 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindTrellis: Co-Creating Knowledge Structures with AI through Interactive Visual Exploration
Apr 25, 2026Knowledge workers face increasing challenges in synthesizing information from multiple documents into structured conceptual understanding. This process is inherently iterative: users explore content, identify relationships between concepts, and continuously reorganize their mental models. However, current approaches offer limited support. LLM-based systems let users query information but not shape how knowledge is organized; manual tools like mind maps support structure creation but lack intelligent assistance. This leaves an open opportunity: supporting collaborative construction where users and AI jointly develop an evolving knowledge representation. We present MindTrellis, an interactive visual system where users and AI collaboratively build a dynamic knowledge graph. Users can query the graph to retrieve document-grounded information, and contribute by introducing new concepts, modifying relationships, and reorganizing the hierarchy to reflect their developing understanding. In a user study where 12 participants created slide decks, MindTrellis outperformed retrieval-only baselines in knowledge organization and cognitive load, as measured by expert ratings of content coverage and structural quality.
Athanor: Authoring Action Modification-based Interactions on Static Visualizations via Natural Language
Jan 25, 2026Interactivity is crucial for effective data visualizations. However, it is often challenging to implement interactions for existing static visualizations, since the underlying code and data for existing static visualizations are often not available, and it also takes significant time and effort to enable interactions for them even if the original code and data are available. To fill this gap, we propose Athanor, a novel approach to transform existing static visualizations into interactive ones using multimodal large language models (MLLMs) and natural language instructions. Our approach introduces three key innovations: (1) an action-modification interaction design space that maps visualization interactions into user actions and corresponding adjustments, (2) a multi-agent requirement analyzer that translates natural language instructions into an actionable operational space, and (3) a visualization abstraction transformer that converts static visualizations into flexible and interactive representations regardless of their underlying implementation. Athanor allows users to effortlessly author interactions through natural language instructions, eliminating the need for programming. We conducted two case studies and in-depth interviews with target users to evaluate our approach. The results demonstrate the effectiveness and usability of our approach in allowing users to conveniently enable flexible interactions for static visualizations.
Not Only Consistency: Enhance Test-Time Adaptation with Spatio-temporal Inconsistency for Remote Physiological Measurement
Jul 10, 2025Remote photoplethysmography (rPPG) has emerged as a promising non-invasive method for monitoring physiological signals using the camera. Although various domain adaptation and generalization methods were proposed to promote the adaptability of deep-based rPPG models in unseen deployment environments, considerations in aspects like privacy concerns and real-time adaptation restrict their application in real-world deployment. Thus, we aim to propose a novel fully Test-Time Adaptation (TTA) strategy tailored for rPPG tasks in this work. Specifically, based on prior knowledge in physiology and our observations, we noticed not only there is spatio-temporal consistency in the frequency domain of rPPG signals, but also that inconsistency in the time domain was significant. Given this, by leveraging both consistency and inconsistency priors, we introduce an innovative expert knowledge-based self-supervised \textbf{C}onsistency-\textbf{i}n\textbf{C}onsistency-\textbf{i}ntegration (\textbf{CiCi}) framework to enhances model adaptation during inference. Besides, our approach further incorporates a gradient dynamic control mechanism to mitigate potential conflicts between priors, ensuring stable adaptation across instances. Through extensive experiments on five diverse datasets under the TTA protocol, our method consistently outperforms existing techniques, presenting state-of-the-art performance in real-time self-supervised adaptation without accessing source data. The code will be released later.
Multimodal LLMs for Visualization Reconstruction and Understanding
Jun 26, 2025Visualizations are crucial for data communication, yet understanding them requires comprehension of both visual elements and their underlying data relationships. Current multimodal large models, while effective in natural image understanding, struggle with visualization due to their inability to decode the data-to-visual mapping rules and extract structured information. To address these challenges, we present a novel dataset and train multimodal visualization LLMs specifically designed for understanding. Our approach combines chart images with their corresponding vectorized representations, encoding schemes, and data features. The proposed vector format enables compact and accurate reconstruction of visualization content. Experimental results demonstrate significant improvements in both data extraction accuracy and chart reconstruction quality.
RAF-GI: Towards Robust, Accurate and Fast-Convergent Gradient Inversion Attack in Federated Learning
Mar 13, 2024Federated learning (FL) empowers privacy-preservation in model training by only exposing users' model gradients. Yet, FL users are susceptible to the gradient inversion (GI) attack which can reconstruct ground-truth training data such as images based on model gradients. However, reconstructing high-resolution images by existing GI attack works faces two challenges: inferior accuracy and slow-convergence, especially when the context is complicated, e.g., the training batch size is much greater than 1 on each FL user. To address these challenges, we present a Robust, Accurate and Fast-convergent GI attack algorithm, called RAF-GI, with two components: 1) Additional Convolution Block (ACB) which can restore labels with up to 20% improvement compared with existing works; 2) Total variance, three-channel mEan and cAnny edge detection regularization term (TEA), which is a white-box attack strategy to reconstruct images based on labels inferred by ACB. Moreover, RAF-GI is robust that can still accurately reconstruct ground-truth data when the users' training batch size is no more than 48. Our experimental results manifest that RAF-GI can diminish 94% time costs while achieving superb inversion quality in ImageNet dataset. Notably, with a batch size of 1, RAF-GI exhibits a 7.89 higher Peak Signal-to-Noise Ratio (PSNR) compared to the state-of-the-art baselines.
MGIC: A Multi-Label Gradient Inversion Attack based on Canny Edge Detection on Federated Learning
Mar 13, 2024As a new distributed computing framework that can protect data privacy, federated learning (FL) has attracted more and more attention in recent years. It receives gradients from users to train the global model and releases the trained global model to working users. Nonetheless, the gradient inversion (GI) attack reflects the risk of privacy leakage in federated learning. Attackers only need to use gradients through hundreds of thousands of simple iterations to obtain relatively accurate private data stored on users' local devices. For this, some works propose simple but effective strategies to obtain user data under a single-label dataset. However, these strategies induce a satisfactory visual effect of the inversion image at the expense of higher time costs. Due to the semantic limitation of a single label, the image obtained by gradient inversion may have semantic errors. We present a novel gradient inversion strategy based on canny edge detection (MGIC) in both the multi-label and single-label datasets. To reduce semantic errors caused by a single label, we add new convolution layers' blocks in the trained model to obtain the image's multi-label. Through multi-label representation, serious semantic errors in inversion images are reduced. Then, we analyze the impact of parameters on the difficulty of input image reconstruction and discuss how image multi-subjects affect the inversion performance. Our proposed strategy has better visual inversion image results than the most widely used ones, saving more than 78% of time costs in the ImageNet dataset.
1D-Touch: NLP-Assisted Coarse Text Selection via a Semi-Direct Gesture
Oct 26, 2023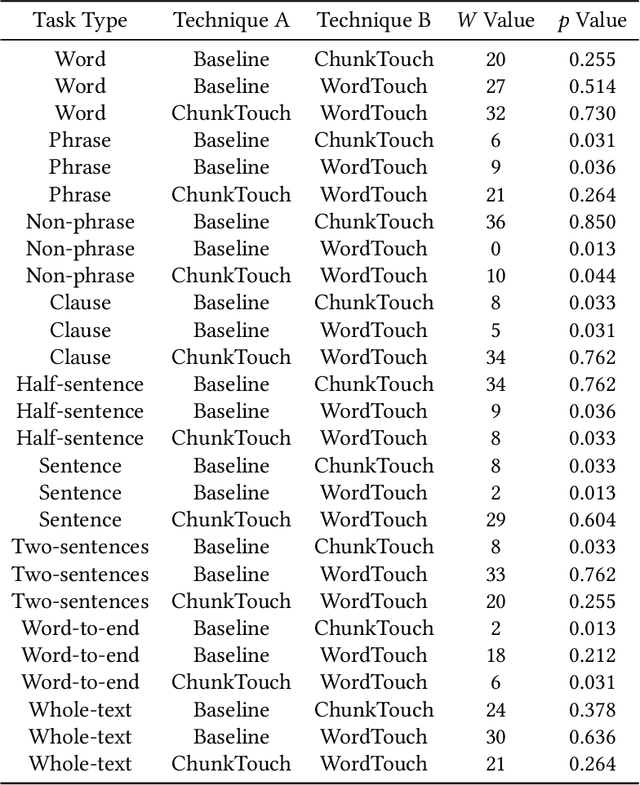



Existing text selection techniques on touchscreen focus on improving the control for moving the carets. Coarse-grained text selection on word and phrase levels has not received much support beyond word-snapping and entity recognition. We introduce 1D-Touch, a novel text selection method that complements the carets-based sub-word selection by facilitating the selection of semantic units of words and above. This method employs a simple vertical slide gesture to expand and contract a selection area from a word. The expansion can be by words or by semantic chunks ranging from sub-phrases to sentences. This technique shifts the concept of text selection, from defining a range by locating the first and last words, towards a dynamic process of expanding and contracting a textual semantic entity. To understand the effects of our approach, we prototyped and tested two variants: WordTouch, which offers a straightforward word-by-word expansion, and ChunkTouch, which leverages NLP to chunk text into syntactic units, allowing the selection to grow by semantically meaningful units in response to the sliding gesture. Our evaluation, focused on the coarse-grained selection tasks handled by 1D-Touch, shows a 20% improvement over the default word-snapping selection method on Android.
ONNXExplainer: an ONNX Based Generic Framework to Explain Neural Networks Using Shapley Values
Oct 03, 2023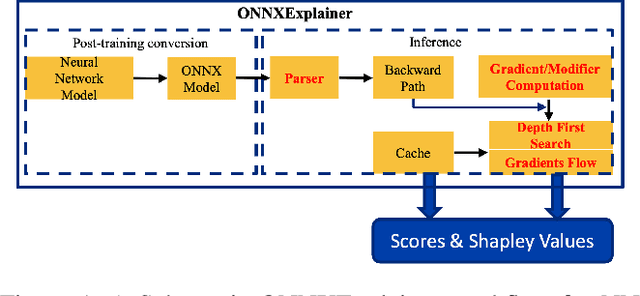
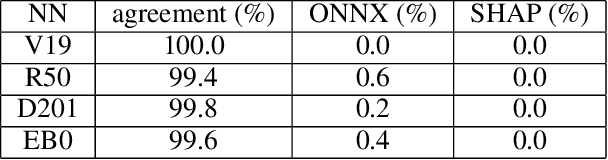

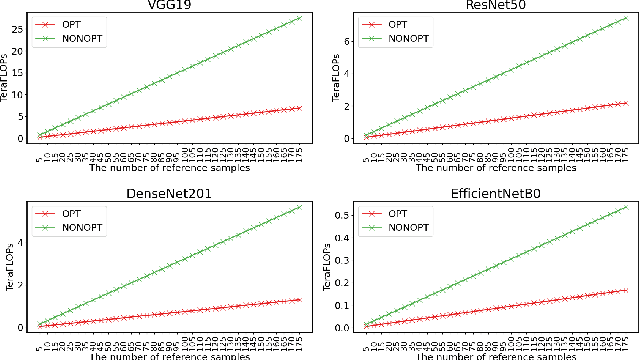
Understanding why a neural network model makes certain decisions can be as important as the inference performance. Various methods have been proposed to help practitioners explain the prediction of a neural network model, of which Shapley values are most popular. SHAP package is a leading implementation of Shapley values to explain neural networks implemented in TensorFlow or PyTorch but lacks cross-platform support, one-shot deployment and is highly inefficient. To address these problems, we present the ONNXExplainer, which is a generic framework to explain neural networks using Shapley values in the ONNX ecosystem. In ONNXExplainer, we develop its own automatic differentiation and optimization approach, which not only enables One-Shot Deployment of neural networks inference and explanations, but also significantly improves the efficiency to compute explanation with less memory consumption. For fair comparison purposes, we also implement the same optimization in TensorFlow and PyTorch and measure its performance against the current state of the art open-source counterpart, SHAP. Extensive benchmarks demonstrate that the proposed optimization approach improves the explanation latency of VGG19, ResNet50, DenseNet201, and EfficientNetB0 by as much as 500%.
On Conditional and Compositional Language Model Differentiable Prompting
Jul 04, 2023



Prompts have been shown to be an effective method to adapt a frozen Pretrained Language Model (PLM) to perform well on downstream tasks. Prompts can be represented by a human-engineered word sequence or by a learned continuous embedding. In this work, we investigate conditional and compositional differentiable prompting. We propose a new model, Prompt Production System (PRopS), which learns to transform task instructions or input metadata, into continuous prompts that elicit task-specific outputs from the PLM. Our model uses a modular network structure based on our neural formulation of Production Systems, which allows the model to learn discrete rules -- neural functions that learn to specialize in transforming particular prompt input patterns, making it suitable for compositional transfer learning and few-shot learning. We present extensive empirical and theoretical analysis and show that PRopS consistently surpasses other PLM adaptation techniques, and often improves upon fully fine-tuned models, on compositional generalization tasks, controllable summarization and multilingual translation, while needing fewer trainable parameters.
MedAug: Contrastive learning leveraging patient metadata improves representations for chest X-ray interpretation
Feb 21, 2021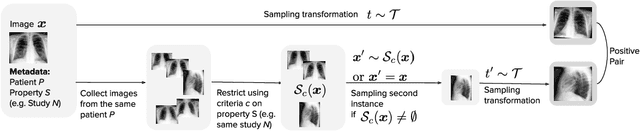
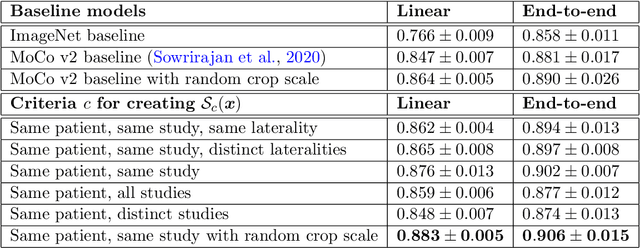

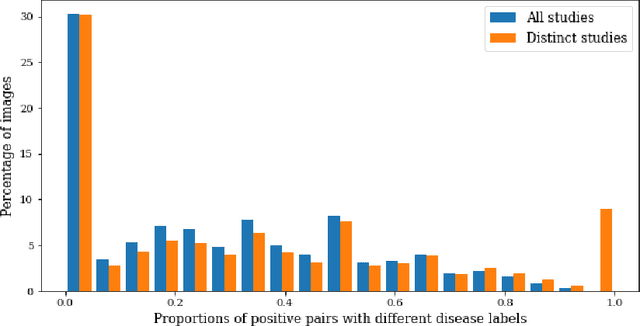
Self-supervised contrastive learning between pairs of multiple views of the same image has been shown to successfully leverage unlabeled data to produce meaningful visual representations for both natural and medical images. However, there has been limited work on determining how to select pairs for medical images, where availability of patient metadata can be leveraged to improve representations. In this work, we develop a method to select positive pairs coming from views of possibly different images through the use of patient metadata. We compare strategies for selecting positive pairs for chest X-ray interpretation including requiring them to be from the same patient, imaging study or laterality. We evaluate downstream task performance by fine-tuning the linear layer on 1% of the labeled dataset for pleural effusion classification. Our best performing positive pair selection strategy, which involves using images from the same patient from the same study across all lateralities, achieves a performance increase of 3.4% and 14.4% in mean AUC from both a previous contrastive method and ImageNet pretrained baseline respectively. Our controlled experiments show that the keys to improving downstream performance on disease classification are (1) using patient metadata to appropriately create positive pairs from different images with the same underlying pathologies, and (2) maximizing the number of different images used in query pairing. In addition, we explore leveraging patient metadata to select hard negative pairs for contrastive learning, but do not find improvement over baselines that do not use metadata. Our method is broadly applicable to medical image interpretation and allows flexibility for incorporating medical insights in choosing pairs for contrastive learning.