 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Neural Textures
Apr 18, 2024



Texture plays a vital role in enhancing visual richness in both real photographs and computer-generated imagery. However, the process of editing textures often involves laborious and repetitive manual adjustments of textons, which are the small, recurring local patterns that define textures. In this work, we introduce a fully unsupervised approach for representing textures using a compositional neural model that captures individual textons. We represent each texton as a 2D Gaussian function whose spatial support approximates its shape, and an associated feature that encodes its detailed appearance. By modeling a texture as a discrete composition of Gaussian textons, the representation offers both expressiveness and ease of editing. Textures can be edited by modifying the compositional Gaussians within the latent space, and new textures can be efficiently synthesized by feeding the modified Gaussians through a generator network in a feed-forward manner. This approach enables a wide range of applications, including transferring appearance from an image texture to another image, diversifying textures, texture interpolation, revealing/modifying texture variations, edit propagation, texture animation, and direct texton manipulation. The proposed approach contributes to advancing texture analysis, modeling, and editing techniques, and opens up new possibilities for creating visually appealing images with controllable textures.
DrawTalking: Building Interactive Worlds by Sketching and Speaking
Jan 11, 2024


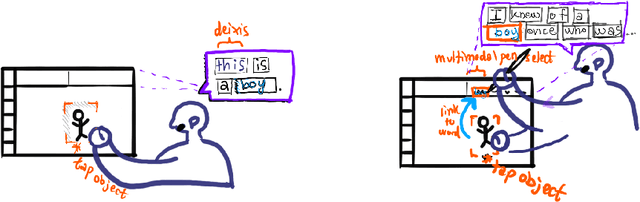
We introduce an interactive approach, DrawTalking, in which the user builds interactive worlds by sketching and speaking. It emphasizes user control and flexibility, and gives programming-like capability without code. We implemented it on the iPad. An open-ended study shows the mechanics resonate and are applicable to many creative-exploratory use cases. We hope to inspire and inform research in future natural user-centered interfaces.
Automated Conversion of Music Videos into Lyric Videos
Aug 28, 2023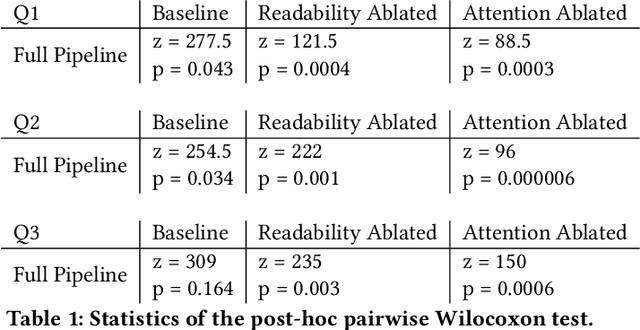



Musicians and fans often produce lyric videos, a form of music videos that showcase the song's lyrics, for their favorite songs. However, making such videos can be challenging and time-consuming as the lyrics need to be added in synchrony and visual harmony with the video. Informed by prior work and close examination of existing lyric videos, we propose a set of design guidelines to help creators make such videos. Our guidelines ensure the readability of the lyric text while maintaining a unified focus of attention. We instantiate these guidelines in a fully automated pipeline that converts an input music video into a lyric video. We demonstrate the robustness of our pipeline by generating lyric videos from a diverse range of input sources. A user study shows that lyric videos generated by our pipeline are effective in maintaining text readability and unifying the focus of attention.
Learning to Reconstruct 3D Manhattan Wireframes from a Single Image
May 17, 2019



In this paper, we propose a method to obtain a compact and accurate 3D wireframe representation from a single image by effectively exploiting global structural regularities. Our method trains a convolutional neural network to simultaneously detect salient junctions and straight lines, as well as predict their 3D depth and vanishing points. Compared with the state-of-the-art learning-based wireframe detection methods, our network is much simpler and more unified, leading to better 2D wireframe detection. With global structural priors such as Manhattan assumption, our method further reconstructs a full 3D wireframe model, a compact vector representation suitable for a variety of high-level vision tasks such as AR and CAD. We conduct extensive evaluations on a large synthetic dataset of urban scenes as well as real images. Our code and datasets will be released.