 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-Pose: Enhancing Human Pose and Action Understanding via Keypoint-Integrated Instruction Tuning
Jun 26, 2025Current vision-language models (VLMs) are well-adapted for general visual understanding tasks. However, they perform inadequately when handling complex visual tasks related to human poses and actions due to the lack of specialized vision-language instruction-following data. We introduce a method for generating such data by integrating human keypoints with traditional visual features such as captions and bounding boxes, enabling more precise understanding of human-centric scenes. Our approach constructs a dataset comprising 200,328 samples tailored to fine-tune models for human-centric tasks, focusing on three areas: conversation, detailed description, and complex reasoning. We establish an Extended Human Pose and Action Understanding Benchmark (E-HPAUB) to assess model performance on human pose and action understanding. We fine-tune the LLaVA-1.5-7B model using this dataset and evaluate our resulting LLaVA-Pose model on the benchmark, achieving significant improvements. Experimental results show an overall improvement of 33.2% compared to the original LLaVA-1.5-7B model. These findings highlight the effectiveness of keypoint-integrated data in enhancing multimodal models for human-centric visual understanding. Code is available at https://github.com/Ody-trek/LLaVA-Pose.
Keypoints-Integrated Instruction-Following Data Generation for Enhanced Human Pose Understanding in Multimodal Models
Sep 14, 2024Current multimodal models are well-suited for general visual understanding tasks. However, they perform inadequately when handling complex visual tasks related to human poses and actions, primarily due to the lack of specialized instruction-following data. We introduce a new method for generating such data by integrating human keypoints with traditional visual features like captions and bounding boxes. Our approach produces datasets designed for fine-tuning models to excel in human-centric activities, focusing on three specific types: conversation, detailed description, and complex reasoning. We fine-tuned the LLaVA-7B model with this novel dataset, achieving significant improvements across various human pose-related tasks. Experimental results show an overall improvement of 21.18% compared to the original LLaVA-7B model. These findings demonstrate the effectiveness of keypoints-assisted data in enhancing multimodal models.
MovePose: A High-performance Human Pose Estimation Algorithm on Mobile and Edge Devices
Aug 17, 2023



We present MovePose, an optimized lightweight convolutional neural network designed specifically for real-time body pose estimation on CPU-based mobile devices. The current solutions do not provide satisfactory accuracy and speed for human posture estimation, and MovePose addresses this gap. It aims to maintain real-time performance while improving the accuracy of human posture estimation for mobile devices. The network produces 17 keypoints for each individual at a rate exceeding 11 frames per second, making it suitable for real-time applications such as fitness tracking, sign language interpretation, and advanced mobile human posture estimation. Our MovePose algorithm has attained an Mean Average Precision (mAP) score of 67.7 on the COCO \cite{cocodata} validation dataset. The MovePose algorithm displayed efficiency with a performance of 69+ frames per second (fps) when run on an Intel i9-10920x CPU. Additionally, it showcased an increased performance of 452+ fps on an NVIDIA RTX3090 GPU. On an Android phone equipped with a Snapdragon 8 + 4G processor, the fps reached above 11. To enhance accuracy, we incorporated three techniques: deconvolution, large kernel convolution, and coordinate classification methods. Compared to basic upsampling, deconvolution is trainable, improves model capacity, and enhances the receptive field. Large kernel convolution strengthens these properties at a decreased computational cost. In summary, MovePose provides high accuracy and real-time performance, marking it a potential tool for a variety of applications, including those focused on mobile-side human posture estimation. The code and models for this algorithm will be made publicly accessible.
OmniDataComposer: A Unified Data Structure for Multimodal Data Fusion and Infinite Data Generation
Aug 17, 2023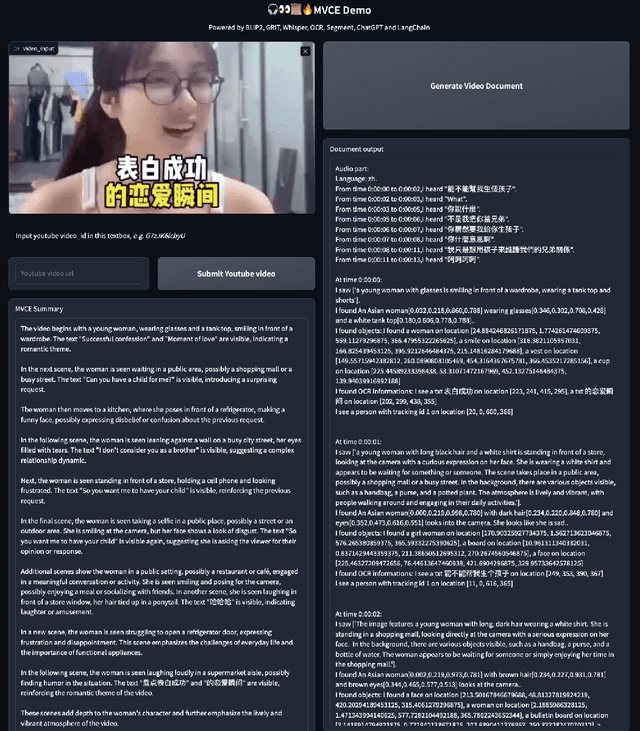

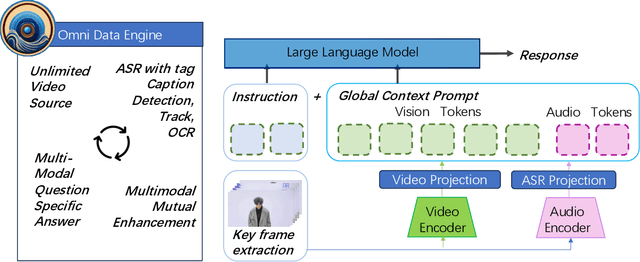

This paper presents OmniDataComposer, an innovative approach for multimodal data fusion and unlimited data generation with an intent to refine and uncomplicate interplay among diverse data modalities. Coming to the core breakthrough, it introduces a cohesive data structure proficient in processing and merging multimodal data inputs, which include video, audio, and text. Our crafted algorithm leverages advancements across multiple operations such as video/image caption extraction, dense caption extraction, Automatic Speech Recognition (ASR), Optical Character Recognition (OCR), Recognize Anything Model(RAM), and object tracking. OmniDataComposer is capable of identifying over 6400 categories of objects, substantially broadening the spectrum of visual information. It amalgamates these diverse modalities, promoting reciprocal enhancement among modalities and facilitating cross-modal data correction. \textbf{The final output metamorphoses each video input into an elaborate sequential document}, virtually transmuting videos into thorough narratives, making them easier to be processed by large language models. Future prospects include optimizing datasets for each modality to encourage unlimited data generation. This robust base will offer priceless insights to models like ChatGPT, enabling them to create higher quality datasets for video captioning and easing question-answering tasks based on video content. OmniDataComposer inaugurates a new stage in multimodal learning, imparting enormous potential for augmenting AI's understanding and generation of complex, real-world data.
Joint Coordinate Regression and Association For Multi-Person Pose Estimation, A Pure Neural Network Approach
Jul 03, 2023We introduce a novel one-stage end-to-end multi-person 2D pose estimation algorithm, known as Joint Coordinate Regression and Association (JCRA), that produces human pose joints and associations without requiring any post-processing. The proposed algorithm is fast, accurate, effective, and simple. The one-stage end-to-end network architecture significantly improves the inference speed of JCRA. Meanwhile, we devised a symmetric network structure for both the encoder and decoder, which ensures high accuracy in identifying keypoints. It follows an architecture that directly outputs part positions via a transformer network, resulting in a significant improvement in performance. Extensive experiments on the MS COCO and CrowdPose benchmarks demonstrate that JCRA outperforms state-of-the-art approaches in both accuracy and efficiency. Moreover, JCRA demonstrates 69.2 mAP and is 78\% faster at inference acceleration than previous state-of-the-art bottom-up algorithms. The code for this algorithm will be publicly available.
Parameter-Free Channel Attention for Image Classification and Super-Resolution
Mar 20, 2023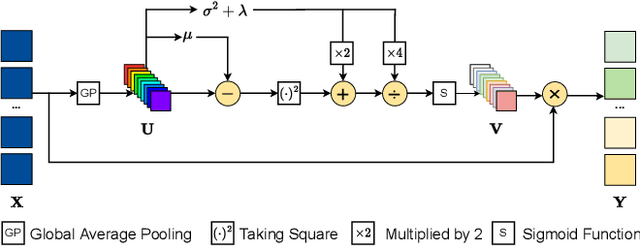
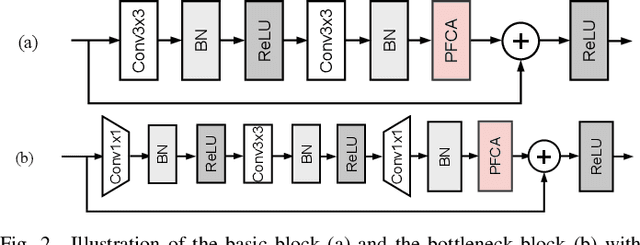
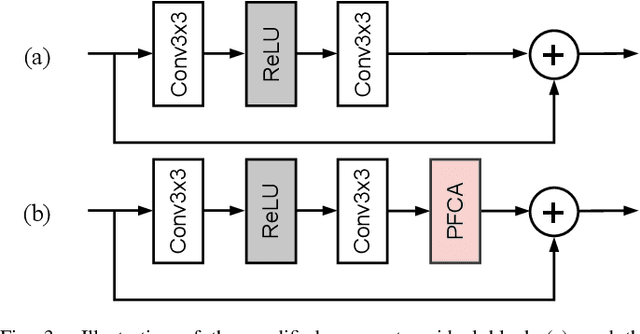
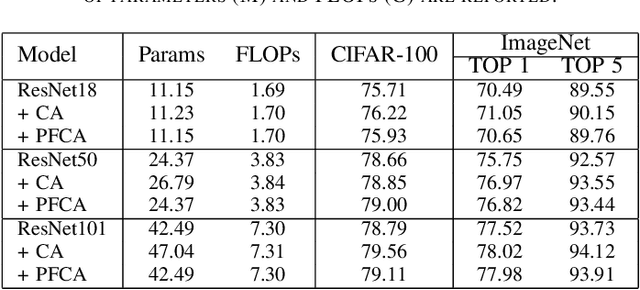
The channel attention mechanism is a useful technique widely employed in deep convolutional neural networks to boost the performance for image processing tasks, eg, image classification and image super-resolution. It is usually designed as a parameterized sub-network and embedded into the convolutional layers of the network to learn more powerful feature representations. However, current channel attention induces more parameters and therefore leads to higher computational costs. To deal with this issue, in this work, we propose a Parameter-Free Channel Attention (PFCA) module to boost the performance of popular image classification and image super-resolution networks, but completely sweep out the parameter growth of channel attention. Experiments on CIFAR-100, ImageNet, and DIV2K validate that our PFCA module improves the performance of ResNet on image classification and improves the performance of MSRResNet on image super-resolution tasks, respectively, while bringing little growth of parameters and FLOPs.
Non-negative Sparse and Collaborative Representation for Pattern Classification
Aug 29, 2019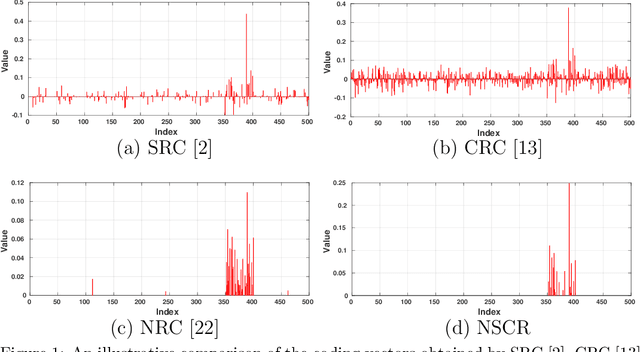

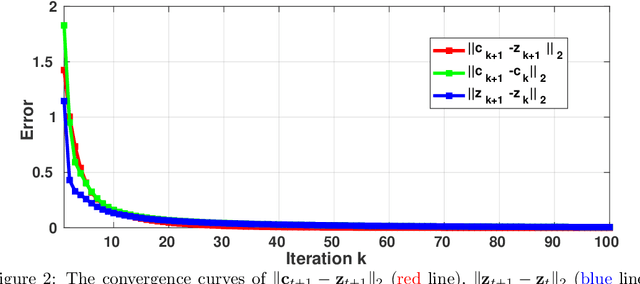

Sparse representation (SR) and collaborative representation (CR) have been successfully applied in many pattern classification tasks such as face recognition. In this paper, we propose a novel Non-negative Sparse and Collaborative Representation (NSCR) for pattern classification. The NSCR representation of each test sample is obtained by seeking a non-negative sparse and collaborative representation vector that represents the test sample as a linear combination of training samples. We observe that the non-negativity can make the SR and CR more discriminative and effective for pattern classification. Based on the proposed NSCR, we propose a NSCR based classifier for pattern classification. Extensive experiments on benchmark datasets demonstrate that the proposed NSCR based classifier outperforms the previous SR or CR based approach, as well as state-of-the-art deep approaches, on diverse challenging pattern classification tasks.
Semi-Supervised Self-Growing Generative Adversarial Networks for Image Recognition
Aug 11, 2019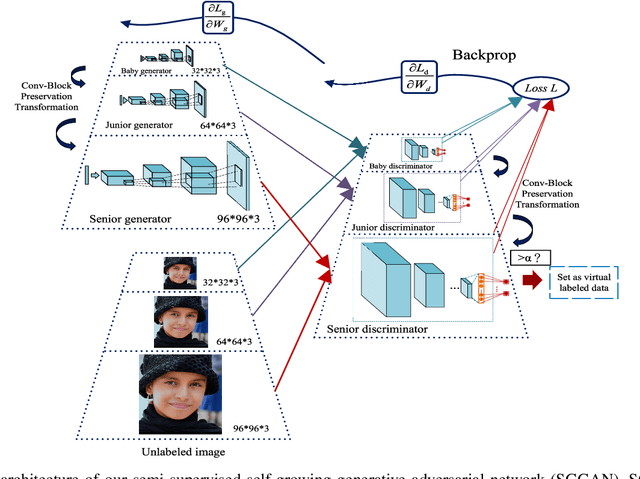
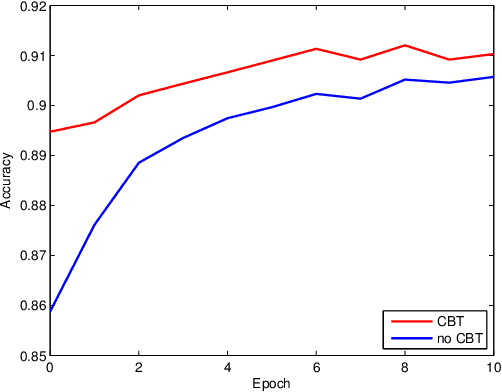

Image recognition is an important topic in computer vision and image processing, and has been mainly addressed by supervised deep learning methods, which need a large set of labeled images to achieve promising performance. However, in most cases, labeled data are expensive or even impossible to obtain, while unlabeled data are readily available from numerous free on-line resources and have been exploited to improve the performance of deep neural networks. To better exploit the power of unlabeled data for image recognition, in this paper, we propose a semi-supervised and generative approach, namely the semi-supervised self-growing generative adversarial network (SGGAN). Label inference is a key step for the success of semi-supervised learning approaches. There are two main problems in label inference: how to measure the confidence of the unlabeled data and how to generalize the classifier. We address these two problems via the generative framework and a novel convolution-block-transformation technique, respectively. To stabilize and speed up the training process of SGGAN, we employ the metric Maximum Mean Discrepancy as the feature matching objective function and achieve larger gain than the standard semi-supervised GANs (SSGANs), narrowing the gap to the supervised methods. Experiments on several benchmark datasets show the effectiveness of the proposed SGGAN on image recognition and facial attribute recognition tasks. By using the training data with only 4% labeled facial attributes, the SGGAN approach can achieve comparable accuracy with leading supervised deep learning methods with all labeled facial attributes.