 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBifrost: Steering Strategic Trajectories to Bridge Contextual Gaps for Self-Improving Agents
Feb 05, 2026Autonomous agents excel in self-improvement through reflection and iterative refinement, which reuse successful task trajectories as in-context examples to assist subsequent reasoning. However, shifting across tasks often introduces a context mismatch. Hence, existing approaches either discard the trajectories or manipulate them using heuristics, leading to a non-negligible fine-tuning cost or unguaranteed performance. To bridge this gap, we reveal a context-trajectory correlation, where shifts of context are highly parallel with shifts of trajectory. Based on this finding, we propose BrIdge contextual gap FoR imprOvised trajectory STeering (Bifrost), a training-free method that leverages context differences to precisely guide the adaptation of previously solved trajectories towards the target task, mitigating the misalignment caused by context shifts. Our trajectory adaptation is conducted at the representation level using agent hidden states, ensuring trajectory transformation accurately aligns with the target context in a shared space. Across diverse benchmarks, Bifrost consistently outperforms existing trajectory reuse and finetuned self-improvement methods, demonstrating that agents can effectively leverage past experiences despite substantial context shifts.
From Voice to Value: Leveraging AI to Enhance Spoken Online Reviews on the Go
Dec 06, 2024Online reviews help people make better decisions. Review platforms usually depend on typed input, where leaving a good review requires significant effort because users must carefully organize and articulate their thoughts. This may discourage users from leaving comprehensive and high-quality reviews, especially when they are on the go. To address this challenge, we developed Vocalizer, a mobile application that enables users to provide reviews through voice input, with enhancements from a large language model (LLM). In a longitudinal study, we analysed user interactions with the app, focusing on AI-driven features that help refine and improve reviews. Our findings show that users frequently utilized the AI agent to add more detailed information to their reviews. We also show how interactive AI features can improve users self-efficacy and willingness to share reviews online. Finally, we discuss the opportunities and challenges of integrating AI assistance into review-writing systems.
RoCap: A Robotic Data Collection Pipeline for the Pose Estimation of Appearance-Changing Objects
Jul 10, 2024



Object pose estimation plays a vital role in mixed-reality interactions when users manipulate tangible objects as controllers. Traditional vision-based object pose estimation methods leverage 3D reconstruction to synthesize training data. However, these methods are designed for static objects with diffuse colors and do not work well for objects that change their appearance during manipulation, such as deformable objects like plush toys, transparent objects like chemical flasks, reflective objects like metal pitchers, and articulated objects like scissors. To address this limitation, we propose Rocap, a robotic pipeline that emulates human manipulation of target objects while generating data labeled with ground truth pose information. The user first gives the target object to a robotic arm, and the system captures many pictures of the object in various 6D configurations. The system trains a model by using captured images and their ground truth pose information automatically calculated from the joint angles of the robotic arm. We showcase pose estimation for appearance-changing objects by training simple deep-learning models using the collected data and comparing the results with a model trained with synthetic data based on 3D reconstruction via quantitative and qualitative evaluation. The findings underscore the promising capabilities of Rocap.
ElasticPlay: Interactive Video Summarization with Dynamic Time Budgets
Aug 23, 2017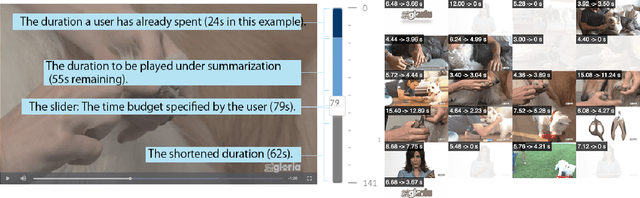
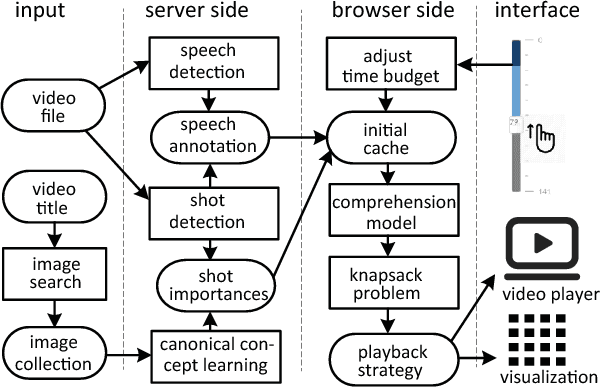
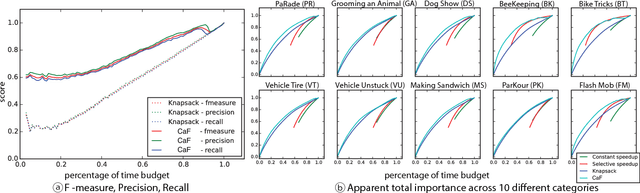
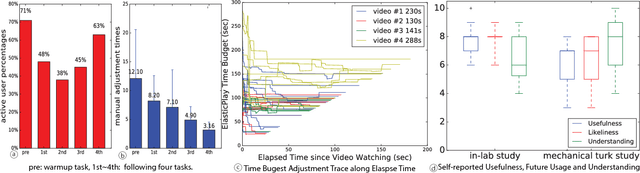
Video consumption is being shifted from sit-and-watch to selective skimming. Existing video player interfaces, however, only provide indirect manipulation to support this emerging behavior. Video summarization alleviates this issue to some extent, shortening a video based on the desired length of a summary as an input variable. But an optimal length of a summarized video is often not available in advance. Moreover, the user cannot edit the summary once it is produced, limiting its practical applications. We argue that video summarization should be an interactive, mixed-initiative process in which users have control over the summarization procedure while algorithms help users achieve their goal via video understanding. In this paper, we introduce ElasticPlay, a mixed-initiative approach that combines an advanced video summarization technique with direct interface manipulation to help users control the video summarization process. Users can specify a time budget for the remaining content while watching a video; our system then immediately updates the playback plan using our proposed cut-and-forward algorithm, determining which parts to skip or to fast-forward. This interactive process allows users to fine-tune the summarization result with immediate feedback. We show that our system outperforms existing video summarization techniques on the TVSum50 dataset. We also report two lab studies (22 participants) and a Mechanical Turk deployment study (60 participants), and show that the participants responded favorably to ElasticPlay.