 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfessional Software Developers Don't Vibe, They Control: AI Agent Use for Coding in 2025
Dec 16, 2025The rise of AI agents is transforming how software can be built. The promise of agents is that developers might write code quicker, delegate multiple tasks to different agents, and even write a full piece of software purely out of natural language. In reality, what roles agents play in professional software development remains in question. This paper investigates how experienced developers use agents in building software, including their motivations, strategies, task suitability, and sentiments. Through field observations (N=13) and qualitative surveys (N=99), we find that while experienced developers value agents as a productivity boost, they retain their agency in software design and implementation out of insistence on fundamental software quality attributes, employing strategies for controlling agent behavior leveraging their expertise. In addition, experienced developers feel overall positive about incorporating agents into software development given their confidence in complementing the agents' limitations. Our results shed light on the value of software development best practices in effective use of agents, suggest the kinds of tasks for which agents may be suitable, and point towards future opportunities for better agentic interfaces and agentic use guidelines.
The Command Line GUIde: Graphical Interfaces from Man Pages via AI
Oct 01, 2025Although birthed in the era of teletypes, the command line shell survived the graphical interface revolution of the 1980's and lives on in modern desktop operating systems. The command line provides access to powerful functionality not otherwise exposed on the computer, but requires users to recall textual syntax and carefully scour documentation. In contrast, graphical interfaces let users organically discover and invoke possible actions through widgets and menus. To better expose the power of the command line, we demonstrate a mechanism for automatically creating graphical interfaces for command line tools by translating their documentation (in the form of man pages) into interface specifications via AI. Using these specifications, our user-facing system, called GUIde, presents the command options to the user graphically. We evaluate the generated interfaces on a corpus of commands to show to what degree GUIde offers thorough graphical interfaces for users' real-world command line tasks.
Orca: Browsing at Scale Through User-Driven and AI-Facilitated Orchestration Across Malleable Webpages
May 28, 2025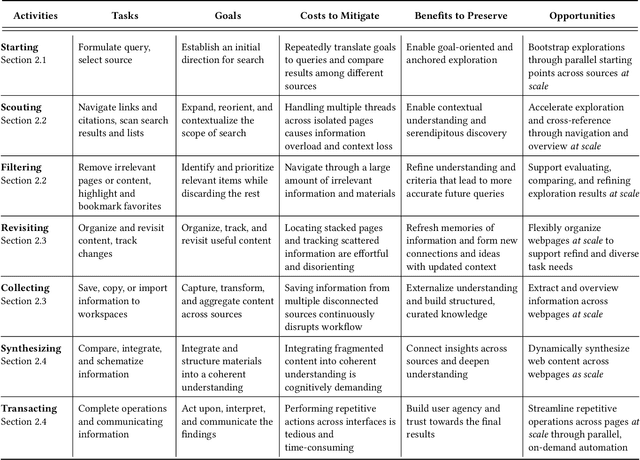



Web-based activities are fundamentally distributed across webpages. However, conventional browsers with stacks of tabs fail to support operating and synthesizing large volumes of information across pages. While recent AI systems enable fully automated web browsing and information synthesis, they often diminish user agency and hinder contextual understanding. Therefore, we explore how AI could instead augment users' interactions with content across webpages and mitigate cognitive and manual efforts. Through literature on information tasks and web browsing challenges, and an iterative design process, we present a rich set of novel interactions with our prototype web browser, Orca. Leveraging AI, Orca supports user-driven exploration, operation, organization, and synthesis of web content at scale. To enable browsing at scale, webpages are treated as malleable materials that humans and AI can collaboratively manipulate and compose into a malleable, dynamic, and browser-level workspace. Our evaluation revealed an increased "appetite" for information foraging, enhanced user control, and more flexibility in sensemaking across a broader information landscape on the web.
Less or More: Towards Glanceable Explanations for LLM Recommendations Using Ultra-Small Devices
Feb 26, 2025Large Language Models (LLMs) have shown remarkable potential in recommending everyday actions as personal AI assistants, while Explainable AI (XAI) techniques are being increasingly utilized to help users understand why a recommendation is given. Personal AI assistants today are often located on ultra-small devices such as smartwatches, which have limited screen space. The verbosity of LLM-generated explanations, however, makes it challenging to deliver glanceable LLM explanations on such ultra-small devices. To address this, we explored 1) spatially structuring an LLM's explanation text using defined contextual components during prompting and 2) presenting temporally adaptive explanations to users based on confidence levels. We conducted a user study to understand how these approaches impacted user experiences when interacting with LLM recommendations and explanations on ultra-small devices. The results showed that structured explanations reduced users' time to action and cognitive load when reading an explanation. Always-on structured explanations increased users' acceptance of AI recommendations. However, users were less satisfied with structured explanations compared to unstructured ones due to their lack of sufficient, readable details. Additionally, adaptively presenting structured explanations was less effective at improving user perceptions of the AI compared to the always-on structured explanations. Together with users' interview feedback, the results led to design implications to be mindful of when personalizing the content and timing of LLM explanations that are displayed on ultra-small devices.
Assistance or Disruption? Exploring and Evaluating the Design and Trade-offs of Proactive AI Programming Support
Feb 25, 2025AI programming tools enable powerful code generation, and recent prototypes attempt to reduce user effort with proactive AI agents, but their impact on programming workflows remains unexplored. We introduce and evaluate Codellaborator, a design probe LLM agent that initiates programming assistance based on editor activities and task context. We explored three interface variants to assess trade-offs between increasingly salient AI support: prompt-only, proactive agent, and proactive agent with presence and context (Codellaborator). In a within-subject study (N=18), we find that proactive agents increase efficiency compared to prompt-only paradigm, but also incur workflow disruptions. However, presence indicators and \revise{interaction context support} alleviated disruptions and improved users' awareness of AI processes. We underscore trade-offs of Codellaborator on user control, ownership, and code understanding, emphasizing the need to adapt proactivity to programming processes. Our research contributes to the design exploration and evaluation of proactive AI systems, presenting design implications on AI-integrated programming workflow.
LAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing
Feb 15, 2024


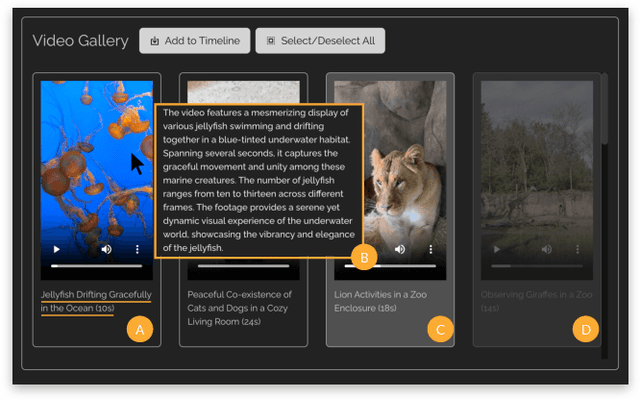
Video creation has become increasingly popular, yet the expertise and effort required for editing often pose barriers to beginners. In this paper, we explore the integration of large language models (LLMs) into the video editing workflow to reduce these barriers. Our design vision is embodied in LAVE, a novel system that provides LLM-powered agent assistance and language-augmented editing features. LAVE automatically generates language descriptions for the user's footage, serving as the foundation for enabling the LLM to process videos and assist in editing tasks. When the user provides editing objectives, the agent plans and executes relevant actions to fulfill them. Moreover, LAVE allows users to edit videos through either the agent or direct UI manipulation, providing flexibility and enabling manual refinement of agent actions. Our user study, which included eight participants ranging from novices to proficient editors, demonstrated LAVE's effectiveness. The results also shed light on user perceptions of the proposed LLM-assisted editing paradigm and its impact on users' creativity and sense of co-creation. Based on these findings, we propose design implications to inform the future development of agent-assisted content editing.
DrawTalking: Building Interactive Worlds by Sketching and Speaking
Jan 11, 2024


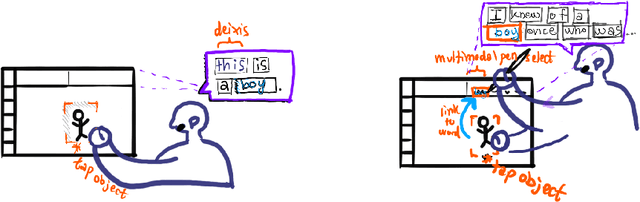
We introduce an interactive approach, DrawTalking, in which the user builds interactive worlds by sketching and speaking. It emphasizes user control and flexibility, and gives programming-like capability without code. We implemented it on the iPad. An open-ended study shows the mechanics resonate and are applicable to many creative-exploratory use cases. We hope to inspire and inform research in future natural user-centered interfaces.
1D-Touch: NLP-Assisted Coarse Text Selection via a Semi-Direct Gesture
Oct 26, 2023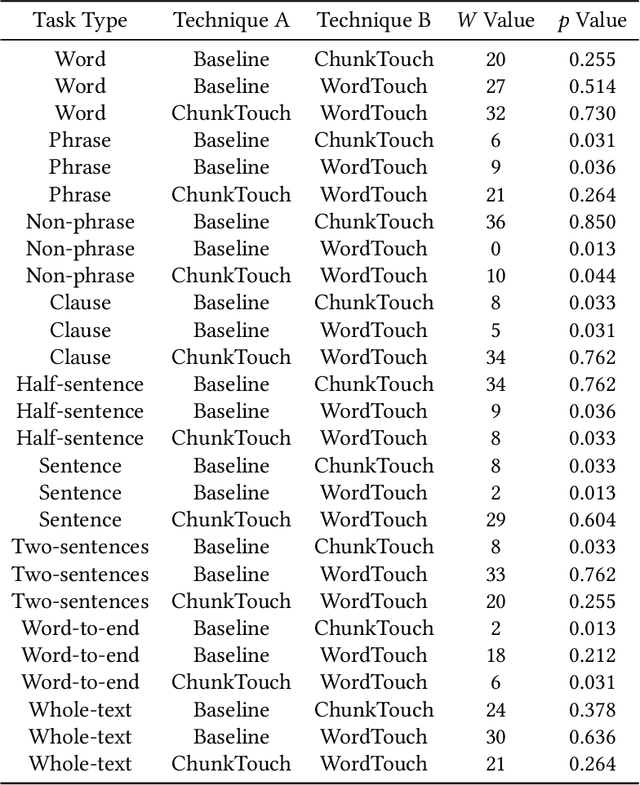



Existing text selection techniques on touchscreen focus on improving the control for moving the carets. Coarse-grained text selection on word and phrase levels has not received much support beyond word-snapping and entity recognition. We introduce 1D-Touch, a novel text selection method that complements the carets-based sub-word selection by facilitating the selection of semantic units of words and above. This method employs a simple vertical slide gesture to expand and contract a selection area from a word. The expansion can be by words or by semantic chunks ranging from sub-phrases to sentences. This technique shifts the concept of text selection, from defining a range by locating the first and last words, towards a dynamic process of expanding and contracting a textual semantic entity. To understand the effects of our approach, we prototyped and tested two variants: WordTouch, which offers a straightforward word-by-word expansion, and ChunkTouch, which leverages NLP to chunk text into syntactic units, allowing the selection to grow by semantically meaningful units in response to the sliding gesture. Our evaluation, focused on the coarse-grained selection tasks handled by 1D-Touch, shows a 20% improvement over the default word-snapping selection method on Android.
Structured Generation and Exploration of Design Space with Large Language Models for Human-AI Co-Creation
Oct 23, 2023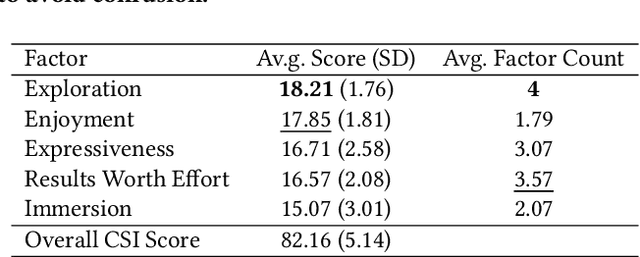
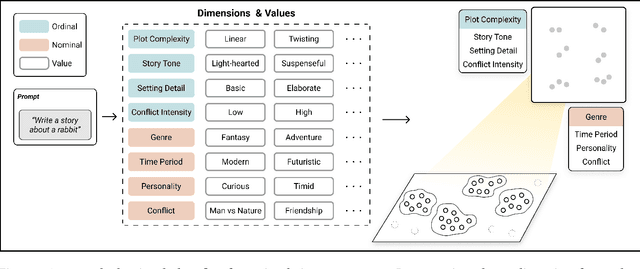
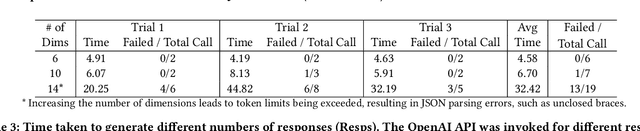
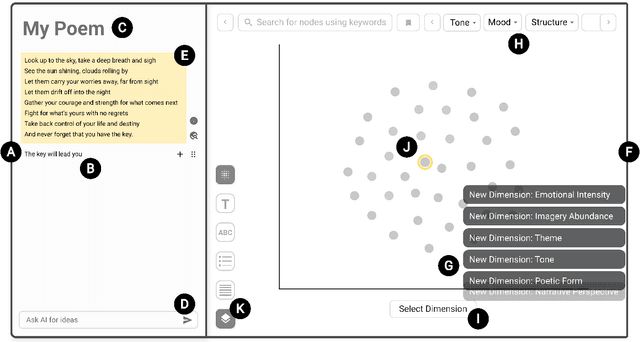
Thanks to their generative capabilities, large language models (LLMs) have become an invaluable tool for creative processes. These models have the capacity to produce hundreds and thousands of visual and textual outputs, offering abundant inspiration for creative endeavors. But are we harnessing their full potential? We argue that current interaction paradigms fall short, guiding users towards rapid convergence on a limited set of ideas, rather than empowering them to explore the vast latent design space in generative models. To address this limitation, we propose a framework that facilitates the structured generation of design space in which users can seamlessly explore, evaluate, and synthesize a multitude of responses. We demonstrate the feasibility and usefulness of this framework through the design and development of an interactive system, Luminate, and a user study with 8 professional writers. Our work advances how we interact with LLMs for creative tasks, introducing a way to harness the creative potential of LLMs.
CrossTalk: Intelligent Substrates for Language-Oriented Interaction in Video-Based Communication and Collaboration
Aug 07, 2023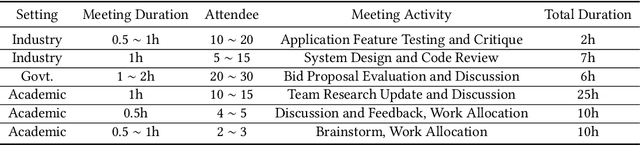
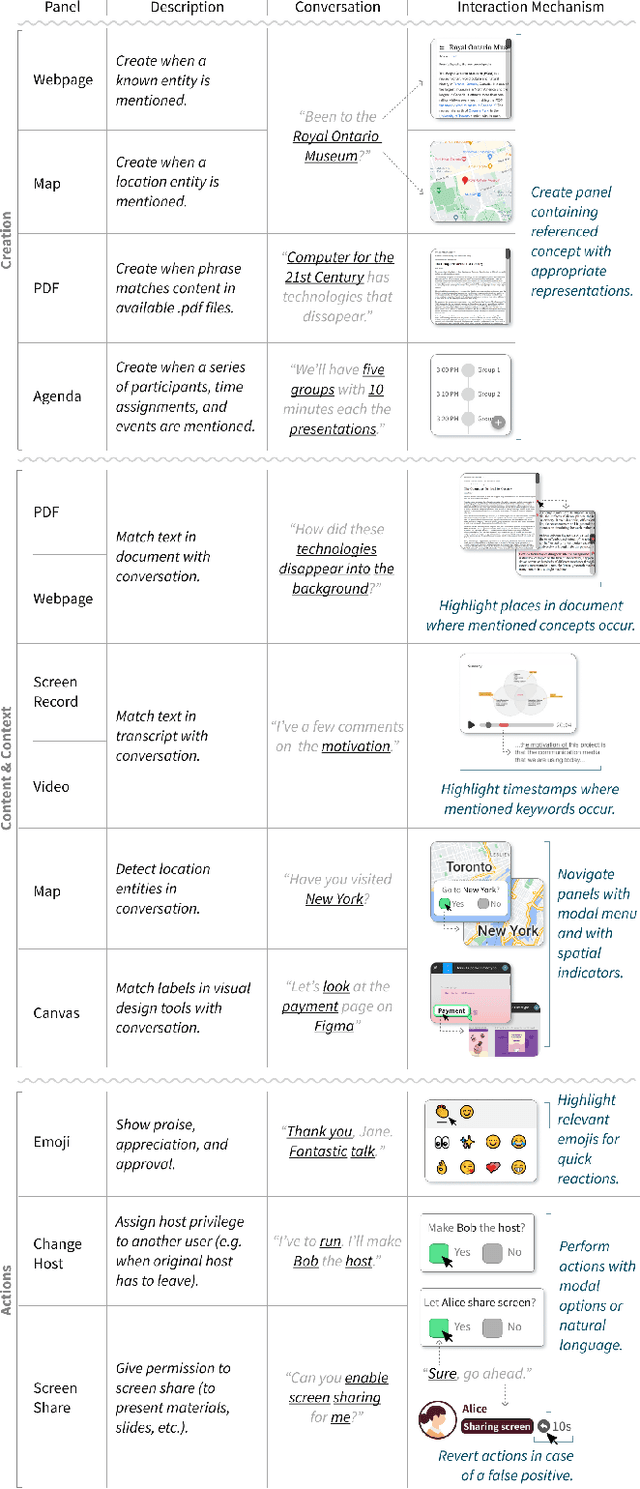
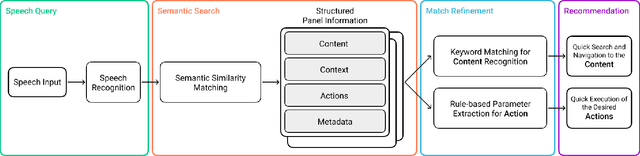
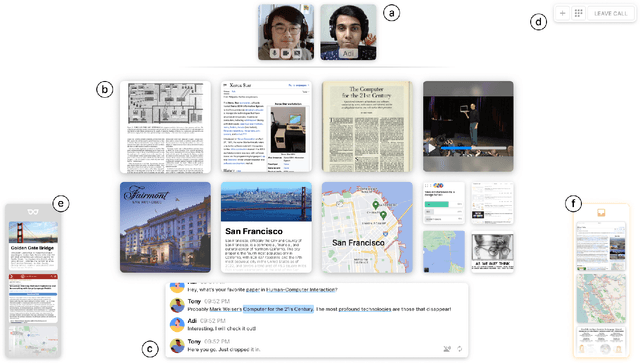
Despite the advances and ubiquity of digital communication media such as videoconferencing and virtual reality, they remain oblivious to the rich intentions expressed by users. Beyond transmitting audio, videos, and messages, we envision digital communication media as proactive facilitators that can provide unobtrusive assistance to enhance communication and collaboration. Informed by the results of a formative study, we propose three key design concepts to explore the systematic integration of intelligence into communication and collaboration, including the panel substrate, language-based intent recognition, and lightweight interaction techniques. We developed CrossTalk, a videoconferencing system that instantiates these concepts, which was found to enable a more fluid and flexible communication and collaboration experience.