 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan ChatGPT Overcome Behavioral Biases in the Financial Sector? Classify-and-Rethink: Multi-Step Zero-Shot Reasoning in the Gold Investment
Nov 19, 2024



Large Language Models (LLMs) have achieved remarkable success recently, displaying exceptional capabilities in creating understandable and organized text. These LLMs have been utilized in diverse fields, such as clinical research, where domain-specific models like Med-Palm have achieved human-level performance. Recently, researchers have employed advanced prompt engineering to enhance the general reasoning ability of LLMs. Despite the remarkable success of zero-shot Chain-of-Thoughts (CoT) in solving general reasoning tasks, the potential of these methods still remains paid limited attention in the financial reasoning task.To address this issue, we explore multiple prompt strategies and incorporated semantic news information to improve LLMs' performance on financial reasoning tasks.To the best of our knowledge, we are the first to explore this important issue by applying ChatGPT to the gold investment.In this work, our aim is to investigate the financial reasoning capabilities of LLMs and their capacity to generate logical and persuasive investment opinions. We will use ChatGPT, one of the most powerful LLMs recently, and prompt engineering to achieve this goal. Our research will focus on understanding the ability of LLMs in sophisticated analysis and reasoning within the context of investment decision-making. Our study finds that ChatGPT with CoT prompt can provide more explainable predictions and overcome behavioral biases, which is crucial in finance-related tasks and can achieve higher investment returns.
Self-Paced Video Data Augmentation with Dynamic Images Generated by Generative Adversarial Networks
Sep 16, 2019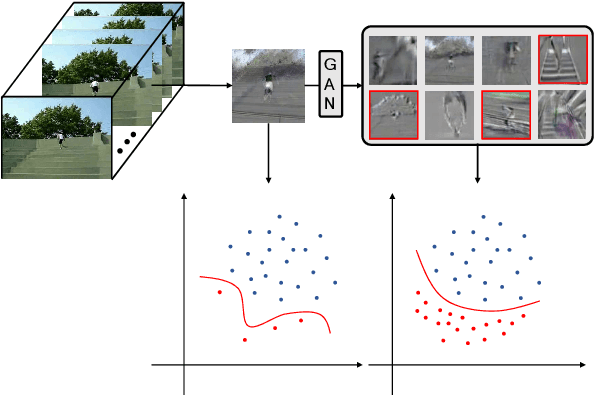

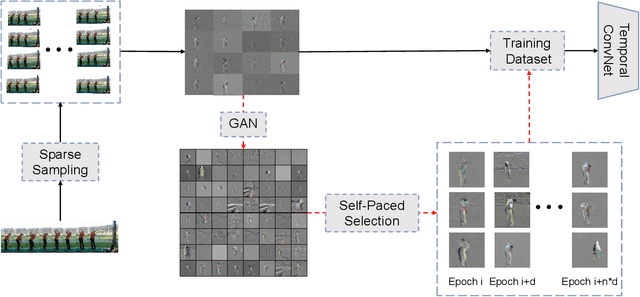
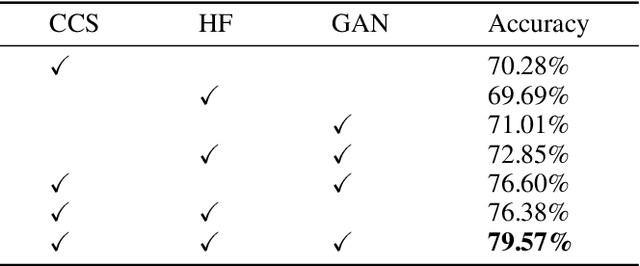
There is an urgent need for an effective video classification method by means of a small number of samples. The deficiency of samples could be effectively alleviated by generating samples through Generative Adversarial Networks (GAN), but the generation of videos on a typical category remains to be underexplored since the complex actions and the changeable viewpoints are difficult to simulate. In this paper, we propose a generative data augmentation method for temporal stream of the Temporal Segment Networks with the dynamic image. The dynamic image compresses the motion information of video into a still image, removing the interference factors such as the background. Thus it is easier to generate images with categorical motion information using GAN. We use the generated dynamic images to enhance the features, with regularization achieved as well, thereby to achieve the effect of video augmentation. In order to deal with the uneven quality of generated images, we propose a Self-Paced Selection (SPS) method, which automatically selects the high-quality generated samples to be added to the network training. Our method is verified on two benchmark datasets, HMDB51 and UCF101. The experimental results show that the method can improve the accuracy of video classification under the circumstance of sample insufficiency and sample imbalance.