 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Consistency for LLM-Based Motion Trajectory Generation and Verification
Mar 31, 2026Self-consistency has proven to be an effective technique for improving LLM performance on natural language reasoning tasks in a lightweight, unsupervised manner. In this work, we study how to adapt self-consistency to visual domains. Specifically, we consider the generation and verification of LLM-produced motion graphics trajectories. Given a prompt (e.g., "Move the circle in a spiral path"), we first sample diverse motion trajectories from an LLM, and then identify groups of consistent trajectories via clustering. Our key insight is to model the family of shapes associated with a prompt as a prototype trajectory paired with a group of geometric transformations (e.g., rigid, similarity, and affine). Two trajectories can then be considered consistent if one can be transformed into the other under the warps allowable by the transformation group. We propose an algorithm that automatically recovers a shape family, using hierarchical relationships between a set of candidate transformation groups. Our approach improves the accuracy of LLM-based trajectory generation by 4-6%. We further extend our method to support verification, observing 11% precision gains over VLM baselines. Our code and dataset are available at https://majiaju.io/trajectory-self-consistency .
MoVer: Motion Verification for Motion Graphics Animations
Feb 19, 2025



While large vision-language models can generate motion graphics animations from text prompts, they regularly fail to include all of spatio-temporal properties described in the prompt. We introduce MoVer, a motion verification DSL based on first-order logic that can check spatio-temporal properties of a motion graphics animation. We identify a general set of such properties that people commonly use to describe animations (e.g., the direction and timing of motions, the relative positioning of objects, etc.). We implement these properties as predicates in MoVer and provide an execution engine that can apply a MoVer program to any input SVG-based motion graphics animation. We then demonstrate how MoVer can be used in an LLM-based synthesis and verification pipeline for iteratively refining motion graphics animations. Given a text prompt, our pipeline synthesizes a motion graphics animation and a corresponding MoVer program. Executing the verification program on the animation yields a report of the predicates that failed and the report can be automatically fed back to LLM to iteratively correct the animation. To evaluate our pipeline, we build a synthetic dataset of 5600 text prompts paired with ground truth MoVer verification programs. We find that while our LLM-based pipeline is able to automatically generate a correct motion graphics animation for 58.8% of the test prompts without any iteration, this number raises to 93.6% with up to 50 correction iterations. Project website: https://mover-dsl.github.io/
OmniQuery: Contextually Augmenting Captured Multimodal Memory to Enable Personal Question Answering
Sep 12, 2024
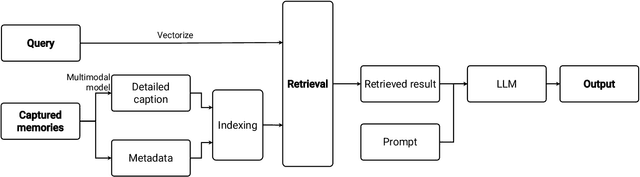


People often capture memories through photos, screenshots, and videos. While existing AI-based tools enable querying this data using natural language, they mostly only support retrieving individual pieces of information like certain objects in photos and struggle with answering more complex queries that involve interpreting interconnected memories like event sequences. We conducted a one-month diary study to collect realistic user queries and generated a taxonomy of necessary contextual information for integrating with captured memories. We then introduce OmniQuery, a novel system that is able to answer complex personal memory-related questions that require extracting and inferring contextual information. OmniQuery augments single captured memories through integrating scattered contextual information from multiple interconnected memories, retrieves relevant memories, and uses a large language model (LLM) to comprehensive answers. In human evaluations, we show the effectiveness of OmniQuery with an accuracy of 71.5%, and it outperformed a conventional RAG system, winning or tying in 74.5% of the time.
Automated Conversion of Music Videos into Lyric Videos
Aug 28, 2023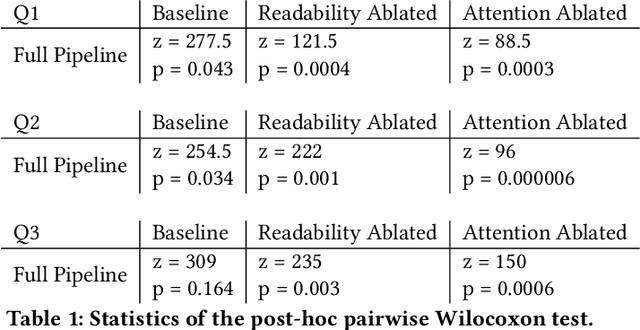



Musicians and fans often produce lyric videos, a form of music videos that showcase the song's lyrics, for their favorite songs. However, making such videos can be challenging and time-consuming as the lyrics need to be added in synchrony and visual harmony with the video. Informed by prior work and close examination of existing lyric videos, we propose a set of design guidelines to help creators make such videos. Our guidelines ensure the readability of the lyric text while maintaining a unified focus of attention. We instantiate these guidelines in a fully automated pipeline that converts an input music video into a lyric video. We demonstrate the robustness of our pipeline by generating lyric videos from a diverse range of input sources. A user study shows that lyric videos generated by our pipeline are effective in maintaining text readability and unifying the focus of attention.
Megapixel Photon-Counting Color Imaging using Quanta Image Sensor
Mar 21, 2019
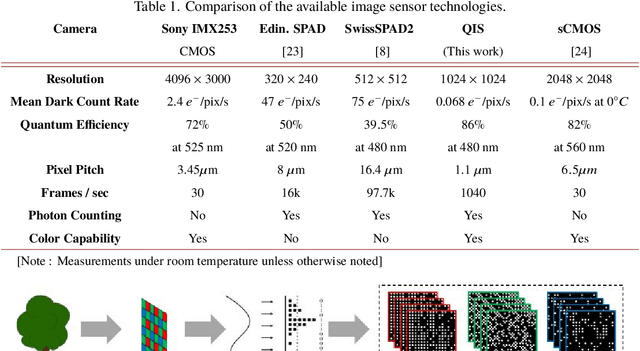


Quanta Image Sensor (QIS) is a single-photon detector designed for extremely low light imaging conditions. Majority of the existing QIS prototypes are monochrome based on single-photon avalanche diodes (SPAD). Color imaging has not been demonstrated with single-photon detectors due to the intrinsic difficulty of shrinking the pixel size and increasing the spatial resolution while maintaining acceptable intra-pixel cross-talk. In this paper, we present image reconstruction of the first color QIS with a resolution of $1024 \times 1024$ pixels, supporting both single-bit and multi-bit photon counting capability. Our color image reconstruction is enabled by a customized joint demosaicing-denoising algorithm, leveraging truncated Poisson statistics and variance stabilizing transforms. Experimental results of the new sensor and algorithm demonstrate superior color imaging performance for very low-light conditions with a mean exposure of as low as a few photons per pixel.