 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited Reasoning Space: The cage of long-horizon reasoning in LLMs
Feb 22, 2026The test-time compute strategy, such as Chain-of-Thought (CoT), has significantly enhanced the ability of large language models to solve complex tasks like logical reasoning. However, empirical studies indicate that simply increasing the compute budget can sometimes lead to a collapse in test-time performance when employing typical task decomposition strategies such as CoT. This work hypothesizes that reasoning failures with larger compute budgets stem from static planning methods, which hardly perceive the intrinsic boundaries of LLM reasoning. We term it as the Limited Reasoning Space hypothesis and perform theoretical analysis through the lens of a non-autonomous stochastic dynamical system. This insight suggests that there is an optimal range for compute budgets; over-planning can lead to redundant feedback and may even impair reasoning capabilities. To exploit the compute-scaling benefits and suppress over-planning, this work proposes Halo, a model predictive control framework for LLM planning. Halo is designed for long-horizon tasks with reason-based planning and crafts an entropy-driven dual controller, which adopts a Measure-then-Plan strategy to achieve controllable reasoning. Experimental results demonstrate that Halo outperforms static baselines on complex long-horizon tasks by dynamically regulating planning at the reasoning boundary.
Enhancing Generative Auto-bidding with Offline Reward Evaluation and Policy Search
Sep 19, 2025Auto-bidding is an essential tool for advertisers to enhance their advertising performance. Recent progress has shown that AI-Generated Bidding (AIGB), which formulates the auto-bidding as a trajectory generation task and trains a conditional diffusion-based planner on offline data, achieves superior and stable performance compared to typical offline reinforcement learning (RL)-based auto-bidding methods. However, existing AIGB methods still encounter a performance bottleneck due to their neglect of fine-grained generation quality evaluation and inability to explore beyond static datasets. To address this, we propose AIGB-Pearl (\emph{Planning with EvAluator via RL}), a novel method that integrates generative planning and policy optimization. The key to AIGB-Pearl is to construct a non-bootstrapped \emph{trajectory evaluator} to assign rewards and guide policy search, enabling the planner to optimize its generation quality iteratively through interaction. Furthermore, to enhance trajectory evaluator accuracy in offline settings, we incorporate three key techniques: (i) a Large Language Model (LLM)-based architecture for better representational capacity, (ii) hybrid point-wise and pair-wise losses for better score learning, and (iii) adaptive integration of expert feedback for better generalization ability. Extensive experiments on both simulated and real-world advertising systems demonstrate the state-of-the-art performance of our approach.
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning
Dec 15, 2024



Reinforcement learning (RL) often encounters delayed and sparse feedback in real-world applications, even with only episodic rewards. Previous approaches have made some progress in reward redistribution for credit assignment but still face challenges, including training difficulties due to redundancy and ambiguous attributions stemming from overlooking the multifaceted nature of mission performance evaluation. Hopefully, Large Language Model (LLM) encompasses fruitful decision-making knowledge and provides a plausible tool for reward redistribution. Even so, deploying LLM in this case is non-trivial due to the misalignment between linguistic knowledge and the symbolic form requirement, together with inherent randomness and hallucinations in inference. To tackle these issues, we introduce LaRe, a novel LLM-empowered symbolic-based decision-making framework, to improve credit assignment. Key to LaRe is the concept of the Latent Reward, which works as a multi-dimensional performance evaluation, enabling more interpretable goal attainment from various perspectives and facilitating more effective reward redistribution. We examine that semantically generated code from LLM can bridge linguistic knowledge and symbolic latent rewards, as it is executable for symbolic objects. Meanwhile, we design latent reward self-verification to increase the stability and reliability of LLM inference. Theoretically, reward-irrelevant redundancy elimination in the latent reward benefits RL performance from more accurate reward estimation. Extensive experimental results witness that LaRe (i) achieves superior temporal credit assignment to SOTA methods, (ii) excels in allocating contributions among multiple agents, and (iii) outperforms policies trained with ground truth rewards for certain tasks.
Choices are More Important than Efforts: LLM Enables Efficient Multi-Agent Exploration
Oct 03, 2024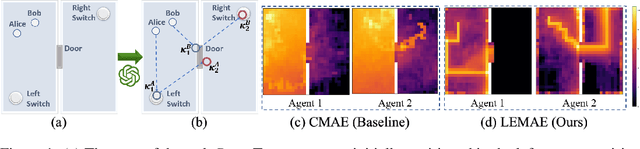

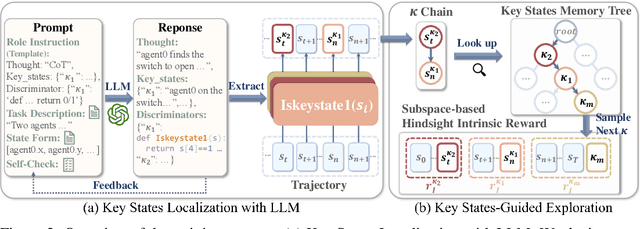
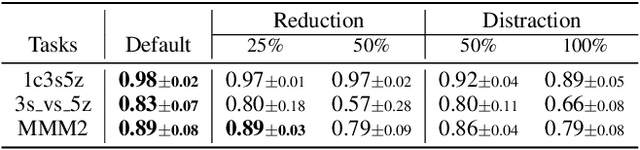
With expansive state-action spaces, efficient multi-agent exploration remains a longstanding challenge in reinforcement learning. Although pursuing novelty, diversity, or uncertainty attracts increasing attention, redundant efforts brought by exploration without proper guidance choices poses a practical issue for the community. This paper introduces a systematic approach, termed LEMAE, choosing to channel informative task-relevant guidance from a knowledgeable Large Language Model (LLM) for Efficient Multi-Agent Exploration. Specifically, we ground linguistic knowledge from LLM into symbolic key states, that are critical for task fulfillment, in a discriminative manner at low LLM inference costs. To unleash the power of key states, we design Subspace-based Hindsight Intrinsic Reward (SHIR) to guide agents toward key states by increasing reward density. Additionally, we build the Key State Memory Tree (KSMT) to track transitions between key states in a specific task for organized exploration. Benefiting from diminishing redundant explorations, LEMAE outperforms existing SOTA approaches on the challenging benchmarks (e.g., SMAC and MPE) by a large margin, achieving a 10x acceleration in certain scenarios.
Robust Fast Adaptation from Adversarially Explicit Task Distribution Generation
Jul 28, 2024



Meta-learning is a practical learning paradigm to transfer skills across tasks from a few examples. Nevertheless, the existence of task distribution shifts tends to weaken meta-learners' generalization capability, particularly when the task distribution is naively hand-crafted or based on simple priors that fail to cover typical scenarios sufficiently. Here, we consider explicitly generative modeling task distributions placed over task identifiers and propose robustifying fast adaptation from adversarial training. Our approach, which can be interpreted as a model of a Stackelberg game, not only uncovers the task structure during problem-solving from an explicit generative model but also theoretically increases the adaptation robustness in worst cases. This work has practical implications, particularly in dealing with task distribution shifts in meta-learning, and contributes to theoretical insights in the field. Our method demonstrates its robustness in the presence of task subpopulation shifts and improved performance over SOTA baselines in extensive experiments. The project is available at https://sites.google.com/view/ar-metalearn.
Reducing Fine-Tuning Memory Overhead by Approximate and Memory-Sharing Backpropagation
Jun 24, 2024



Fine-tuning pretrained large models to downstream tasks is an important problem, which however suffers from huge memory overhead due to large-scale parameters. This work strives to reduce memory overhead in fine-tuning from perspectives of activation function and layer normalization. To this end, we propose the Approximate Backpropagation (Approx-BP) theory, which provides the theoretical feasibility of decoupling the forward and backward passes. We apply our Approx-BP theory to backpropagation training and derive memory-efficient alternatives of GELU and SiLU activation functions, which use derivative functions of ReLUs in the backward pass while keeping their forward pass unchanged. In addition, we introduce a Memory-Sharing Backpropagation strategy, which enables the activation memory to be shared by two adjacent layers, thereby removing activation memory usage redundancy. Our method neither induces extra computation nor reduces training efficiency. We conduct extensive experiments with pretrained vision and language models, and the results demonstrate that our proposal can reduce up to $\sim$$30\%$ of the peak memory usage. Our code is released at https://github.com/yyyyychen/LowMemoryBP.
GO4Align: Group Optimization for Multi-Task Alignment
Apr 09, 2024



This paper proposes \textit{GO4Align}, a multi-task optimization approach that tackles task imbalance by explicitly aligning the optimization across tasks. To achieve this, we design an adaptive group risk minimization strategy, compromising two crucial techniques in implementation: (i) dynamical group assignment, which clusters similar tasks based on task interactions; (ii) risk-guided group indicators, which exploit consistent task correlations with risk information from previous iterations. Comprehensive experimental results on diverse typical benchmarks demonstrate our method's performance superiority with even lower computational costs.