evaluation. In this paper, we propose dWorldEval, which uses a discrete diffusion world model as a scalable evaluation proxy for robotics policies. Specifically, dWorldEval maps all modalities - including vision, language, and robotic actions - into a unified token space, modeling them via a single transformer-based denoising network. In this paper, we propose dWorldEval, using a discrete diffusion world model as a scalable evaluation proxy for robotics policy. Specifically, it maps all modalities, including vision, language, and robotics action into a unified token space, then denoises them with a single transformer network. Building on this architecture, we employ a sparse keyframe memory to maintain spatiotemporal consistency. We also introduce a progress token that indicates the degree of task completion. At inference, the model jointly predicts future observations and progress token, allowing automatically determine success when the progress reaches 1. Extensive experiments demonstrate that dWorldEval significantly outperforms previous approaches, i.e., WorldEval, Ctrl-World, and WorldGym, on LIBERO, RoboTwin, and multiple real-robot tasks. It paves the way for a new architectural paradigm in building world simulators for robotics evaluation at scale.
Hi-WM: Human-in-the-World-Model for Scalable Robot Post-Training
Apr 23, 2026Post-training is essential for turning pretrained generalist robot policies into reliable task-specific controllers, but existing human-in-the-loop pipelines remain tied to physical execution: each correction requires robot time, scene setup, resets, and operator supervision in the real world. Meanwhile, action-conditioned world models have been studied mainly for imagination, synthetic data generation, and policy evaluation. We propose \textbf{Human-in-the-World-Model (Hi-WM)}, a post-training framework that uses a learned world model as a reusable corrective substrate for failure-targeted policy improvement. A policy is first rolled out in closed loop inside the world model; when the rollout becomes incorrect or failure-prone, a human intervenes directly in the model to provide short corrective actions. Hi-WM caches intermediate states and supports rollback and branching, allowing a single failure state to be reused for multiple corrective continuations and yielding dense supervision around behaviors that the base policy handles poorly. The resulting corrective trajectories are then added back to the training set for post-training. We evaluate Hi-WM on three real-world manipulation tasks spanning both rigid and deformable object interaction, and on two policy backbones. Hi-WM improves real-world success by 37.9 points on average over the base policy and by 19.0 points over a world-model closed-loop baseline, while world-model evaluation correlates strongly with real-world performance (r = 0.953). These results suggest that world models can serve not only as generators or evaluators, but also as effective corrective substrates for scalable robot post-training.
See2Refine: Vision-Language Feedback Improves LLM-Based eHMI Action Designers
Feb 02, 2026Automated vehicles lack natural communication channels with other road users, making external Human-Machine Interfaces (eHMIs) essential for conveying intent and maintaining trust in shared environments. However, most eHMI studies rely on developer-crafted message-action pairs, which are difficult to adapt to diverse and dynamic traffic contexts. A promising alternative is to use Large Language Models (LLMs) as action designers that generate context-conditioned eHMI actions, yet such designers lack perceptual verification and typically depend on fixed prompts or costly human-annotated feedback for improvement. We present See2Refine, a human-free, closed-loop framework that uses vision-language model (VLM) perceptual evaluation as automated visual feedback to improve an LLM-based eHMI action designer. Given a driving context and a candidate eHMI action, the VLM evaluates the perceived appropriateness of the action, and this feedback is used to iteratively revise the designer's outputs, enabling systematic refinement without human supervision. We evaluate our framework across three eHMI modalities (lightbar, eyes, and arm) and multiple LLM model sizes. Across settings, our framework consistently outperforms prompt-only LLM designers and manually specified baselines in both VLM-based metrics and human-subject evaluations. Results further indicate that the improvements generalize across modalities and that VLM evaluations are well aligned with human preferences, supporting the robustness and effectiveness of See2Refine for scalable action design.
ActiveUMI: Robotic Manipulation with Active Perception from Robot-Free Human Demonstrations
Oct 02, 2025


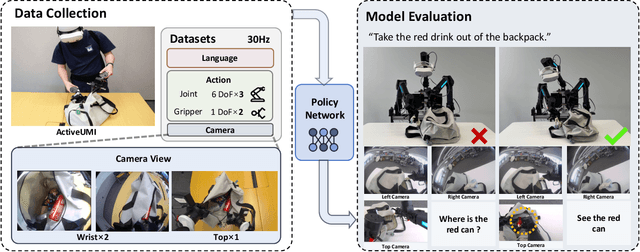
We present ActiveUMI, a framework for a data collection system that transfers in-the-wild human demonstrations to robots capable of complex bimanual manipulation. ActiveUMI couples a portable VR teleoperation kit with sensorized controllers that mirror the robot's end-effectors, bridging human-robot kinematics via precise pose alignment. To ensure mobility and data quality, we introduce several key techniques, including immersive 3D model rendering, a self-contained wearable computer, and efficient calibration methods. ActiveUMI's defining feature is its capture of active, egocentric perception. By recording an operator's deliberate head movements via a head-mounted display, our system learns the crucial link between visual attention and manipulation. We evaluate ActiveUMI on six challenging bimanual tasks. Policies trained exclusively on ActiveUMI data achieve an average success rate of 70\% on in-distribution tasks and demonstrate strong generalization, retaining a 56\% success rate when tested on novel objects and in new environments. Our results demonstrate that portable data collection systems, when coupled with learned active perception, provide an effective and scalable pathway toward creating generalizable and highly capable real-world robot policies.
ToolGrad: Efficient Tool-use Dataset Generation with Textual "Gradients"
Aug 06, 2025Prior work synthesizes tool-use LLM datasets by first generating a user query, followed by complex tool-use annotations like DFS. This leads to inevitable annotation failures and low efficiency in data generation. We introduce ToolGrad, an agentic framework that inverts this paradigm. ToolGrad first constructs valid tool-use chains through an iterative process guided by textual "gradients", and then synthesizes corresponding user queries. This "answer-first" approach led to ToolGrad-5k, a dataset generated with more complex tool use, lower cost, and 100% pass rate. Experiments show that models trained on ToolGrad-5k outperform those on expensive baseline datasets and proprietary LLMs, even on OOD benchmarks.
ChatVLA-2: Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge
May 29, 2025Vision-language-action (VLA) models have emerged as the next generation of models in robotics. However, despite leveraging powerful pre-trained Vision-Language Models (VLMs), existing end-to-end VLA systems often lose key capabilities during fine-tuning as the model adapts to specific robotic tasks. We argue that a generalizable VLA model should retain and expand upon the VLM's core competencies: 1) Open-world embodied reasoning - the VLA should inherit the knowledge from VLM, i.e., recognize anything that the VLM can recognize, be capable of solving math problems, and possess visual-spatial intelligence, 2) Reasoning following - effectively translating the open-world reasoning into actionable steps for the robot. In this work, we introduce ChatVLA-2, a novel mixture-of-expert VLA model coupled with a specialized two-stage training pipeline designed to preserve the VLM's original strengths while enabling actionable reasoning. To validate our approach, we design a math-matching task wherein a robot interprets math problems written on a whiteboard and picks corresponding number cards from a table to solve equations. Remarkably, our method exhibits exceptional mathematical reasoning and OCR capabilities, despite these abilities not being explicitly trained within the VLA. Furthermore, we demonstrate that the VLA possesses strong spatial reasoning skills, enabling it to interpret novel directional instructions involving previously unseen objects. Overall, our method showcases reasoning and comprehension abilities that significantly surpass state-of-the-art imitation learning methods such as OpenVLA, DexVLA, and pi-zero. This work represents a substantial advancement toward developing truly generalizable robotic foundation models endowed with robust reasoning capacities.
Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge
May 28, 2025Vision-language-action (VLA) models have emerged as the next generation of models in robotics. However, despite leveraging powerful pre-trained Vision-Language Models (VLMs), existing end-to-end VLA systems often lose key capabilities during fine-tuning as the model adapts to specific robotic tasks. We argue that a generalizable VLA model should retain and expand upon the VLM's core competencies: 1) Open-world embodied reasoning - the VLA should inherit the knowledge from VLM, i.e., recognize anything that the VLM can recognize, capable of solving math problems, possessing visual-spatial intelligence, 2) Reasoning following - effectively translating the open-world reasoning into actionable steps for the robot. In this work, we introduce ChatVLA-2, a novel mixture-of-expert VLA model coupled with a specialized three-stage training pipeline designed to preserve the VLM's original strengths while enabling actionable reasoning. To validate our approach, we design a math-matching task wherein a robot interprets math problems written on a whiteboard and picks corresponding number cards from a table to solve equations. Remarkably, our method exhibits exceptional mathematical reasoning and OCR capabilities, despite these abilities not being explicitly trained within the VLA. Furthermore, we demonstrate that the VLA possesses strong spatial reasoning skills, enabling it to interpret novel directional instructions involving previously unseen objects. Overall, our method showcases reasoning and comprehension abilities that significantly surpass state-of-the-art imitation learning methods such as OpenVLA, DexVLA, and pi-zero. This work represents a substantial advancement toward developing truly generalizable robotic foundation models endowed with robust reasoning capacities.
HealthGenie: Empowering Users with Healthy Dietary Guidance through Knowledge Graph and Large Language Models
Apr 20, 2025Seeking dietary guidance often requires navigating complex professional knowledge while accommodating individual health conditions. Knowledge Graphs (KGs) offer structured and interpretable nutritional information, whereas Large Language Models (LLMs) naturally facilitate conversational recommendation delivery. In this paper, we present HealthGenie, an interactive system that combines the strengths of LLMs and KGs to provide personalized dietary recommendations along with hierarchical information visualization for a quick and intuitive overview. Upon receiving a user query, HealthGenie performs query refinement and retrieves relevant information from a pre-built KG. The system then visualizes and highlights pertinent information, organized by defined categories, while offering detailed, explainable recommendation rationales. Users can further tailor these recommendations by adjusting preferences interactively. Our evaluation, comprising a within-subject comparative experiment and an open-ended discussion, demonstrates that HealthGenie effectively supports users in obtaining personalized dietary guidance based on their health conditions while reducing interaction effort and cognitive load. These findings highlight the potential of LLM-KG integration in supporting decision-making through explainable and visualized information. We examine the system's usefulness and effectiveness with an N=12 within-subject study and provide design considerations for future systems that integrate conversational LLM and KG.
ObjectVLA: End-to-End Open-World Object Manipulation Without Demonstration
Feb 26, 2025Imitation learning has proven to be highly effective in teaching robots dexterous manipulation skills. However, it typically relies on large amounts of human demonstration data, which limits its scalability and applicability in dynamic, real-world environments. One key challenge in this context is object generalization, where a robot trained to perform a task with one object, such as "hand over the apple," struggles to transfer its skills to a semantically similar but visually different object, such as "hand over the peach." This gap in generalization to new objects beyond those in the same category has yet to be adequately addressed in previous work on end-to-end visuomotor policy learning. In this paper, we present a simple yet effective approach for achieving object generalization through Vision-Language-Action (VLA) models, referred to as \textbf{ObjectVLA}. Our model enables robots to generalize learned skills to novel objects without requiring explicit human demonstrations for each new target object. By leveraging vision-language pair data, our method provides a lightweight and scalable way to inject knowledge about the target object, establishing an implicit link between the object and the desired action. We evaluate ObjectVLA on a real robotic platform, demonstrating its ability to generalize across 100 novel objects with a 64\% success rate in selecting objects not seen during training. Furthermore, we propose a more accessible method for enhancing object generalization in VLA models, using a smartphone to capture a few images and fine-tune the pre-trained model. These results highlight the effectiveness of our approach in enabling object-level generalization and reducing the need for extensive human demonstrations, paving the way for more flexible and scalable robotic learning systems.
ChatVLA: Unified Multimodal Understanding and Robot Control with Vision-Language-Action Model
Feb 21, 2025Humans possess a unified cognitive ability to perceive, comprehend, and interact with the physical world. Why can't large language models replicate this holistic understanding? Through a systematic analysis of existing training paradigms in vision-language-action models (VLA), we identify two key challenges: spurious forgetting, where robot training overwrites crucial visual-text alignments, and task interference, where competing control and understanding tasks degrade performance when trained jointly. To overcome these limitations, we propose ChatVLA, a novel framework featuring Phased Alignment Training, which incrementally integrates multimodal data after initial control mastery, and a Mixture-of-Experts architecture to minimize task interference. ChatVLA demonstrates competitive performance on visual question-answering datasets and significantly surpasses state-of-the-art vision-language-action (VLA) methods on multimodal understanding benchmarks. Notably, it achieves a six times higher performance on MMMU and scores 47.2% on MMStar with a more parameter-efficient design than ECoT. Furthermore, ChatVLA demonstrates superior performance on 25 real-world robot manipulation tasks compared to existing VLA methods like OpenVLA. Our findings highlight the potential of our unified framework for achieving both robust multimodal understanding and effective robot control.