 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMDFNet: Efficient Multi-scale and Diverse Feature Network for Traffic Sign Detection
Aug 26, 2024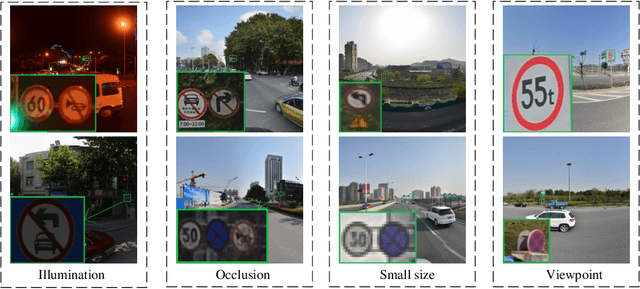
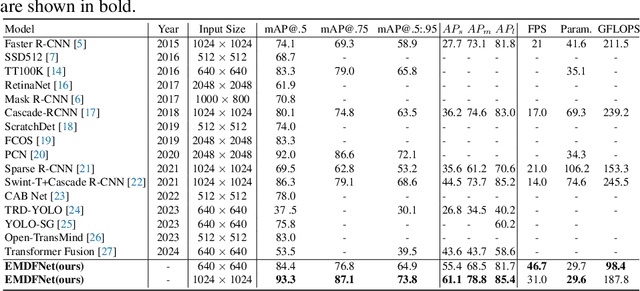
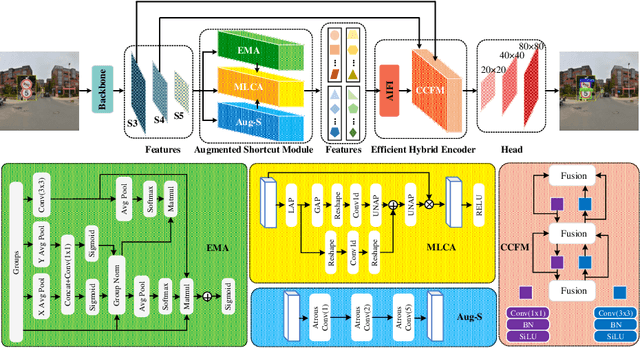
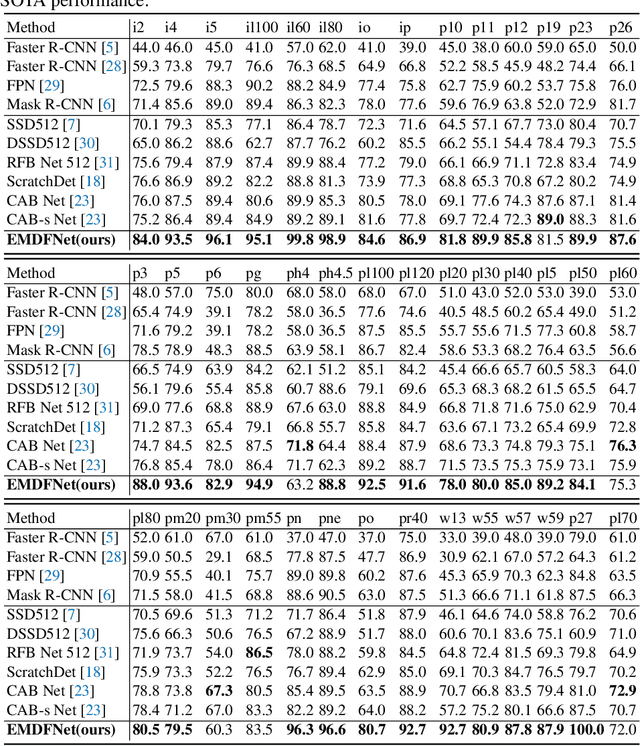
The detection of small objects, particularly traffic signs, is a critical subtask within object detection and autonomous driving. Despite the notable achievements in previous research, two primary challenges persist. Firstly, the main issue is the singleness of feature extraction. Secondly, the detection process fails to effectively integrate with objects of varying sizes or scales. These issues are also prevalent in generic object detection. Motivated by these challenges, in this paper, we propose a novel object detection network named Efficient Multi-scale and Diverse Feature Network (EMDFNet) for traffic sign detection that integrates an Augmented Shortcut Module and an Efficient Hybrid Encoder to address the aforementioned issues simultaneously. Specifically, the Augmented Shortcut Module utilizes multiple branches to integrate various spatial semantic information and channel semantic information, thereby enhancing feature diversity. The Efficient Hybrid Encoder utilizes global feature fusion and local feature interaction based on various features to generate distinctive classification features by integrating feature information in an adaptable manner. Extensive experiments on the Tsinghua-Tencent 100K (TT100K) benchmark and the German Traffic Sign Detection Benchmark (GTSDB) demonstrate that our EMDFNet outperforms other state-of-the-art detectors in performance while retaining the real-time processing capabilities of single-stage models. This substantiates the effectiveness of EMDFNet in detecting small traffic signs.
Generative Sentiment Analysis via Latent Category Distribution and Constrained Decoding
Jul 31, 2024Fine-grained sentiment analysis involves extracting and organizing sentiment elements from textual data. However, existing approaches often overlook issues of category semantic inclusion and overlap, as well as inherent structural patterns within the target sequence. This study introduces a generative sentiment analysis model. To address the challenges related to category semantic inclusion and overlap, a latent category distribution variable is introduced. By reconstructing the input of a variational autoencoder, the model learns the intensity of the relationship between categories and text, thereby improving sequence generation. Additionally, a trie data structure and constrained decoding strategy are utilized to exploit structural patterns, which in turn reduces the search space and regularizes the generation process. Experimental results on the Restaurant-ACOS and Laptop-ACOS datasets demonstrate a significant performance improvement compared to baseline models. Ablation experiments further confirm the effectiveness of latent category distribution and constrained decoding strategy.
RAF-GI: Towards Robust, Accurate and Fast-Convergent Gradient Inversion Attack in Federated Learning
Mar 13, 2024Federated learning (FL) empowers privacy-preservation in model training by only exposing users' model gradients. Yet, FL users are susceptible to the gradient inversion (GI) attack which can reconstruct ground-truth training data such as images based on model gradients. However, reconstructing high-resolution images by existing GI attack works faces two challenges: inferior accuracy and slow-convergence, especially when the context is complicated, e.g., the training batch size is much greater than 1 on each FL user. To address these challenges, we present a Robust, Accurate and Fast-convergent GI attack algorithm, called RAF-GI, with two components: 1) Additional Convolution Block (ACB) which can restore labels with up to 20% improvement compared with existing works; 2) Total variance, three-channel mEan and cAnny edge detection regularization term (TEA), which is a white-box attack strategy to reconstruct images based on labels inferred by ACB. Moreover, RAF-GI is robust that can still accurately reconstruct ground-truth data when the users' training batch size is no more than 48. Our experimental results manifest that RAF-GI can diminish 94% time costs while achieving superb inversion quality in ImageNet dataset. Notably, with a batch size of 1, RAF-GI exhibits a 7.89 higher Peak Signal-to-Noise Ratio (PSNR) compared to the state-of-the-art baselines.
MovePose: A High-performance Human Pose Estimation Algorithm on Mobile and Edge Devices
Aug 17, 2023



We present MovePose, an optimized lightweight convolutional neural network designed specifically for real-time body pose estimation on CPU-based mobile devices. The current solutions do not provide satisfactory accuracy and speed for human posture estimation, and MovePose addresses this gap. It aims to maintain real-time performance while improving the accuracy of human posture estimation for mobile devices. The network produces 17 keypoints for each individual at a rate exceeding 11 frames per second, making it suitable for real-time applications such as fitness tracking, sign language interpretation, and advanced mobile human posture estimation. Our MovePose algorithm has attained an Mean Average Precision (mAP) score of 67.7 on the COCO \cite{cocodata} validation dataset. The MovePose algorithm displayed efficiency with a performance of 69+ frames per second (fps) when run on an Intel i9-10920x CPU. Additionally, it showcased an increased performance of 452+ fps on an NVIDIA RTX3090 GPU. On an Android phone equipped with a Snapdragon 8 + 4G processor, the fps reached above 11. To enhance accuracy, we incorporated three techniques: deconvolution, large kernel convolution, and coordinate classification methods. Compared to basic upsampling, deconvolution is trainable, improves model capacity, and enhances the receptive field. Large kernel convolution strengthens these properties at a decreased computational cost. In summary, MovePose provides high accuracy and real-time performance, marking it a potential tool for a variety of applications, including those focused on mobile-side human posture estimation. The code and models for this algorithm will be made publicly accessible.
OmniDataComposer: A Unified Data Structure for Multimodal Data Fusion and Infinite Data Generation
Aug 17, 2023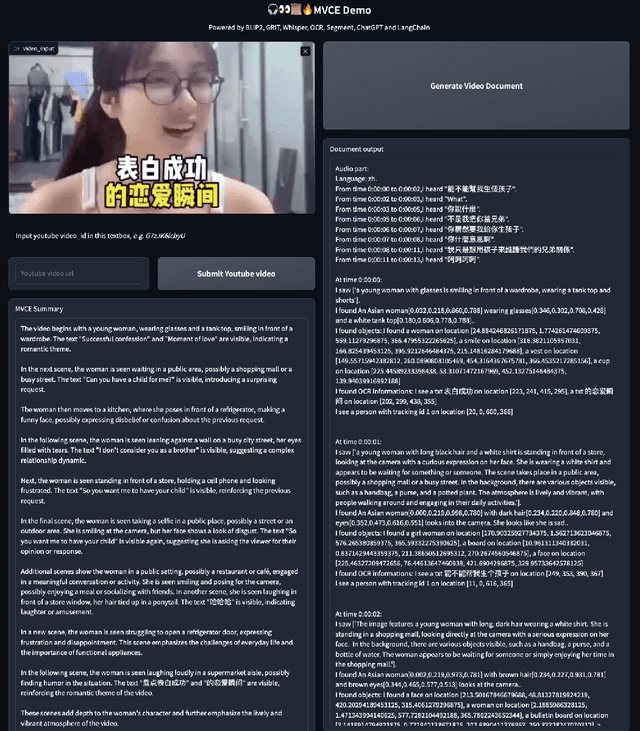

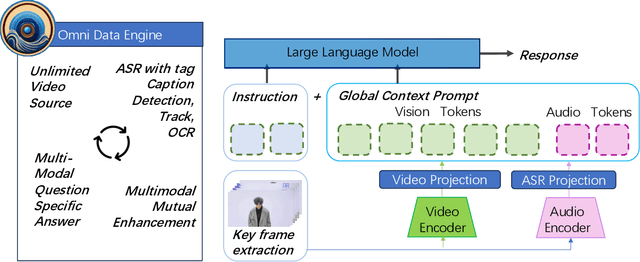

This paper presents OmniDataComposer, an innovative approach for multimodal data fusion and unlimited data generation with an intent to refine and uncomplicate interplay among diverse data modalities. Coming to the core breakthrough, it introduces a cohesive data structure proficient in processing and merging multimodal data inputs, which include video, audio, and text. Our crafted algorithm leverages advancements across multiple operations such as video/image caption extraction, dense caption extraction, Automatic Speech Recognition (ASR), Optical Character Recognition (OCR), Recognize Anything Model(RAM), and object tracking. OmniDataComposer is capable of identifying over 6400 categories of objects, substantially broadening the spectrum of visual information. It amalgamates these diverse modalities, promoting reciprocal enhancement among modalities and facilitating cross-modal data correction. \textbf{The final output metamorphoses each video input into an elaborate sequential document}, virtually transmuting videos into thorough narratives, making them easier to be processed by large language models. Future prospects include optimizing datasets for each modality to encourage unlimited data generation. This robust base will offer priceless insights to models like ChatGPT, enabling them to create higher quality datasets for video captioning and easing question-answering tasks based on video content. OmniDataComposer inaugurates a new stage in multimodal learning, imparting enormous potential for augmenting AI's understanding and generation of complex, real-world data.
Joint Coordinate Regression and Association For Multi-Person Pose Estimation, A Pure Neural Network Approach
Jul 03, 2023We introduce a novel one-stage end-to-end multi-person 2D pose estimation algorithm, known as Joint Coordinate Regression and Association (JCRA), that produces human pose joints and associations without requiring any post-processing. The proposed algorithm is fast, accurate, effective, and simple. The one-stage end-to-end network architecture significantly improves the inference speed of JCRA. Meanwhile, we devised a symmetric network structure for both the encoder and decoder, which ensures high accuracy in identifying keypoints. It follows an architecture that directly outputs part positions via a transformer network, resulting in a significant improvement in performance. Extensive experiments on the MS COCO and CrowdPose benchmarks demonstrate that JCRA outperforms state-of-the-art approaches in both accuracy and efficiency. Moreover, JCRA demonstrates 69.2 mAP and is 78\% faster at inference acceleration than previous state-of-the-art bottom-up algorithms. The code for this algorithm will be publicly available.