 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrca: Browsing at Scale Through User-Driven and AI-Facilitated Orchestration Across Malleable Webpages
May 28, 2025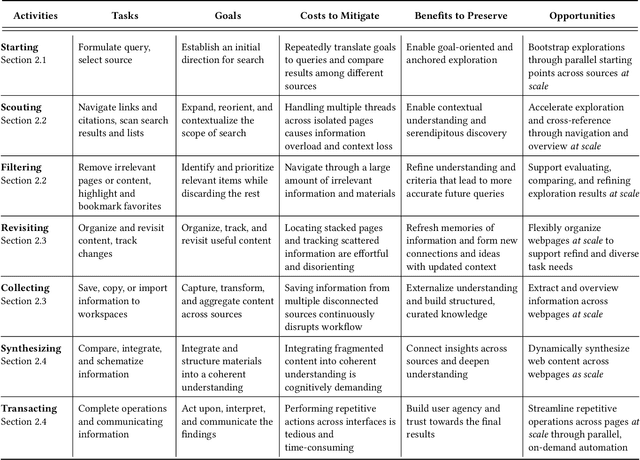



Web-based activities are fundamentally distributed across webpages. However, conventional browsers with stacks of tabs fail to support operating and synthesizing large volumes of information across pages. While recent AI systems enable fully automated web browsing and information synthesis, they often diminish user agency and hinder contextual understanding. Therefore, we explore how AI could instead augment users' interactions with content across webpages and mitigate cognitive and manual efforts. Through literature on information tasks and web browsing challenges, and an iterative design process, we present a rich set of novel interactions with our prototype web browser, Orca. Leveraging AI, Orca supports user-driven exploration, operation, organization, and synthesis of web content at scale. To enable browsing at scale, webpages are treated as malleable materials that humans and AI can collaboratively manipulate and compose into a malleable, dynamic, and browser-level workspace. Our evaluation revealed an increased "appetite" for information foraging, enhanced user control, and more flexibility in sensemaking across a broader information landscape on the web.
1D-Touch: NLP-Assisted Coarse Text Selection via a Semi-Direct Gesture
Oct 26, 2023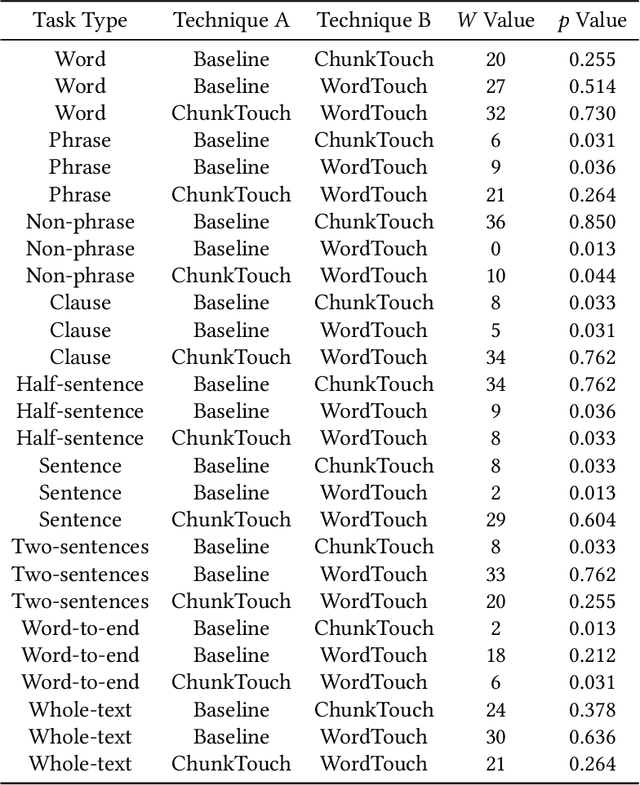



Existing text selection techniques on touchscreen focus on improving the control for moving the carets. Coarse-grained text selection on word and phrase levels has not received much support beyond word-snapping and entity recognition. We introduce 1D-Touch, a novel text selection method that complements the carets-based sub-word selection by facilitating the selection of semantic units of words and above. This method employs a simple vertical slide gesture to expand and contract a selection area from a word. The expansion can be by words or by semantic chunks ranging from sub-phrases to sentences. This technique shifts the concept of text selection, from defining a range by locating the first and last words, towards a dynamic process of expanding and contracting a textual semantic entity. To understand the effects of our approach, we prototyped and tested two variants: WordTouch, which offers a straightforward word-by-word expansion, and ChunkTouch, which leverages NLP to chunk text into syntactic units, allowing the selection to grow by semantically meaningful units in response to the sliding gesture. Our evaluation, focused on the coarse-grained selection tasks handled by 1D-Touch, shows a 20% improvement over the default word-snapping selection method on Android.
CrossTalk: Intelligent Substrates for Language-Oriented Interaction in Video-Based Communication and Collaboration
Aug 07, 2023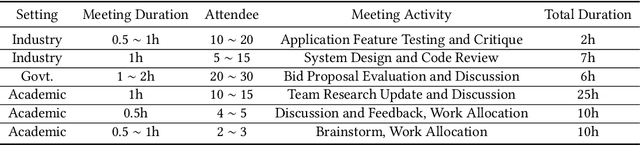
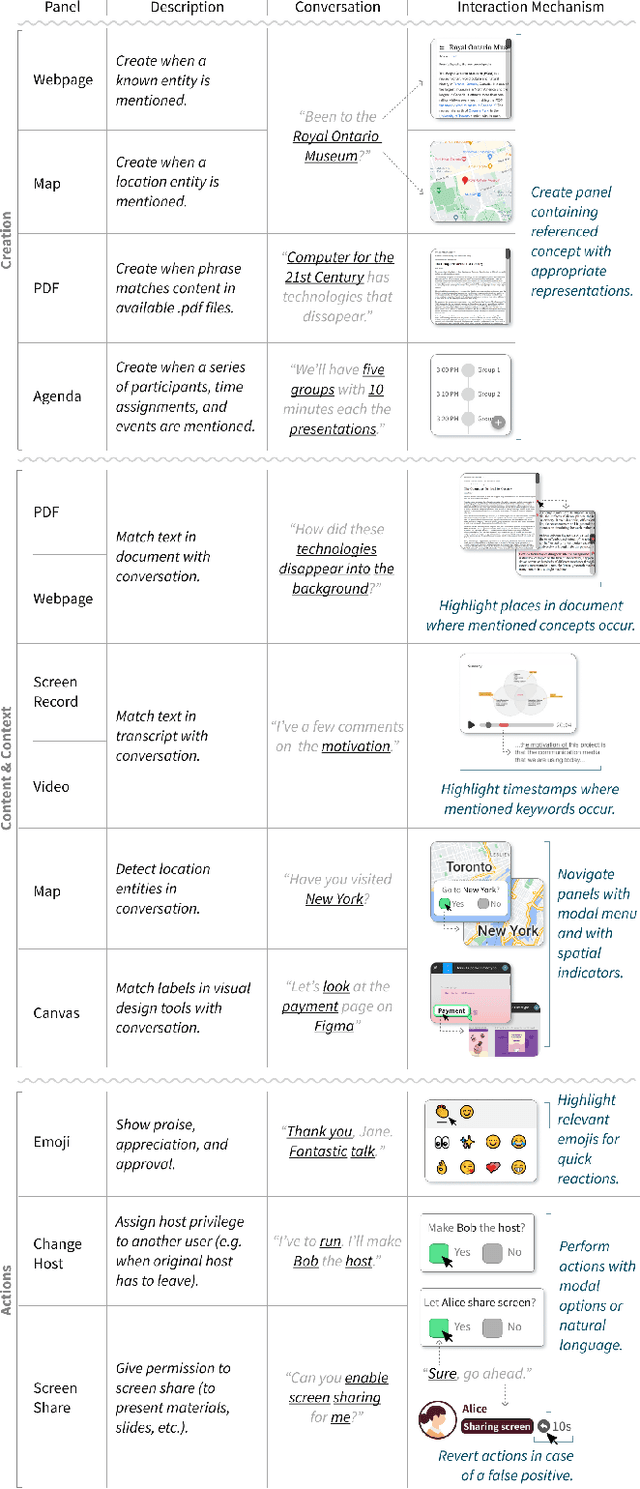
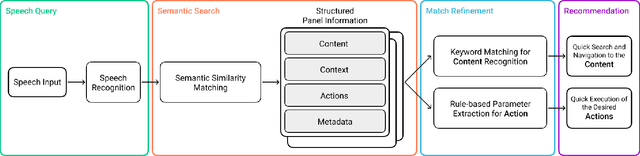
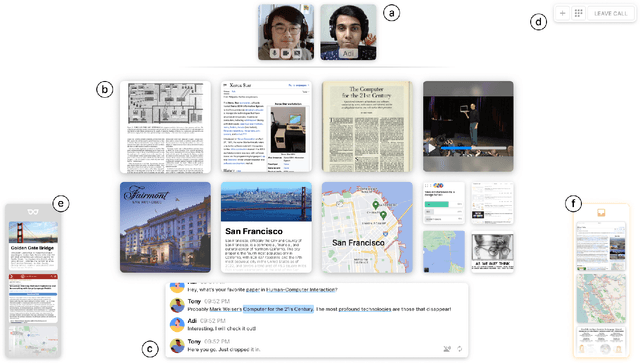
Despite the advances and ubiquity of digital communication media such as videoconferencing and virtual reality, they remain oblivious to the rich intentions expressed by users. Beyond transmitting audio, videos, and messages, we envision digital communication media as proactive facilitators that can provide unobtrusive assistance to enhance communication and collaboration. Informed by the results of a formative study, we propose three key design concepts to explore the systematic integration of intelligence into communication and collaboration, including the panel substrate, language-based intent recognition, and lightweight interaction techniques. We developed CrossTalk, a videoconferencing system that instantiates these concepts, which was found to enable a more fluid and flexible communication and collaboration experience.
Graphologue: Exploring Large Language Model Responses with Interactive Diagrams
May 19, 2023Large language models (LLMs) have recently soared in popularity due to their ease of access and the unprecedented intelligence exhibited on diverse applications. However, LLMs like ChatGPT present significant limitations in supporting complex information tasks due to the insufficient affordances of the text-based medium and linear conversational structure. Through a formative study with ten participants, we found that LLM interfaces often present long-winded responses, making it difficult for people to quickly comprehend and interact flexibly with various pieces of information, particularly during more complex tasks. We present Graphologue, an interactive system that converts text-based responses from LLMs into graphical diagrams to facilitate information-seeking and question-answering tasks. Graphologue employs novel prompting strategies and interface designs to extract entities and relationships from LLM responses and constructs node-link diagrams in real-time. Further, users can interact with the diagrams to flexibly adjust the graphical presentation and to submit context-specific prompts to obtain more information. Utilizing diagrams, Graphologue enables graphical, non-linear dialogues between humans and LLMs, facilitating information exploration, organization, and comprehension.