 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing
Paper and Code
Feb 15, 2024


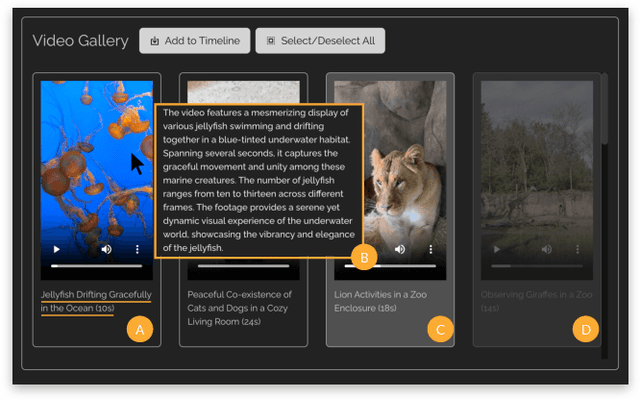
Video creation has become increasingly popular, yet the expertise and effort required for editing often pose barriers to beginners. In this paper, we explore the integration of large language models (LLMs) into the video editing workflow to reduce these barriers. Our design vision is embodied in LAVE, a novel system that provides LLM-powered agent assistance and language-augmented editing features. LAVE automatically generates language descriptions for the user's footage, serving as the foundation for enabling the LLM to process videos and assist in editing tasks. When the user provides editing objectives, the agent plans and executes relevant actions to fulfill them. Moreover, LAVE allows users to edit videos through either the agent or direct UI manipulation, providing flexibility and enabling manual refinement of agent actions. Our user study, which included eight participants ranging from novices to proficient editors, demonstrated LAVE's effectiveness. The results also shed light on user perceptions of the proposed LLM-assisted editing paradigm and its impact on users' creativity and sense of co-creation. Based on these findings, we propose design implications to inform the future development of agent-assisted content editing.