 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection vs. Execution: Single-Bucket Probes Miss Half the Mamba-2 State Sink
May 30, 2026Mechanistic interpretability often assumes that probes identifying a representational signature also identify the circuit executing the corresponding computation. We show that this assumption can fail systematically in Mamba-2. Studying the state sink (disproportionate Delta-gate activation on boundary tokens, analogous to the attention sink), we find that single-bucket probes recover only a small execution layer while missing a much larger detection layer with the same representational signature. In Mamba-2, the state sink decomposes into two functional head sets. Single-bucket BOS-specialist heads (about 5% of heads at 2.7B) causally support both BOS-context and newline-target predictions across model scales and corpora. Dual heads (27-35% of heads, recovered by multi-class aggregation of the same probe) show stronger BOS-newline representational similarity but substantially weaker causal effects under ablation. Representational similarity does not imply functional equivalence. This distinction matters for downstream behaviour: ablating BOS-specialist heads collapses RULER NIAH retrieval accuracy from 1.00 to 0.00 at 1024 context length in both Mamba-1 2.8B and Mamba-2 2.7B, while size-matched complements preserve baseline performance. A random channel-bucketing control rules out substrate granularity alone, implicating Mamba-2's head-shared Delta projection. Probe-derived specialty can identify execution circuits; at coarse granularity the same probe also recovers detection circuits, and separating them requires class-conditional ablation rather than class-conditional cosine.
Task Structure Reverses Layerwise State Encoding in Sequence Models
May 30, 2026Mechanistic studies of sequence models often treat layerwise state encodings as architectural traits: recurrent models concentrate readable state, attention-based models distribute it. We find that the same architecture reverses this profile when the task changes. Across Transformers, Mamba, Mamba-2, LSTMs, and GRUs, Parity is concentrated late in Mamba and the recurrent baselines and built gradually by Transformer; on bounded-depth Dyck-k the pattern flips. The same flip appears in fine-tuned Mamba-130M and Pythia-160M, and the Pythia Dyck bottleneck persists at 410M. Two explanations are conflated in the literature: algebraic structure (commutativity) versus computational structure (prefix update vs. stack). To separate them we add a third task: non-commutative S_3 permutation composition. S_3 groups with Parity, not Dyck, on layerwise probing across all five architectures and on Mamba-specific Conv1D attribution, so the grouping tracks computational structure rather than commutativity. Causal interventions show that, in the 4-layer formal models, linearly readable directions are often functionally necessary and can remain important at out-of-distribution lengths on Parity and Dyck. At pretrained scale the picture splits. Fine-tuned Pythia Dyck has a strong middle-layer bottleneck (L6-L7 ablation drops accuracy by roughly 81% at 160M; broader L4-L18 plateau at 410M), far weaker at the best-probe layer. Pretrained Mamba shows the complementary failure mode: its final layer is highly readable, no single probe direction breaks the task on Parity, Dyck, or S_3, yet mid-position activation patching there recovers about 97-98% of the clean-corrupted logit gap. Probing localizes where state is linearly available, not always where the computation is bottlenecked. Mechanistic signatures are properties of architecture and task together.
PInVerify: An Offline Embodied Benchmark for Active Instance Verification
May 28, 2026Embodied agents have made strong progress in navigating to target objects, but reaching the goal vicinity does not guarantee that the agent has found the correct instance: subtle attribute differences (e.g., "white floral" vs. "white striped") often require close-range, multi-view inspection. We address this gap with Active Instance Verification (AIV), a task in which an agent actively selects viewpoints around a candidate object to decide whether it matches a fine-grained natural-language description. We formalize AIV as a finite-horizon decision process and introduce PInVerify, an offline embodied benchmark for AIV: 3,000 evaluation episodes across 18 object categories, delivered as multi-view captures with a 6-sector navigation topology that exposes trap views (navigable but uninformative) and unreachable sectors. As reference baselines we build a training-free pipeline and a LoRA-fine-tuned end-to-end agent around open-source multimodal large language models (MLLMs) at on-device scale ($\leq$8B parameters), with attribute decomposition, a visibility-weighted multi-view tracker, and three next-best-view (NBV) strategies. In our evaluation across Qwen3-VL (4B/8B), SenseNova-SI-1.2-InternVL3-8B, CLIP, and SigLIP2, the best MLLM-based baseline exceeds the best embedding baseline by 4.9 pp; GT-box ablations show a +3.1 pp detection gap; and we do not observe reliable gains from active viewpoint selection within the tested NBV strategies. A LoRA-fine-tuned agent (SFT+GSPO) reaches 85.6%. PInVerify aims to support further work on active, fine-grained semantic verification in embodied AI. Code: https://github.com/Avalon-S/PInVerify.
Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
May 07, 2026Reinforcement learning with verifiable rewards (RLVR) has become a standard approach for large language models (LLMs) post-training to incentivize reasoning capacity. Among existing recipes, group-based policy gradient is prevalent, which samples a group of responses per prompt and updates the policy via group-relative advantage signals. This work reveals that these optimization strategies share a common geometric structure: each implicitly defines a target distribution on the response simplex and projects toward it via first-order approximation. Building on this insight, we propose Listwise Policy Optimization (LPO) to explicitly conduct the target-projection, which demystifies the implicit target by restricting the proximal RL objective to the response simplex, and then projects the policy via exact divergence minimization. This framework provides (i) monotonic improvement on the listwise objective with bounded, zero-sum, and self-correcting projection gradients, and (ii) flexibility in divergence selection with distinct structural properties through the decoupled projection step. On diverse reasoning tasks and LLM backbones, LPO consistently improves training performance over typical policy gradient baselines under matched targets, while intrinsically preserving optimization stability and response diversity.
Closing Reasoning Gaps in Clinical Agents with Differential Reasoning Learning
Feb 10, 2026Clinical decision support requires not only correct answers but also clinically valid reasoning. We propose Differential Reasoning Learning (DRL), a framework that improves clinical agents by learning from reasoning discrepancies. From reference reasoning rationales (e.g., physician-authored clinical rationale, clinical guidelines, or outputs from more capable models) and the agent's free-form chain-of-thought (CoT), DRL extracts reasoning graphs as directed acyclic graphs (DAGs) and performs a clinically weighted graph edit distance (GED)-based discrepancy analysis. An LLM-as-a-judge aligns semantically equivalent nodes and diagnoses discrepancies between graphs. These graph-level discrepancy diagnostics are converted into natural-language instructions and stored in a Differential Reasoning Knowledge Base (DR-KB). At inference, we retrieve top-$k$ instructions via Retrieval-Augmented Generation (RAG) to augment the agent prompt and patch likely logic gaps. Evaluation on open medical question answering (QA) benchmarks and a Return Visit Admissions (RVA) prediction task from internal clinical data demonstrates gains over baselines, improving both final-answer accuracy and reasoning fidelity. Ablation studies confirm gains from infusing reference reasoning rationales and the top-$k$ retrieval strategy. Clinicians' review of the output provides further assurance of the approach. Together, results suggest that DRL supports more reliable clinical decision-making in complex reasoning scenarios and offers a practical mechanism for deployment under limited token budgets.
Small Generalizable Prompt Predictive Models Can Steer Efficient RL Post-Training of Large Reasoning Models
Feb 02, 2026Reinforcement learning enhances the reasoning capabilities of large language models but often involves high computational costs due to rollout-intensive optimization. Online prompt selection presents a plausible solution by prioritizing informative prompts to improve training efficiency. However, current methods either depend on costly, exact evaluations or construct prompt-specific predictive models lacking generalization across prompts. This study introduces Generalizable Predictive Prompt Selection (GPS), which performs Bayesian inference towards prompt difficulty using a lightweight generative model trained on the shared optimization history. Intermediate-difficulty prioritization and history-anchored diversity are incorporated into the batch acquisition principle to select informative prompt batches. The small predictive model also generalizes at test-time for efficient computational allocation. Experiments across varied reasoning benchmarks indicate GPS's substantial improvements in training efficiency, final performance, and test-time efficiency over superior baseline methods.
Unsupervised Data Generation for Offline Reinforcement Learning: A Perspective from Model
Jun 24, 2025Offline reinforcement learning (RL) recently gains growing interests from RL researchers. However, the performance of offline RL suffers from the out-of-distribution problem, which can be corrected by feedback in online RL. Previous offline RL research focuses on restricting the offline algorithm in in-distribution even in-sample action sampling. In contrast, fewer work pays attention to the influence of the batch data. In this paper, we first build a bridge over the batch data and the performance of offline RL algorithms theoretically, from the perspective of model-based offline RL optimization. We draw a conclusion that, with mild assumptions, the distance between the state-action pair distribution generated by the behavioural policy and the distribution generated by the optimal policy, accounts for the performance gap between the policy learned by model-based offline RL and the optimal policy. Secondly, we reveal that in task-agnostic settings, a series of policies trained by unsupervised RL can minimize the worst-case regret in the performance gap. Inspired by the theoretical conclusions, UDG (Unsupervised Data Generation) is devised to generate data and select proper data for offline training under tasks-agnostic settings. Empirical results demonstrate that UDG can outperform supervised data generation on solving unknown tasks.
A Benchmark for End-to-End Zero-Shot Biomedical Relation Extraction with LLMs: Experiments with OpenAI Models
Apr 05, 2025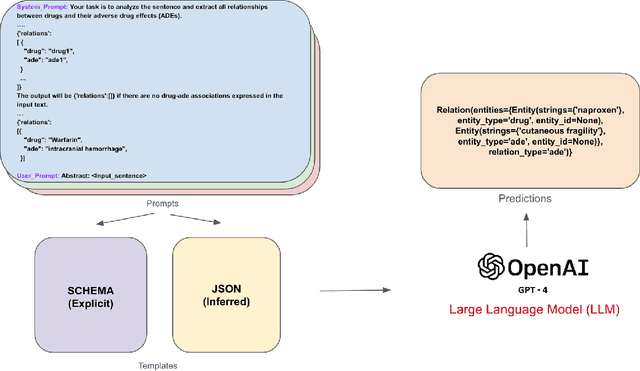
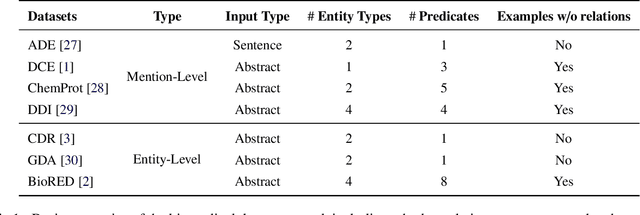
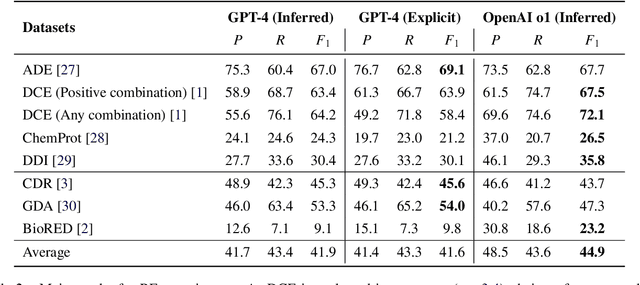
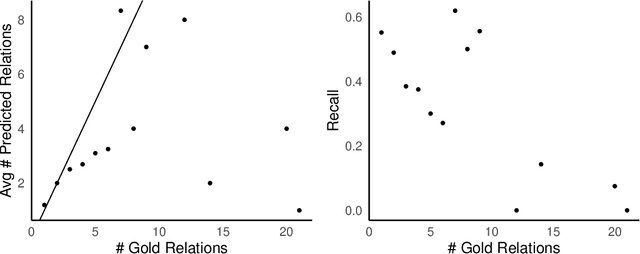
Objective: Zero-shot methodology promises to cut down on costs of dataset annotation and domain expertise needed to make use of NLP. Generative large language models trained to align with human goals have achieved high zero-shot performance across a wide variety of tasks. As of yet, it is unclear how well these models perform on biomedical relation extraction (RE). To address this knowledge gap, we explore patterns in the performance of OpenAI LLMs across a diverse sampling of RE tasks. Methods: We use OpenAI GPT-4-turbo and their reasoning model o1 to conduct end-to-end RE experiments on seven datasets. We use the JSON generation capabilities of GPT models to generate structured output in two ways: (1) by defining an explicit schema describing the structure of relations, and (2) using a setting that infers the structure from the prompt language. Results: Our work is the first to study and compare the performance of the GPT-4 and o1 for the end-to-end zero-shot biomedical RE task across a broad array of datasets. We found the zero-shot performances to be proximal to that of fine-tuned methods. The limitations of this approach are that it performs poorly on instances containing many relations and errs on the boundaries of textual mentions. Conclusion: Recent large language models exhibit promising zero-shot capabilities in complex biomedical RE tasks, offering competitive performance with reduced dataset curation and NLP modeling needs at the cost of increased computing, potentially increasing medical community accessibility. Addressing the limitations we identify could further boost reliability. The code, data, and prompts for all our experiments are publicly available: https://github.com/bionlproc/ZeroShotRE
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning
Dec 15, 2024



Reinforcement learning (RL) often encounters delayed and sparse feedback in real-world applications, even with only episodic rewards. Previous approaches have made some progress in reward redistribution for credit assignment but still face challenges, including training difficulties due to redundancy and ambiguous attributions stemming from overlooking the multifaceted nature of mission performance evaluation. Hopefully, Large Language Model (LLM) encompasses fruitful decision-making knowledge and provides a plausible tool for reward redistribution. Even so, deploying LLM in this case is non-trivial due to the misalignment between linguistic knowledge and the symbolic form requirement, together with inherent randomness and hallucinations in inference. To tackle these issues, we introduce LaRe, a novel LLM-empowered symbolic-based decision-making framework, to improve credit assignment. Key to LaRe is the concept of the Latent Reward, which works as a multi-dimensional performance evaluation, enabling more interpretable goal attainment from various perspectives and facilitating more effective reward redistribution. We examine that semantically generated code from LLM can bridge linguistic knowledge and symbolic latent rewards, as it is executable for symbolic objects. Meanwhile, we design latent reward self-verification to increase the stability and reliability of LLM inference. Theoretically, reward-irrelevant redundancy elimination in the latent reward benefits RL performance from more accurate reward estimation. Extensive experimental results witness that LaRe (i) achieves superior temporal credit assignment to SOTA methods, (ii) excels in allocating contributions among multiple agents, and (iii) outperforms policies trained with ground truth rewards for certain tasks.
Can ChatGPT Overcome Behavioral Biases in the Financial Sector? Classify-and-Rethink: Multi-Step Zero-Shot Reasoning in the Gold Investment
Nov 19, 2024



Large Language Models (LLMs) have achieved remarkable success recently, displaying exceptional capabilities in creating understandable and organized text. These LLMs have been utilized in diverse fields, such as clinical research, where domain-specific models like Med-Palm have achieved human-level performance. Recently, researchers have employed advanced prompt engineering to enhance the general reasoning ability of LLMs. Despite the remarkable success of zero-shot Chain-of-Thoughts (CoT) in solving general reasoning tasks, the potential of these methods still remains paid limited attention in the financial reasoning task.To address this issue, we explore multiple prompt strategies and incorporated semantic news information to improve LLMs' performance on financial reasoning tasks.To the best of our knowledge, we are the first to explore this important issue by applying ChatGPT to the gold investment.In this work, our aim is to investigate the financial reasoning capabilities of LLMs and their capacity to generate logical and persuasive investment opinions. We will use ChatGPT, one of the most powerful LLMs recently, and prompt engineering to achieve this goal. Our research will focus on understanding the ability of LLMs in sophisticated analysis and reasoning within the context of investment decision-making. Our study finds that ChatGPT with CoT prompt can provide more explainable predictions and overcome behavioral biases, which is crucial in finance-related tasks and can achieve higher investment returns.