 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaTPT: Meta Test-time Prompt Tuning for Vision-Language Models
Dec 13, 2025Vision-language models (VLMs) such as CLIP exhibit strong zero-shot generalization but remain sensitive to domain shifts at test time. Test-time prompt tuning (TPT) mitigates this issue by adapting prompts with fixed augmentations, which may falter in more challenging settings. In this work, we propose Meta Test-Time Prompt Tuning (MetaTPT), a meta-learning framework that learns a self-supervised auxiliary task to guide test-time prompt tuning. The auxiliary task dynamically learns parameterized augmentations for each sample, enabling more expressive transformations that capture essential features in target domains. MetaTPT adopts a dual-loop optimization paradigm: an inner loop learns a self-supervised task that generates informative views, while the outer loop performs prompt tuning by enforcing consistency across these views. By coupling augmentation learning with prompt tuning, MetaTPT improves test-time adaptation under domain shifts. Extensive experiments demonstrate that MetaTPT achieves state-of-the-art performance on domain generalization and cross-dataset benchmarks.
Surf3R: Rapid Surface Reconstruction from Sparse RGB Views in Seconds
Aug 06, 2025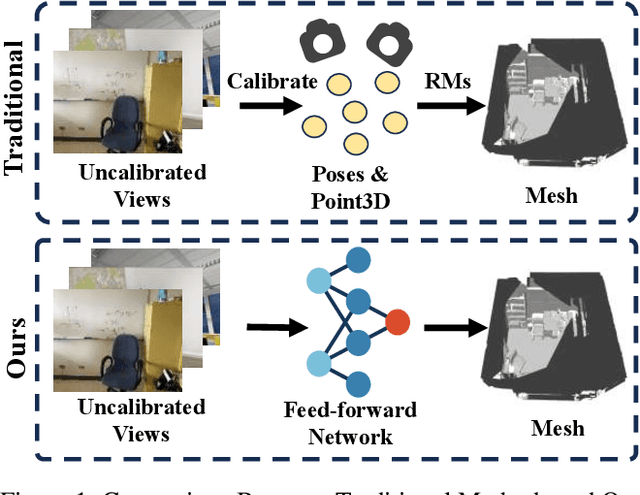
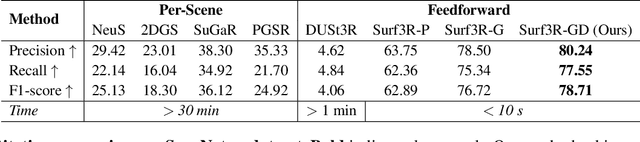
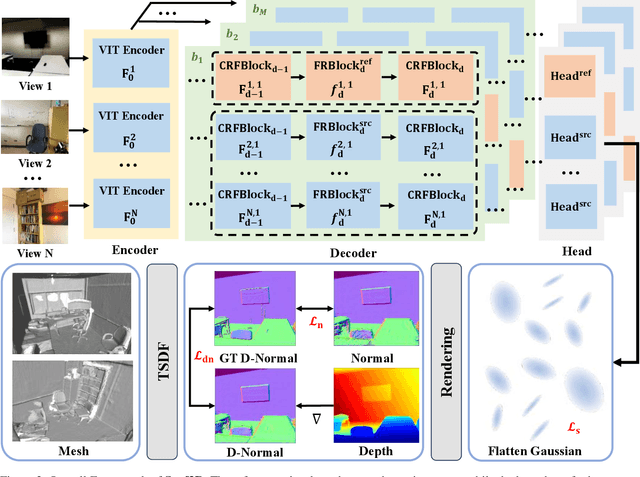

Current multi-view 3D reconstruction methods rely on accurate camera calibration and pose estimation, requiring complex and time-intensive pre-processing that hinders their practical deployment. To address this challenge, we introduce Surf3R, an end-to-end feedforward approach that reconstructs 3D surfaces from sparse views without estimating camera poses and completes an entire scene in under 10 seconds. Our method employs a multi-branch and multi-view decoding architecture in which multiple reference views jointly guide the reconstruction process. Through the proposed branch-wise processing, cross-view attention, and inter-branch fusion, the model effectively captures complementary geometric cues without requiring camera calibration. Moreover, we introduce a D-Normal regularizer based on an explicit 3D Gaussian representation for surface reconstruction. It couples surface normals with other geometric parameters to jointly optimize the 3D geometry, significantly improving 3D consistency and surface detail accuracy. Experimental results demonstrate that Surf3R achieves state-of-the-art performance on multiple surface reconstruction metrics on ScanNet++ and Replica datasets, exhibiting excellent generalization and efficiency.
Few-Shot Referring Video Single- and Multi-Object Segmentation via Cross-Modal Affinity with Instance Sequence Matching
Apr 18, 2025Referring video object segmentation (RVOS) aims to segment objects in videos guided by natural language descriptions. We propose FS-RVOS, a Transformer-based model with two key components: a cross-modal affinity module and an instance sequence matching strategy, which extends FS-RVOS to multi-object segmentation (FS-RVMOS). Experiments show FS-RVOS and FS-RVMOS outperform state-of-the-art methods across diverse benchmarks, demonstrating superior robustness and accuracy.
Self-Supervised Scene Flow Estimation with Point-Voxel Fusion and Surface Representation
Oct 17, 2024



Scene flow estimation aims to generate the 3D motion field of points between two consecutive frames of point clouds, which has wide applications in various fields. Existing point-based methods ignore the irregularity of point clouds and have difficulty capturing long-range dependencies due to the inefficiency of point-level computation. Voxel-based methods suffer from the loss of detail information. In this paper, we propose a point-voxel fusion method, where we utilize a voxel branch based on sparse grid attention and the shifted window strategy to capture long-range dependencies and a point branch to capture fine-grained features to compensate for the information loss in the voxel branch. In addition, since xyz coordinates are difficult to describe the geometric structure of complex 3D objects in the scene, we explicitly encode the local surface information of the point cloud through the umbrella surface feature extraction (USFE) module. We verify the effectiveness of our method by conducting experiments on the Flyingthings3D and KITTI datasets. Our method outperforms all other self-supervised methods and achieves highly competitive results compared to fully supervised methods. We achieve improvements in all metrics, especially EPE, which is reduced by 8.51% and 10.52% on the KITTIo and KITTIs datasets, respectively.
LKASeg:Remote-Sensing Image Semantic Segmentation with Large Kernel Attention and Full-Scale Skip Connections
Oct 14, 2024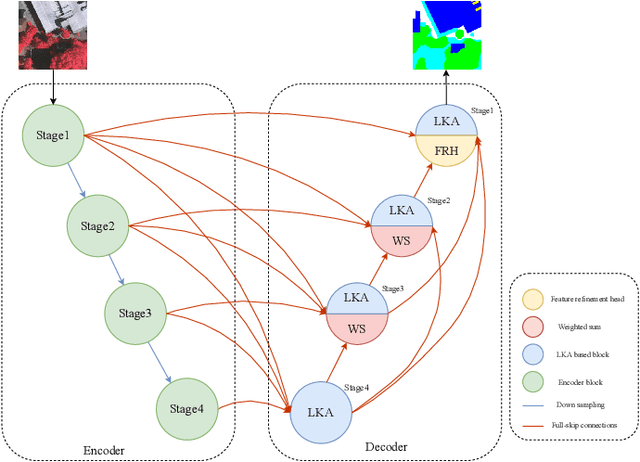



Semantic segmentation of remote sensing images is a fundamental task in geospatial research. However, widely used Convolutional Neural Networks (CNNs) and Transformers have notable drawbacks: CNNs may be limited by insufficient remote sensing modeling capability, while Transformers face challenges due to computational complexity. In this paper, we propose a remote-sensing image semantic segmentation network named LKASeg, which combines Large Kernel Attention(LSKA) and Full-Scale Skip Connections(FSC). Specifically, we propose a decoder based on Large Kernel Attention (LKA), which extract global features while avoiding the computational overhead of self-attention and providing channel adaptability. To achieve full-scale feature learning and fusion, we apply Full-Scale Skip Connections (FSC) between the encoder and decoder. We conducted experiments by combining the LKA-based decoder with FSC. On the ISPRS Vaihingen dataset, the mF1 and mIoU scores achieved 90.33% and 82.77%.
LKA-ReID:Vehicle Re-Identification with Large Kernel Attention
Sep 26, 2024With the rapid development of intelligent transportation systems and the popularity of smart city infrastructure, Vehicle Re-ID technology has become an important research field. The vehicle Re-ID task faces an important challenge, which is the high similarity between different vehicles. Existing methods use additional detection or segmentation models to extract differentiated local features. However, these methods either rely on additional annotations or greatly increase the computational cost. Using attention mechanism to capture global and local features is crucial to solve the challenge of high similarity between classes in vehicle Re-ID tasks. In this paper, we propose LKA-ReID with large kernel attention. Specifically, the large kernel attention (LKA) utilizes the advantages of self-attention and also benefits from the advantages of convolution, which can extract the global and local features of the vehicle more comprehensively. We also introduce hybrid channel attention (HCA) combines channel attention with spatial information, so that the model can better focus on channels and feature regions, and ignore background and other disturbing information. Experiments on VeRi-776 dataset demonstrated the effectiveness of LKA-ReID, with mAP reaches 86.65% and Rank-1 reaches 98.03%.
Reconstruct Spine CT from Biplanar X-Rays via Diffusion Learning
Aug 21, 2024

Intraoperative CT imaging serves as a crucial resource for surgical guidance; however, it may not always be readily accessible or practical to implement. In scenarios where CT imaging is not an option, reconstructing CT scans from X-rays can offer a viable alternative. In this paper, we introduce an innovative method for 3D CT reconstruction utilizing biplanar X-rays. Distinct from previous research that relies on conventional image generation techniques, our approach leverages a conditional diffusion process to tackle the task of reconstruction. More precisely, we employ a diffusion-based probabilistic model trained to produce 3D CT images based on orthogonal biplanar X-rays. To improve the structural integrity of the reconstructed images, we incorporate a novel projection loss function. Experimental results validate that our proposed method surpasses existing state-of-the-art benchmarks in both visual image quality and multiple evaluative metrics. Specifically, our technique achieves a higher Structural Similarity Index (SSIM) of 0.83, a relative increase of 10\%, and a lower Fr\'echet Inception Distance (FID) of 83.43, which represents a relative decrease of 25\%.
HYDEN: Hyperbolic Density Representations for Medical Images and Reports
Aug 20, 2024In light of the inherent entailment relations between images and text, hyperbolic point vector embeddings, leveraging the hierarchical modeling advantages of hyperbolic space, have been utilized for visual semantic representation learning. However, point vector embedding approaches fail to address the issue of semantic uncertainty, where an image may have multiple interpretations, and text may refer to different images, a phenomenon particularly prevalent in the medical domain. Therefor, we propose \textbf{HYDEN}, a novel hyperbolic density embedding based image-text representation learning approach tailored for specific medical domain data. This method integrates text-aware local features alongside global features from images, mapping image-text features to density features in hyperbolic space via using hyperbolic pseudo-Gaussian distributions. An encapsulation loss function is employed to model the partial order relations between image-text density distributions. Experimental results demonstrate the interpretability of our approach and its superior performance compared to the baseline methods across various zero-shot tasks and different datasets.
Coarse-Fine View Attention Alignment-Based GAN for CT Reconstruction from Biplanar X-Rays
Aug 19, 2024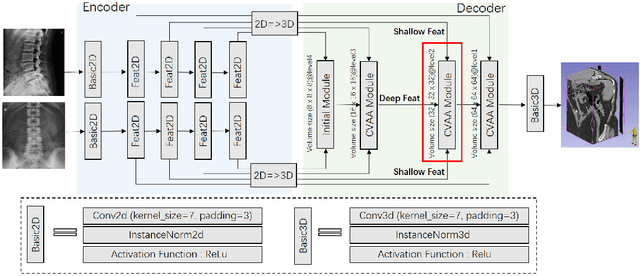
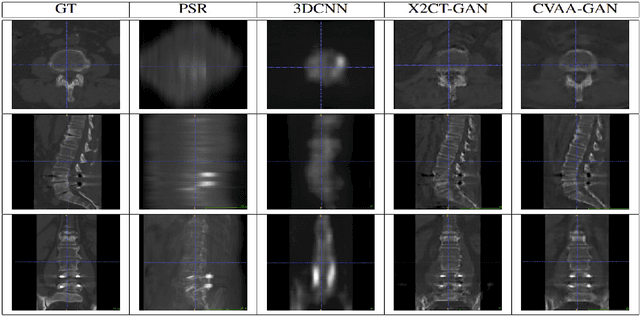

For surgical planning and intra-operation imaging, CT reconstruction using X-ray images can potentially be an important alternative when CT imaging is not available or not feasible. In this paper, we aim to use biplanar X-rays to reconstruct a 3D CT image, because biplanar X-rays convey richer information than single-view X-rays and are more commonly used by surgeons. Different from previous studies in which the two X-ray views were treated indifferently when fusing the cross-view data, we propose a novel attention-informed coarse-to-fine cross-view fusion method to combine the features extracted from the orthogonal biplanar views. This method consists of a view attention alignment sub-module and a fine-distillation sub-module that are designed to work together to highlight the unique or complementary information from each of the views. Experiments have demonstrated the superiority of our proposed method over the SOTA methods.
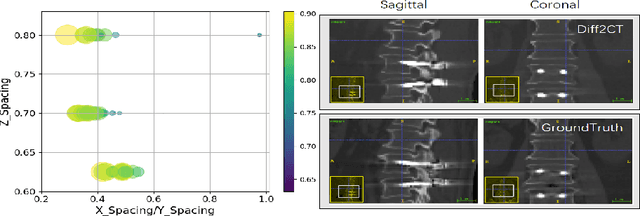
DiffuX2CT: Diffusion Learning to Reconstruct CT Images from Biplanar X-Rays
Jul 18, 2024

Computed tomography (CT) is widely utilized in clinical settings because it delivers detailed 3D images of the human body. However, performing CT scans is not always feasible due to radiation exposure and limitations in certain surgical environments. As an alternative, reconstructing CT images from ultra-sparse X-rays offers a valuable solution and has gained significant interest in scientific research and medical applications. However, it presents great challenges as it is inherently an ill-posed problem, often compromised by artifacts resulting from overlapping structures in X-ray images. In this paper, we propose DiffuX2CT, which models CT reconstruction from orthogonal biplanar X-rays as a conditional diffusion process. DiffuX2CT is established with a 3D global coherence denoising model with a new, implicit conditioning mechanism. We realize the conditioning mechanism by a newly designed tri-plane decoupling generator and an implicit neural decoder. By doing so, DiffuX2CT achieves structure-controllable reconstruction, which enables 3D structural information to be recovered from 2D X-rays, therefore producing faithful textures in CT images. As an extra contribution, we collect a real-world lumbar CT dataset, called LumbarV, as a new benchmark to verify the clinical significance and performance of CT reconstruction from X-rays. Extensive experiments on this dataset and three more publicly available datasets demonstrate the effectiveness of our proposal.