 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Scene Flow Estimation with Point-Voxel Fusion and Surface Representation
Oct 17, 2024



Scene flow estimation aims to generate the 3D motion field of points between two consecutive frames of point clouds, which has wide applications in various fields. Existing point-based methods ignore the irregularity of point clouds and have difficulty capturing long-range dependencies due to the inefficiency of point-level computation. Voxel-based methods suffer from the loss of detail information. In this paper, we propose a point-voxel fusion method, where we utilize a voxel branch based on sparse grid attention and the shifted window strategy to capture long-range dependencies and a point branch to capture fine-grained features to compensate for the information loss in the voxel branch. In addition, since xyz coordinates are difficult to describe the geometric structure of complex 3D objects in the scene, we explicitly encode the local surface information of the point cloud through the umbrella surface feature extraction (USFE) module. We verify the effectiveness of our method by conducting experiments on the Flyingthings3D and KITTI datasets. Our method outperforms all other self-supervised methods and achieves highly competitive results compared to fully supervised methods. We achieve improvements in all metrics, especially EPE, which is reduced by 8.51% and 10.52% on the KITTIo and KITTIs datasets, respectively.
LKASeg:Remote-Sensing Image Semantic Segmentation with Large Kernel Attention and Full-Scale Skip Connections
Oct 14, 2024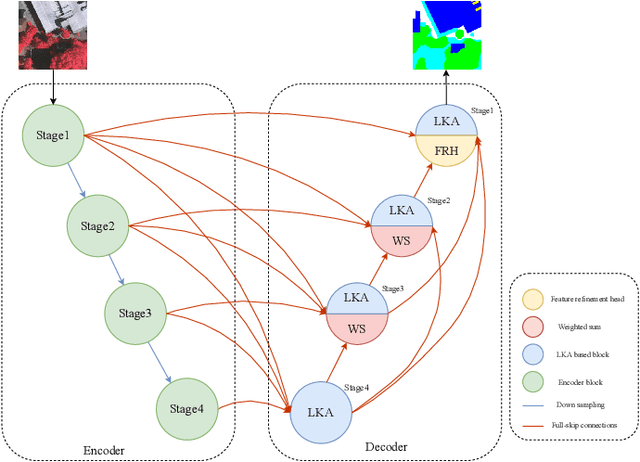



Semantic segmentation of remote sensing images is a fundamental task in geospatial research. However, widely used Convolutional Neural Networks (CNNs) and Transformers have notable drawbacks: CNNs may be limited by insufficient remote sensing modeling capability, while Transformers face challenges due to computational complexity. In this paper, we propose a remote-sensing image semantic segmentation network named LKASeg, which combines Large Kernel Attention(LSKA) and Full-Scale Skip Connections(FSC). Specifically, we propose a decoder based on Large Kernel Attention (LKA), which extract global features while avoiding the computational overhead of self-attention and providing channel adaptability. To achieve full-scale feature learning and fusion, we apply Full-Scale Skip Connections (FSC) between the encoder and decoder. We conducted experiments by combining the LKA-based decoder with FSC. On the ISPRS Vaihingen dataset, the mF1 and mIoU scores achieved 90.33% and 82.77%.
LKA-ReID:Vehicle Re-Identification with Large Kernel Attention
Sep 26, 2024With the rapid development of intelligent transportation systems and the popularity of smart city infrastructure, Vehicle Re-ID technology has become an important research field. The vehicle Re-ID task faces an important challenge, which is the high similarity between different vehicles. Existing methods use additional detection or segmentation models to extract differentiated local features. However, these methods either rely on additional annotations or greatly increase the computational cost. Using attention mechanism to capture global and local features is crucial to solve the challenge of high similarity between classes in vehicle Re-ID tasks. In this paper, we propose LKA-ReID with large kernel attention. Specifically, the large kernel attention (LKA) utilizes the advantages of self-attention and also benefits from the advantages of convolution, which can extract the global and local features of the vehicle more comprehensively. We also introduce hybrid channel attention (HCA) combines channel attention with spatial information, so that the model can better focus on channels and feature regions, and ignore background and other disturbing information. Experiments on VeRi-776 dataset demonstrated the effectiveness of LKA-ReID, with mAP reaches 86.65% and Rank-1 reaches 98.03%.