 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniQuery: Contextually Augmenting Captured Multimodal Memory to Enable Personal Question Answering
Sep 12, 2024
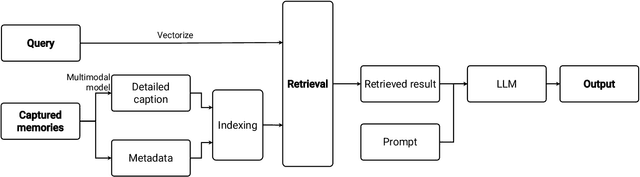


People often capture memories through photos, screenshots, and videos. While existing AI-based tools enable querying this data using natural language, they mostly only support retrieving individual pieces of information like certain objects in photos and struggle with answering more complex queries that involve interpreting interconnected memories like event sequences. We conducted a one-month diary study to collect realistic user queries and generated a taxonomy of necessary contextual information for integrating with captured memories. We then introduce OmniQuery, a novel system that is able to answer complex personal memory-related questions that require extracting and inferring contextual information. OmniQuery augments single captured memories through integrating scattered contextual information from multiple interconnected memories, retrieves relevant memories, and uses a large language model (LLM) to comprehensive answers. In human evaluations, we show the effectiveness of OmniQuery with an accuracy of 71.5%, and it outperformed a conventional RAG system, winning or tying in 74.5% of the time.
RoCap: A Robotic Data Collection Pipeline for the Pose Estimation of Appearance-Changing Objects
Jul 10, 2024



Object pose estimation plays a vital role in mixed-reality interactions when users manipulate tangible objects as controllers. Traditional vision-based object pose estimation methods leverage 3D reconstruction to synthesize training data. However, these methods are designed for static objects with diffuse colors and do not work well for objects that change their appearance during manipulation, such as deformable objects like plush toys, transparent objects like chemical flasks, reflective objects like metal pitchers, and articulated objects like scissors. To address this limitation, we propose Rocap, a robotic pipeline that emulates human manipulation of target objects while generating data labeled with ground truth pose information. The user first gives the target object to a robotic arm, and the system captures many pictures of the object in various 6D configurations. The system trains a model by using captured images and their ground truth pose information automatically calculated from the joint angles of the robotic arm. We showcase pose estimation for appearance-changing objects by training simple deep-learning models using the collected data and comparing the results with a model trained with synthetic data based on 3D reconstruction via quantitative and qualitative evaluation. The findings underscore the promising capabilities of Rocap.
OmniActions: Predicting Digital Actions in Response to Real-World Multimodal Sensory Inputs with LLMs
May 06, 2024



The progression to "Pervasive Augmented Reality" envisions easy access to multimodal information continuously. However, in many everyday scenarios, users are occupied physically, cognitively or socially. This may increase the friction to act upon the multimodal information that users encounter in the world. To reduce such friction, future interactive interfaces should intelligently provide quick access to digital actions based on users' context. To explore the range of possible digital actions, we conducted a diary study that required participants to capture and share the media that they intended to perform actions on (e.g., images or audio), along with their desired actions and other contextual information. Using this data, we generated a holistic design space of digital follow-up actions that could be performed in response to different types of multimodal sensory inputs. We then designed OmniActions, a pipeline powered by large language models (LLMs) that processes multimodal sensory inputs and predicts follow-up actions on the target information grounded in the derived design space. Using the empirical data collected in the diary study, we performed quantitative evaluations on three variations of LLM techniques (intent classification, in-context learning and finetuning) and identified the most effective technique for our task. Additionally, as an instantiation of the pipeline, we developed an interactive prototype and reported preliminary user feedback about how people perceive and react to the action predictions and its errors.